学习笔记-AIGC全栈认知与落地(11)
第11章 · 行业实践地图——大模型在各领域怎么落地
开场:同一行代码,在不同行业里的“冰火两重天”
在 AIGC 的技术聚光灯下,人们很容易产生一种技术平权的错觉:“既然都是调用 GPT-4 接口,在金融公司做分析,和在学校里改作文,底层的技术不都差不多吗?”
我曾经也抱着这种天真的想法。直到2025年,我作为腾讯云的架构专家,在同一个月内接到了两个完全不同的客户需求:
第一个客户是一家大型头部公募基金。他们的业务总监对我说:“亚哥,我们想做一个‘智能投研助理’。AI 要能读完每天市场上上百份研究报告、券商早报,然后帮我们的基金经理分析宏观走势。核心要求是:数据绝不能外泄,回答不能有任何事实偏差,更绝对不能给出具体的、具有承诺性质的‘买入/卖出’投资建议,否则我们会直接面临证监会的巨额罚款和停业整顿。”
第二个客户是一家头部的在线教育平台。他们的产品总监对我说:“我们要做一个‘AI 英文作文批改老师’。AI 要读学生提交的作文图片(OCR),然后进行语法纠错和润色。核心要求是:语气必须极其温和、鼓励性强。如果学生写了一句病句,AI 绝对不能冷冰冰地直接打红叉,它要通过‘启发式’的提问引导学生自己发现错误,要能激发学生的学习兴趣。”
这两个需求,在非技术人员眼里,全都是“AI 读一段字,然后写一段字”的文本生成任务。
但在产品架构师的物理拓扑图里,它们是完全生活在两个不同物理星球上的生物:
- 金融投研助手:是一场针对“数据隐私、100%事实忠实度、合规审计、冷冰冰的逻辑推导”的阵地战。我们宁可让 AI 说十次“不知道”,也绝对不允许它有一次自作聪明的猜测。它的架构设计偏向于 RAG + 静态图谱硬合规校验。
- 教育作文批改:是一场针对“拟人化情感、少样本启发式推理(Heuristic CoT)、多轮情绪安抚”的心理战。我们宁可让它在语法判定上稍微宽松一些,也必须确保它的字里行间充满了人类老师的温度和循循善诱的节奏。它的架构设计偏向于深度微调(Fine-Tuning)塑造风格 + Prompt 多轮角色扮演。
把前者的架构搬到后者,学生会被 AI 冰冷的教条判定打击到直接退学;把后者的架构搬到前者,基金经理会因为 AI 温柔且自信的幻觉推荐,导致公司直接面临数亿元的合规处罚。
大模型的商业落地,从来不是“把 ChatGPT 接入业务”这么简单。每一个垂直行业,都有其独特的业务潜规则、安全红线、用户心理和数据特征。
这一章,我将带你走出象牙塔。我们首先提炼出大模型在所有行业落地时的“三大共性架构模式”。随后,我们将深度拆解金融、企业知识管理、代码开发、智能客服、AIGC内容生产等五大支柱垂直领域的真实架构方案、核心挑战、关键决策和避坑指南,帮你建立起敏锐的“行业场景嗅觉”。
11.1 跨越行业表象:大模型落地的三大共性架构模式
不管你身处哪行哪业,面临的业务需求多么千奇百怪,一旦我们将业务外壳剥离,在最底层的系统设计中,AI 的落地模式有且仅有三类。
认识这三类共性架构模式,是产品架构师给任何新需求进行“快速技术归档”的前提。
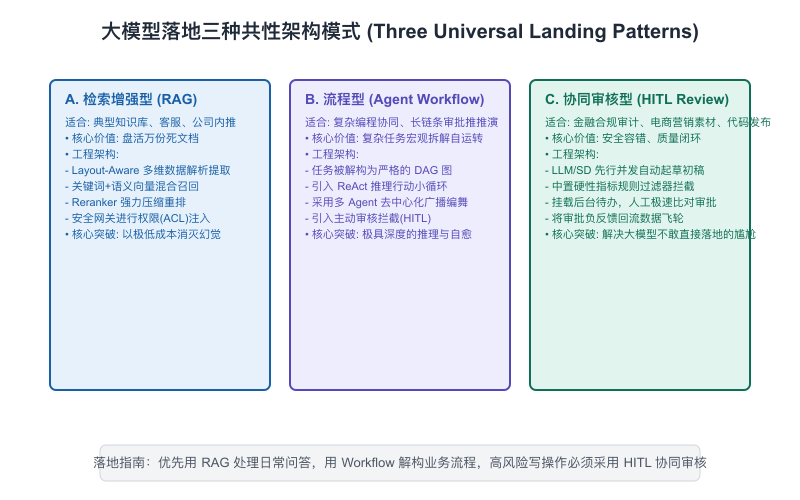
【图11-1】大模型落地三大共性架构模式
模式一:检索增强生成型(RAG Pattern)——“查资料的图书管理员”
- 技术核心:私有非结构化文档 + 语义向量/关键词混合检索 + LLM 总结。
- 本质逻辑:解决“知识储备与事实忠实度”的问题。模型本身不负责决策,只负责在被允许的上下文范围内,充当一个极其聪明的“阅读理解与信息归纳机器”。
- 场景嗅觉特征:只要业务方提出“让 AI 帮我们看文件”、“问关于内部政策的问题”、“总结历史会议或研报”,100% 归档至 RAG 型模式。
- 典型行业代表:金融投研分析、法律合同要素提取、企业内部 FAQ 智能客服。
模式二:Agent 工作流型(Autonomous Agent Pattern)——“能干活的数字同事”
- 技术核心:大模型大脑 + 外部 API 工具箱 + 状态机规划器 + 长期/短期记忆。
- 本质逻辑:解决“自动化行动与工具交互”的问题。模型不再是一问一答,而是被赋予了物理控制权(调用 API、读写数据库、执行代码),能够自主拆解并完成一个多步骤的长链路任务。
- 场景嗅觉特征:只要业务方的需求中包含了“帮我做一件事,做完后告诉我结果”、“自动在多个系统间流转并划扣/修改数据”、“自动修复并上线代码”,100% 归档至 Agent 工作流型模式。
- 典型行业代表:代码智能审查与漏洞自愈、自动化营销图文生成与分发、IT 运维自动化自愈、跨系统多表自动对账。
模式三:人机协作审核型(Human-in-the-loop / Copilot Pattern)——“影子副驾驶”
- 技术核心:大模型生成建议/草稿 + 后台挂起状态机 + 人类在关键控制点点击物理确认(HITL)。
- 本质逻辑:解决“高合规、高风险场景下的安全兜底”问题。大模型并不直接拥有工具的真实世界物理执行权,它只能扮演一个“军师”或“秘书”角色,生成草稿,由人类专家进行物理核对和最后签字放行。
-
挂起队列状态机制(Pending State Queue):
在实际落地中,为了不让 Web 请求因为等待人工审核而产生网络超时崩溃(Timeout),我们必须在 L5 业务编排层设计一个 Redis-backed 任务挂起队列。当 AI 触发高风险执行请求时,编排引擎将当前会话的上下文、建议参数及 Token 令牌序列化(Serialize),写入 Redis 哈希表(Key为
task_id,状态设为PENDING),并释放当前的 Web 执行线程。系统通过 Webhook 向企业微信/钉钉推送一条带有“同意/拒绝”选项的异步通知卡片。一旦人工审批确认,系统通过 Webhook 回调接收批准信号,从 Redis 重新读取该
task_id状态,恢复(Deserialize)编排环境并调用真实的物理写 API,从而完美达成了“安全与性能的双重平衡”。 - 场景嗅觉特征:只要业务场景属于“犯一次错就会带来灾难性法律、资金或生命风险”的领域,无论业务方吹嘘得多么智能,你必须强硬地在架构上将其归档为人机协作审核型。
- 典型行业代表:医疗辅助诊断(出处方)、大额退款审批(划扣)、法务合同终审、高密级系统防火墙规则修改。
11.2 五大核心垂直行业场景深度拆解
现在,我们将这三种共性模式插进产业落地的泥土中。我们精选了当前 AIGC 落地最深、也是我们踩坑最多的五大核心场景进行深度拆解:
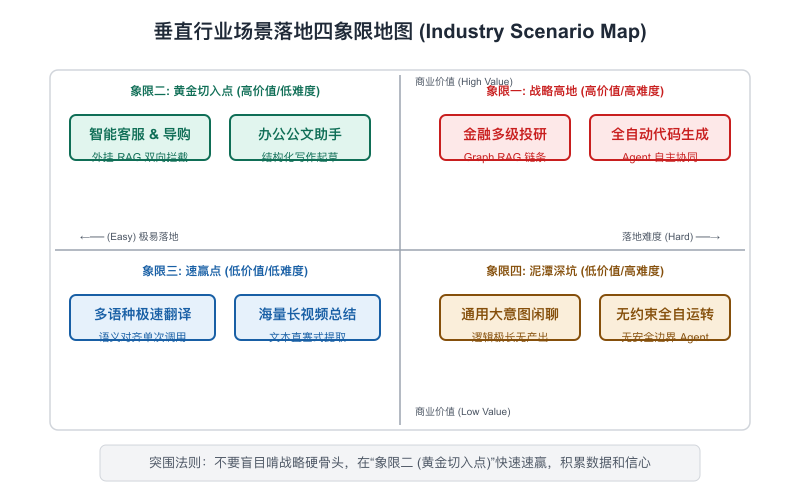
【图11-2】垂直行业场景大模型落地地图
1. 金融行业:智能投研分析平台
金融是典型的知识密集型、数据高时效性、监管极严的行业。
-
业务场景:
基金经理或行业分析师需要快速分析近期关于某一行业(如新能源汽车)的券商研报、产业链财报、以及实时的市场大盘波动,自动输出一份合规的行业风险评估报告草稿。 -
核心挑战(The Pain Points):
- 数据污染:研报和财报中充斥着复杂的跨页三级表格、非标准的折线图,普通 PDF 提取会彻底破坏行列对应关系。
- 时效极其敏感:今天的宏观决策不能用上周的数据回答。
- 监管红线:绝对不能触碰证监会关于“越权提供投资建议”和“虚假事实误导”的刚性法规。
-
架构方案(Architectural Solution):
我们为金融客户设计的智能投研平台,抛弃了单纯的向量检索,采用了“Hybrid RAG + 实体知识图谱(Graph RAG)+ 实时 API 插槽”的联合架构:
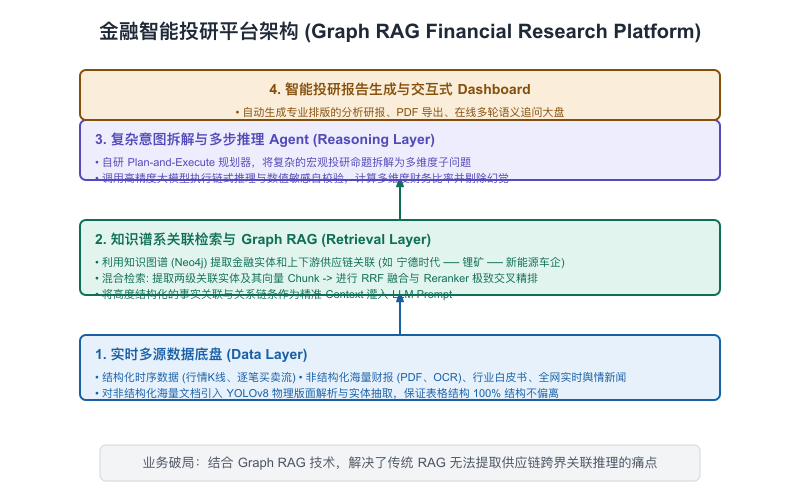
【图11-3】金融智能投研平台架构 -
Graph RAG 在复杂多步金融推理中的落地实践:
在金融投研中,用户经常问一些需要“强关系推理”的问题。比如:“美国对新能源电池的关税限制政策调整了,这会间接影响到我们持仓的哪些下游车企?”这类“关税政策 → 电池公司(如宁德时代) → 下游车企(如蔚来、小鹏)”的多级链条,只靠向量检索是极易迷失的。
我们在架构中引入了 Neo4j 知识图谱。当用户的 Query 进来时,网关通过一个实体链接模型提取实体“美国关税限制”,在图数据库中执行如下的 Cypher 关联路径查询:
MATCH (p:Policy {name: "美国电池关税调整"})-[:AFFECTS]->(c:Company)-[:SUPPLIES]->(car_co:CarCompany) RETURN c.name, car_co.name, car_co.holding_ratio图数据库能在一毫秒内带回精准的实体供给链拓扑关系。我们将这些关系文本化(如:“宁德时代受此政策影响,而宁德时代是蔚来汽车的核心电池供应商...”),与向量检索召回的政策研报 PDF 切片进行多路合并(Context Fusion)后再喂给 LLM。这让 AI 在进行多跳(Multi-hop)推理时,表现出了老练基金经理般的严谨。
-
关键架构决策(Key Decisions):
- 放弃大模型自主推理股票价格:严禁让大模型预测或估算股票当前的均线数值。涉及到任何实时行情(如“腾讯控股今天收盘价是多少”),必须在 Prompt 中将其定义为一个硬编码的 API 工具调用(Function Calling),由网关去证券行情库查回最精确的十进制数字。
- 极度严苛的“合规裁判模型”:在流式生成端,架设一个独立的“合规拦截卫士(Compliance Guardrail)”。用一个小模型实时扫描模型吐出的文字,一旦发现模型说出了带有具体买入暗示的语句(如“建议投资者积极建仓”),网关毫秒级掐断连接,降级替换为“以上数据仅供参考,不构成具体投资建议”。
-
常见深坑与避坑指南(The Pitfalls):
- 大坑:相信大模型自己能算对财务公式。很多团队让大模型读完财报后计算“净利润率同比增长率”。大模型在 Token 计算中经常算错十进制小数。
- 避坑:模型只负责提取(Extract),计算交给代码(Compute)。让大模型通过结构化输出约束(JSON Schema)把财报中的“本期净利润、上期净利润”等原始数值提取出来,后端写一行 Java/Python 代码算好了,再把答案拼接回去。
2. 企业内部:非结构化知识管理与智能会议助手
这是每一个企业上马 AI 项目时的“首选试验田”。
- 业务场景:
员工在内部 Wiki、企业微信群、腾讯文档中积累了海量的历史设计稿、例会录音转写文本、各版本制度文件。员工希望向 AI 询问任何关于公司流程、历史项目决策的问题,并附带引用来源。 - 核心挑战(The Pain Points):
- 文档格式极度异构:有 PPT、Word、Excel,还有大量的会议录音(需要ASR转写)。
- 动态权限管理极其繁琐:同一份周报,开发组长能看,外包员工不能看;HR 的晋升文件只有 VP 能看。
- 架构方案(Architectural Solution):
采用我们在第7.2节中详细阐述的“解耦型动态 ACL 权限隔离 RAG 架构”。 - 关键架构决策(Key Decisions):
- ASR 文本噪声分层清洗:会议录音转写(ASR)出来的文本,充斥着人类口语的“呃、啊、那个、其实”等环境噪音和重复语句。在进入向量数据库前,必须通过一个专门的清洗管道(Cleaning Pipeline),利用规则库和轻量级小模型,将这些口语废话物理剔除,否则这部分噪音会严重稀释向量检索的相似度。
- 多格式 PDF 预处理的 Triage 策略:不要用同一种解析器对付所有文档。在 Ingestion 阶段设计一个分流器(Triage):如果是 PPT 幻灯片,按每张 Slide 单独切片,不进行合并;如果是 Excel 表格,强制转换为 JSON Lines 格式进行存储;如果是大段正文 PDF,才走 Layout-Aware 解析。
- 常见深坑与避坑指南(The Pitfalls):
- 大坑:向量库和企业内网 Wiki 数据不一致(Data Staleness)。Wiki 里的文档今天被作者修改或删除了,但向量库里的旧切片依然存在,导致 AI 检索出了过时的或已被删除的越权信息。
- 避坑:建立基于 Webhook 事件触发的“增量同步飞轮”。与 Wiki 平台(如 iWiki、腾讯文档)打通。只要用户在 Wiki 上点击了保存或删除,Wiki 平台必须向 RAG 的 Ingestion 网关异步发送一个 Webhook 事件(包含 doc_id 和 action)。网关拦截事件后,立即在向量库中执行
delete_by_metadata(doc_id),然后重新进行切片写入。
3. 代码开发:AI 智能辅助编码与代码审查安全网
研发团队提效的终极利器,但也是安全合规官的“眼中钉”。
-
业务场景:
开发在 IDE(如 Cursor / VS Code)中写代码,AI 自动生成后续逻辑。在提交 Merge Request(MR/PR)时,AI 自动进行静态代码扫描,查找潜在的逻辑 Bug、性能漏洞和安全合规缺陷,并在 MR 页面自动发表 Review 评论。 -
核心挑战(The Pain Points):
- 多文件依赖(Context cross-references):单看当前文件的一行报错没用,它的类定义可能在另一个文件的第 300 行。
- 源码主权保护(IP Protection):大企业的核心商业代码绝对不允许流入公有云作为厂商的训练数据。
-
架构方案(Architectural Solution):
采用 “本地 IDE 插件代理(Local Agent) + 混合模型路由网关 + AST 静态代码解析辅助” 的联合架构。
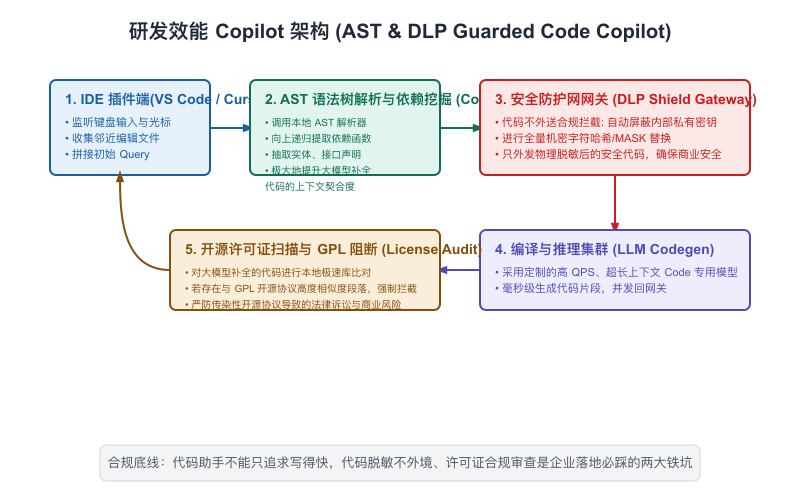
【图11-4】代码开发 Copilot 架构 -
AST(抽象语法树)跨文件依赖拼装的落地逻辑:
在代码补全或 Review 中,为了在低延迟(<200ms)限制下提供精准的上下文,本地 IDE 插件代理必须智能化抽取依赖。
比如,当开发在UserService.java中调用UserMapper.findActiveUsers(id)时,本地 Agent 会执行如下逻辑:- 静态语义解析:解析当前文件,发现
UserMapper的类导入路径为com.tencent.mapper.UserMapper; - 快速依赖定位:在本地 IDE 索引缓存(或者是企业内部 Git 预建索引库)中,极速读取
UserMapper.java的 AST 树节点; - 精细结构提取:只过滤并提取
findActiveUsers这一具体方法的定义树节点(MethodDeclaration)及其关联的 XML SQL 映射段,而丢弃文件中其他无关的 500 行无关方法。 - 紧凑拼接投递:将此 MethodDeclaration 拼装入 Prompt:
// Reference: com.tencent.mapper.UserMapper.java\n[代码段],发送给私有部署的 Coder 专属大模型。这彻底解决了大上下文导致的推理延迟恶化问题。
- 静态语义解析:解析当前文件,发现
-
关键架构决策(Key Decisions):
- 利用 AST 提取跨文件上下文:如上所述,只提取高密级关联类声明。
- 数据不外境的物理拦截:大厂在做代码 Copilot 时,通常会在内网部署一套完全私有化的代码专用模型(如 DeepSeek-Coder-33B 或 Qwen-2.5-Coder-72B),彻底物理隔离公有云,从源头上打消合规部门对“核心代码资产外泄”的顾虑。
-
常见深坑与避坑指南(The Pitfalls):
- 大坑:AI 自动引入了开源许可证漏洞(License Compliance)。大模型在生成代码时,其参数里固化了全网的代码。有时候它会原封不动地吐出一段属于 GPL 协议的高风险代码。如果公司直接商用,会面临极其严重的开源协议违约诉讼。
- 避坑:在代码生成网关的输出端,必须强制挂载一个开源协议扫描器(如 BlackDuck 或 OpenSource Scanners)。一旦检测到 AI 生成的连续代码片段与全网 GPL 仓库的相似度超过 85%,直接物理阻断,要求 AI 重新进行“重构(Clean-room Refactoring)”,杜绝合规隐患。
4. 客户服务:智能客服与情绪感知人机协同平台
大模型提质增效最立竿见影的传统场景。
-
业务场景:
用户在微信、网页或 App 端向商家发起售后咨询、投诉或者业务退换。AI 智能客服进行第一线响应,并在发现用户情绪恶化、或遇到高风险复杂业务时,无缝、平滑地将上下文切换给真实的人工客服接管。 -
核心挑战(The Pain Points):
- 多轮对话状态管理(Session State):用户在第 5 轮提问时说“按我刚才说的办”,AI 不能迷失在多轮对话的上下文膨胀里。
- 情绪拐点检测(Emotion Turn-detection):什么时候该继续让 AI 答,什么时候必须立刻切人工?
-
架构方案(Architectural Solution):
采用 “双轨状态机 + 实时情绪感知路由网关(Sentiment-Aware Routing)” 架构。 -
情绪感知路由(SentimentRouter)的底层算法模型与决策实现:
不能只依赖昂贵的大模型对每句话做情感分析,延迟和成本都不可接受。
我们设计了一个“双轨轻量级情绪过滤器”:import re class SentimentRouter: def __init__(self): # 1. 编译情绪词汇强规则正则表达式(讽刺、辱骂、不耐烦、维权) self.angry_signals = re.compile(r"(投诉|起诉|垃圾|消协|12315|转人工|叫你们经理|欺骗|骗子)") self.excessive_punctuation = re.compile(r"([!?\?!]{3,})") # 连续三个以上标点代表情绪剧烈 def evaluate_sentiment_score(self, user_text: str, history_chat_logs: list) -> float: """ 计算用户的情绪恶化得分 (0.0 到 1.0) """ score = 0.0 # 规则一:触发核心词与敏感标点,直接给予高初始分 if self.angry_signals.search(user_text) or self.excessive_punctuation.search(user_text): score += 0.6 # 规则二:调用轻量级、高并发的情感分析模型(如本地 DistilBERT)分析本轮输入的文本得分 local_model_score = local_fast_sentiment_classifier(user_text) # 返回 0(正面) 到 1(极端负面) score += local_model_score * 0.4 # 规则三:衰减趋势累加。如果用户连续 3 轮情绪得分均在 0.7 以上,触发极速降级转人工 return min(1.0, score)当该
SentimentRouter计算出的情绪恶化得分在单轮突破 0.85 时,系统会立刻中断 AI 的生成,在 L6 端将对话状态平滑切给人工座席,并由系统自动在坐席后台以红色字体标出:“系统红色警报:该客户当前处于愤怒边缘,AI已阻断接管”。 -
关键架构决策(Key Decisions):
- 基于语义困惑度与情绪的双重人工接管机制(Human Hand-off Triggers):如上所述,双重维度控制。
- 在智能客服的 Prompt 中,强制剥夺其任何“特权决定权(Right to Grant)”:防止大模型在角色扮演中乱给业务承诺(如乱给五折折扣等商誉危机)。
-
常见深坑与避坑指南(The Pitfalls):
- 大坑:大模型乱给业务承诺(Over-promising)。
- 避坑:如上所述,在红线指令中写死,剥夺任何“特权决定权”,仅充当信息解答和表单引导助手。
5. 内容创作:面向电商与营销的 AIGC 闭环管线(AIGC Ingestion pipeline)
从“单图生成”走向“工业级流水线量产”的创意变革。
-
业务场景:
电商运营人员只需要输入一个商品链接和核心卖点,系统自动生成 5 套完全不同风格的、可以直接用于小红书、朋友圈分发的营销推文,并自动匹配生成的符合品牌风格的营销海报背景图。 -
核心挑战(The Pain Points):
- 质量一致性(Brand Consistency):AI 绘图工具(如 Midjourney / Stable Diffusion)在生成背景图时极其随机。如何保证生成的 5 张图片里,商品本身的 3D 尺寸、品牌 Logo 的颜色和相对位置 100% 保持一致,不产生任何变形?
- 版权与肖像权红线(Copyright Compliance):AI 生成的模特脸、背景素材绝对不能侵犯任何真实人类的肖像权,否则会被诉讼。
-
架构方案(Architectural Solution):
采用 “LLM 策划 Agent + SD/Flux 局部控图(ControlNet) + 传统图形图像中间件(Pillow/Canvas)合成” 的混合管线架构。
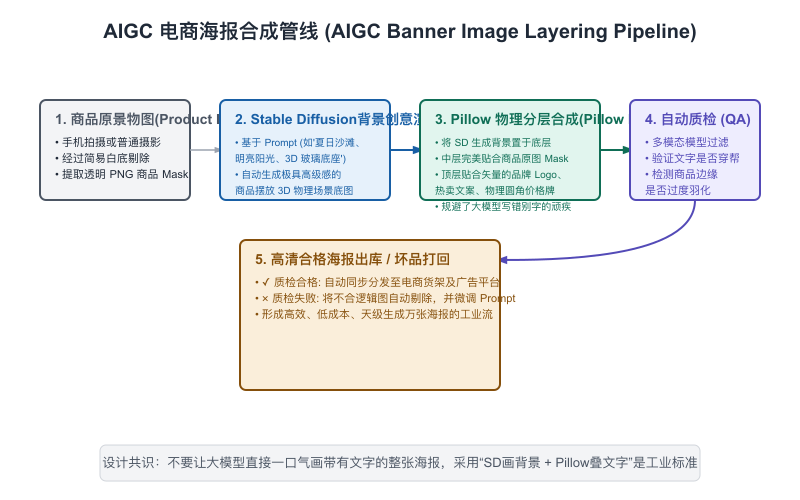
-
【图11-5】AIGC 电商营销海报闭环管线*
-
关键架构决策(Key Decisions):
-
严禁使用生成模型去画 Logo 和文字:大模型和绘图模型(如 SDXL)在生成图片时,如果直接让其渲染品牌的英文字母或价格标签,一定会产生微小的拼写错误或边缘锯齿,显露出严重的廉价 AI 味(De-aesthetic)。
正确的架构决策是:分层渲染。让绘图模型只负责生成纯净的、无文字的精美背景图(创意部分)。生成后,在网关层调用传统的确定性图形库(如 Python 的 Pillow 或 Node.js 的 Sharp),像贴图层一样,将矢量的品牌 Logo、标准的商品 3D 图、高保真的价格标签文字物理“贴”在图片指定坐标上。这保证了商业海报的绝对专业与严谨。
- 模特的版权物理规避:在调用人脸/模特生成模型时,强制接入“无损人脸合成”。生成的面部特征必须通过多张公开、无版权争议的 3D 生成人脸进行插值混淆,确保世界上绝对不存在一个长得一模一样的人类,从物理底层彻底豁免肖像权官司。
-
-
常见深坑与避坑指南(The Pitfalls):
- 大坑:批量生产出了大量垃圾美学内容(Creative Fatigue)。由于 Prompt 是固定的,运行一段时间后,运营人员发现系统生成的 1000 张小红书推文和海报看起来千篇一律,产生严重的审美疲劳,导致最终转化率(CTR)崩塌。
- 避坑:引入“爆款数据闭环(Insight-driven Reinforcement)”。将生成管线与电商平台的广告投放系统打通。每天把点击率(CTR)排名前 10% 的“爆款海报”和文案特征(如色彩饱和度、文案长度、情感倾向标签)拉回,由一个小模型将其提炼为新的 Prompt 黄金参考示例(Few-Shot Seed)注入管线,自动把落后点击率的 Prompt 归档淘汰,让 AIGC 管线自发地跟着真实的商业市场审美进行敏捷演进。
11.3 落地成功率提升的四项跨行业共性经验
在看完了这五个截然不同的垂直行业后,我相信你已经深刻感受到了“具体问题具体分析”的魅力。但在这些差异化的架构盒子背后,我们大厂架构团队在经历了数千次线上洗礼后,沉淀出了四项放之四海而皆准的共性成功经验:
经验一:数据质量(Data Cleanliness)永远大于模型智商(Model Intelligence)
很多团队在项目效果不好时,第一反应是:“是不是 Qwen 不行?我们要不要斥巨资去接最新的 GPT-4o-max?”
相信我,在 90% 的企业级 RAG 和 Agent 应用里:
大模型智商的上限,被你那一堆乱七八糟的、含有页眉页脚、表格变形、重复版本、ASR废话的原始数据死死锁在了一个极低的高度。
你花两周时间调试出一个精妙的 2000 字 System Prompt,其效果提升可能还不如你安排一个初级研发花两天时间,人肉把知识库里那 50 张表格转成干净的 Markdown 格式来得明显。
成功实操指南(Step-by-step Guide):
- 数据清洗(Data Linting)前置:在项目启动首周,建立严格的数据 Linter。自动扫除文档中的无用空行、非标准字符、重复的页眉页脚。
- 人肉重构高频 FAQ:不要把几百个零散的问题指望让 RAG 自己总结。把最热的 50 个用户痛点问题,由人工精细整理成结构完美的 Q&A 对写入向量库。这 50 个问题能覆盖线上近 60% 的总 QPS,你的初始满意度瞬间就稳住了。
- 多格式归一化:在数据入库前,强制进行统一的 Ingestion 转换,无论输入是 Docx 还是 PDF,在切片阶段统一呈现为纯净的、去噪后的 Markdown 字符。
经验二:最核心、最繁重的工作是“用户预期管理”
AI 产品和传统软件最大的不同在于,它会“犯错”,且它的表现上限是统计概率。
然而,大部分业务方和客户高管,在被媒体和厂商狂轰滥炸的宣传误导后,他们对 AI 的初始预期是 100% 的万能完美助手。
如果第一天上线,AI 产生了一次幻觉或者说错了一句话,用户心中那座高耸的信任大厦就会瞬间崩塌。他们会下意识地得出结论:“这东西不靠谱,又是个花拳锈腿的 Demo。”
成功实操指南(Step-by-step Guide):
- 产品界面去“神化”:不要在界面上起名叫“无所不能的超级智脑”,起名叫“XXX业务小助手(基于历史参考文档进行阅读归纳)”。
- 引用透明可查:在 AI 生成的每个事实陈述旁,强制附带引用角标。用户点击角标,前端立刻侧边栏分屏展示 RAG 召回的原始文档段落快照,并标注:“以上回答由 AI 基于此原始资料总结得出,请核对。”
- 对“不知道”进行正面奖励:不要把模型“拒绝回答”当成耻辱。在评估模型表现时,AI 在超出知识边界时大方承认“我无法从资料中找到依据,建议咨询人工客服”应当获得极高的合规加分。这在商业信用上,远比编造一个荒谬的幻觉强千百倍。
经验三:小场景闭环(MVP)验证,永远好于“宏大的技术平台规划”
有些团队一上来就试图建一个“覆盖集团所有部门、支持上万并发、打通上百个异构数据库”的庞大 AI 平台。
这在软件工程中是极易夭折的“大炼钢铁”。
成功实操指南(Step-by-step Guide):
- 寻找“极窄、极痛、低风险、对延迟宽容”的小切口:比如帮开发团队提取每日大量的 Bugly 堆栈报错信息并自动分类、或者帮售后团队整理用户群内的售后反馈生成日报。
- 闭环小团队验证:不要全员推广,只挑一个 5 人的先锋运营小组,用两周时间给他们做一个最粗糙但好用的 1.0 工具。
-
用真实的提效数字换取大预算:当这 5 个运营同事在周会上告诉老板:“以前我每天人肉整理日报要两个小时,现在 AI 帮我 10 秒生成好,我只需要花五分钟对一下,每天省出了一个半小时,且没有发生一次漏报。”
此时,你手里握着的可量化财务收益(ROI)和真实的群众呼声,将成为你在执委会上换取大平台建设算力预算的最强王牌。
经验四:效果评估体系,必须建立在第一行代码写完之前
千万不要等系统全量上线了,才拍脑袋说“我们来测测效果”。
我们在第10.4节讲授的黄金测试集(Golden Dataset)与三层评估体系,必须在项目启动的第一周、在开发同学还在写数据库连接时,就已经签署锁定。
只有这样,开发、产品和算法团队才有了统一的、不可被收买的“智商度量标尺”。你们在往后的 6 周里,每一次调整 Prompt、每一次优化 RAG,才能非常有底气地看着雷达图大声说:“我们这个星期的重构,让系统的 Faithfulness(忠实度)指标从 0.72 提升到了 0.91,系统更安全、更稳定了!”
成功实操指南(Step-by-step Guide):
- 业务专家交叉背书黄金标准(Ground Truth Curation):
在编写黄金测试集时,对于核心主观/客观问题,常常会出现“公说公有理,婆说婆有理”的现象(比如:对于某个擦边退款诉求,HR总监认为应该拒绝,客服经理认为可以安抚退款)。产品架构师必须组织评审会,协调各方利益,在测试集里强制达成唯一的、不可动摇的标准参考答案。没有绝对唯一的标准,算法开发就失去了绝对坐标。 -
建立多人评审的评估一致性机制(Inter-Rater Reliability):
在业务上线后的日常盲测评估中,如果是人工对大模型生成的答案进行主观打分(1到5分),为了防止单个评审专家的个人喜好或情绪偏差干扰评估结果,系统必须引入“多人双盲评审机制(Double-blind Scoring)”。我们要求对于核心争议案例,由 2 名以上专家独立打分,并通过计算柯恩氏卡帕系数(Cohen's Kappa)来度量专家之间的一致性:
$$\kappa = \frac{p_o - p_e}{1 - p_e}$$
其中,$p_o$ 是专家间实际达成一致的比例,$p_e$ 是随机达成一致的期望比例。只有当卡帕系数 $\kappa \ge 0.75$(代表专家组打分具有高度一致的可信度)时,人工评估结果才被记录为线上迭代的真实负反馈,否则该案例被打回重新讨论标准,彻底规避了指标的随性漂移。 - CI/CD 流水线硬阻断:
将黄金测试集的自动化打分流水线(如 Ragas / G-Eval 自动执行脚本)无缝接入 Git 代码提交的 Webhook。任何 Prompt 或代码的变更,如果导致评测雷达图指标下跌,系统在编译部署阶段实行物理红线强行阻断(Hard Gate),拒绝构建发布,从而确保系统上线时的智商永远只升不降。
本章小结
这一章,我们把高雅的方法论拆解成了各垂直产业中最真实的工程泥土与斑驳的实战痕迹。我们看清了,同一行 API 代码,在严苛合规的金融帝国与强调温情安抚的教育阵地里,会变幻出怎样完全不同的技术盒子。
本章核心要点:
- 场景嗅觉是架构师的顶级天赋:任何复杂的业务,在底层都能且必须被无情地归档为 RAG 型、Agent 型、或人机协作型三大共性架构模式。
- 金融的核心是红线防守:严禁模型自己计算、严禁模型越权提供买卖建议,建立基于 G-Eval 的合规裁判与毫秒级输出流内容拦截中间件。
- 企业知识管理重在 ACL 权限解耦:在向量库元数据中存储静态安全标签,在网关层通过 LDAP 水平扁平化注入,实现用户权限变动时免重整向量的优雅设计。
- 代码辅助的核心是上下文感知与合规隔离:利用 AST 抽象语法树提取精准的跨文件类定义依赖;在输出网关挂载开源许可证扫描仪,防止 GPL 违约风险。
- 智能客服重在情绪感知双轨跳转:结合语义困惑度与负面情绪打分,设计无感的人机客服平滑交接,严防 AI 越权给予用户打折/退款承诺。
- AIGC电商管线重在分层合成:严禁用生成模型直接渲染 Logo 和价格文字,由 Stable Diffusion 负责精美背景、由 Pillow 图形库在指定坐标物理叠加矢量前景。
下章预告
到这一章结束,我们不仅完成了全书的所有技术链条(第1-5章认知,第6-8章核心技能),更将这些技能武装成了工程化的体系与穿梭于各大行业的实践地图(第9-10章工程方法论,第11章行业地图)。
你已经是一个在任何场景下都能独当一面、在腾讯云或你的公司中主导大型 AI 平台设计的殿堂级产品架构师了。
但是,大模型这个领域,变化速度实在是太快了。
可能你刚刚花了两周时间通读完这本书,市面上就蹦出了一个“宣称完全杀死RAG、支持千万级上下文”的新模型;可能你刚刚搭好一个精妙的 Agent,行业里就刷屏了一篇“Agent 已死、世界模型才是未来”的爆款Newsletter。
面对每天铺天盖地的技术噪音、每隔 6 个月就会产生一次的颠覆性进展,作为产品架构师,你要怎么跟上这个时代?你怎么保证你今天学到的知识在 3 年后依然是你赖以生存、保持绝对清醒与终身竞争力的送别礼物?你怎么建立起自己源源不断、百毒不侵的信息过滤与进化系统?
下一章,我们迈入全书的收官终点站:
第12章 · 持续进化——这个领域的变化速度,你要怎么跟。
我们将为你梳理出哪些是“6个月就过期的短命知识”、哪些是“5年内坚不可摧的持久地基”;我们将为你首度披露大厂技术专家们日常使用的“分层信息源过滤网”以及“30天快速行动进化清单”。
这不仅是技术大结局,更是我送给你的一份,能让你在未来十年 AIGC 黄金浪潮中保持绝对清醒与终身竞争力的送别礼物。
下一章,我们不见不散。
延伸阅读
- 《BGE M3-Embedding: Multi-Lingual, Multi-Function, Multi-Granularity Instruction Retrieval》(https://arxiv.org/abs/2402.03216)—— 腾讯及智源研究院发布的 BGE-M3 统一稀疏-稠密向量检索引擎经典论文,是实现我们在 11.2 节所提及的下一代混合检索架构的必读算法文献。
- OWASP:《Prompt Injection and Indirect Injection Defense Playbook》(https://owasp.org/)—— 专门针对我们在本章提及的,客服、IT自愈系统中如何物理抵御第三方网页和邮件中隐藏的“间接提示词注入攻击”的最高合规防御实践手册。
- Black Duck Software:《OSS License Compliance in the Age of Generative AI》(https://www.synopsys.com/)—— 深度探讨了代码 Copilot 模式下,如何防范 AI 自动生成的 GPL 协议代码给企业带来商业开源许可证违约和诉讼风险的技术白皮书。
- ControlNet:《Adding Conditional Control to Text-to-Image Diffusion Models》(https://arxiv.org/abs/2302.05543)—— 开启了现代 AIGC 电商管线工业级应用的里程碑式论文。详细讲授了如何通过边缘(Canny)、深度图(Depth)精确控制图像生成的空间排版,解决商品变形的物理底层逻辑。