学习笔记-AIGC全栈认知与落地(12)
第12章 · 持续进化——这个领域的变化速度,你要怎么跟
开场:红皇后的赛跑与不可退却的行业阵地
在《爱丽丝镜中奇遇记》中,红皇后对爱丽丝说了一句名言:“在这个国度里,你必须不停地奔跑,才能保持在原地。如果你想走到别的地方,你必须跑得比现在快至少两倍!”
今天的 AIGC 领域,就是这样一个活脱脱的“红皇后领地”。
作为一个在大模型浪潮里摸爬滚打了几年的产品架构师,我每天清晨睁开眼,都会面临一种近乎窒息的信息过载:
- 手机弹窗推送:“RAG 已死!某千亿参数大模型支持 1000 万 Token 上下文,检索技术彻底沦为历史。”
- 群聊里在热议:“某大厂昨晚发布了最新 Agent 框架,号称 100% 自动写出大型商业软件,程序员即将全部失业。”
- 朋友圈里刷屏:“基础大模型排行榜(LMSYS)今天再次洗牌,第一名再次易主。昨天你花了两周调优的 Prompt 技巧,在今天的新模型上面全部失效。”
如果你是一个刚刚读完前面11章、筹躇满志准备大干一场的 AI 学习者,你极有可能会在这种日新月异的变化面前,产生一种巨大的虚无感和技术焦虑:
“亚哥,我花了一个星期把你这本书读完,但我害怕等我下个月把系统搭起来时,你书里讲的这些架构、代码、工具,就已经全部过期了。在这个每天都在推倒重来的领域,我们到底该怎么建立起自己的‘终身竞争力’?”
这是一个极其真实、也极其残酷的问题。
我写这一章的目的,不是为了给你打鸡血,而是想在全书的终点,送给你一套在大模型时代百毒不侵的“防焦虑与持续进化自操作系统”。
在这一章里,我们将拆解哪些是“6个月就会过期的短命知识”、哪些是“5年以上坚不可摧的持久地基”。我会首次向你公开我们技术专家日常使用的“三层信息源过滤网”、“螺旋学习法”以及一个“30天快速落地自进化行动清单”。
这不仅是本书的最后一章,更是我送给你的一份,能让你在未来十年 AIGC 黄金浪潮中保持绝对清醒、并拥有终身竞争力的“毕业赠礼”。
12.1 知识半衰期:哪些知识会迅速过期,哪些不会
要在这个领域保持清醒,你必须学会给知识做“分类隔离”。很多人的焦虑,来自于他们把 80% 的时间花在了学习那些“注定在 6 个月内就会过期的短命知识”上,却忽视了去构筑那些“5年甚至10年都不会动摇的持久知识地基”。
我们通过一张清晰的知识分类对比卡片,来划分你的时间预算:

【图12-1】大模型时代知识半衰期对比
1. 6-12个月就会过期的“短命知识”
这些知识变化最快,也最容易在媒体上制造噱头,它们是噪音的主要来源:
- 模型排行榜(Leaderboards):今天 A 模型第一,下个月 B 模型登顶。天天盯着 LMSYS 榜单和厂商的评测跑分,除了增加焦虑,没有任何实际工程价值。
- 具体软件开发框架的 API 写法:比如 LangChain 某个特定版本的 Agent 初始化代码、vLLM 的具体配置命令行参数。这些开源工具每隔三个月就会进行一次推倒重来的 API 重构。你把它们背得再熟,下个版本一发布,你依然要重新看文档。
-
针对特定模型微调出的“Prompt 玄学”:比如在 2023 年风靡一时的“给大模型 20 美元小费它会答得更好”、“深呼吸后再回答”等提示词偏方。随着新一代大模型安全对齐和人类反馈强化学习(RLHF)训练分布的调整,这些玄学技巧正在物理性地失效。
为什么提示词技巧会失效? 因为模型在微调(SFT)和安全对齐阶段,模型厂商会不断改变其训练数据的指令分布。例如,早期的 Claude 3 模型极度偏好 XML 标签(如
<context>和<instruction>),因为它的预训练数据里包含了大量类似的代码片段;而新一代的 GPT-4 级模型则在 Markdown 标题和 JSON Schema 约束上表现出了更高的零样本对齐率。试图去记忆这些随模型版本变迁而剧烈波动的特定语法偏好,在工程上无异于刻舟求剑。
2. 5年以上坚不可摧的“持久知识”
这些才是产品架构师赖以生存的 Category Authority,是系统设计的“定海神针”:
- 统计推断与大模型的基本运行原理:
理解“Next Token Prediction(预测下一个词)”的概率本质。只要这个底层的自回归范式(Autoregressive)不发生改变,你就永远能理解为什么幻觉不可避免、为什么模型会迷失在中间、为什么它无法进行 100% 精确的代数运算。 - 香农信息论与语义熵(Information Theory & Semantic Entropy):
理解 Prompt 压缩、语义缓存以及模型路由的底层理论。为什么我们可以无损地将一个 4000 字符的 Prompt 压缩 50%(使用 LLMLingua)?因为在信息论中,人类语言存在着大量的“红利冗余”(Redundant Tokens),大模型在推理时寻找的是高信息熵(高能量、高特征)的关键语义节点。只要你理解了“语义密度最大化”的设计原则,不论未来的 Prompt 语法怎么变,你设计出的指令永远是最精炼、最省钱、TTFT 延迟最低的。 - 系统的 Trade-off(权衡)工程思维:
我们在全书中反复强调的:成本(Cost)、延迟(Latency)、质量(Quality)的三角形博弈关系。新模型变快变便宜了,但这个三角形的制约法则永远存在。你怎么做小模型路由分流、怎么做语义缓存,这些系统化治理的逻辑永远不会过期。 - 人机协作(Human-in-the-loop)的边界划分:
根据业务副作用风险等级,设计“影子、审批、完全自动化”的控制权交接。人类在复杂商业、伦理和资金安全上的最后把关红线,只要人类还是社会的主体,这个设计原则就坚如磐石。 - 系统可观测性与度量科学(Observability & Metrics):
我们在第10章中讲授的:黄金测试集(Golden Dataset)的构建、LLM-as-a-judge 裁判打分机制(Ragas)、以及通过 A/B 灰度进行 Z检验 P值 显著性计算。不管底层模型换成什么,这套用来度量系统智商和迭代质量的科学量化工具箱,永远是软件工程的底盘。
产品架构师的黄金时间预算分配:你应该把 80% 的深度思考时间,用来内化和锤炼那些“持久知识”;而只留 20% 的时间,在做项目时去速查和搬运那些“短命知识”。
12.2 信息源的分层管理:如何建立你的“信息空气净化器”
在这个时代,“知道该忽略什么”往往比“知道该学习什么”更重要。信息不够的时代已经过去了,信息被污染、被噪音充斥的时代已经到来。
作为产品架构师,你必须在自己的日常工作流中,架设起一个“三层信息源过滤网(Three-tier Information Filter)”:
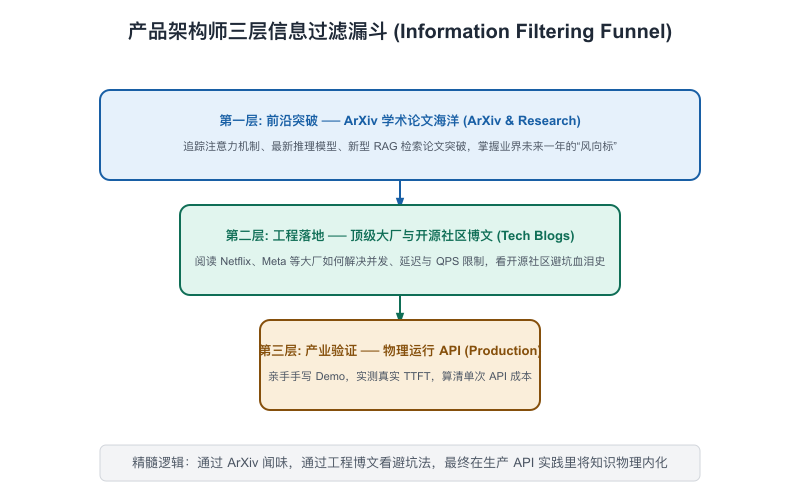
【图12-2】产品架构师三层信息过滤网
第一层:每日学术与底层开源追踪(Tier 1: Read the Source)
这一层旨在直面源头,过滤一切二手解读的噪音。
- 追踪目标:学术界和顶级工业实验室刚发布的原始论文(ArXiv)摘要。
- 获取秘诀:
- 每天清晨,利用 Perplexity 或者是 Hugging Face Daily Papers 网页,花 10 分钟浏览前 5 篇在 AI 社区热议的论文摘要。
- 核心关注人:关注 Andrej Karpathy(OpenAI 联合创始人)、Lilian Weng(前 OpenAI 安全系统负责人)等顶级专家的社交媒体发言。他们发声不高频,但每次发声都是一针见血的底层信号。
第二层:每周方法论与工程提炼(Tier 2: Engineering Case Studies)
这一层旨在吸取行业内被验证过的真实工程落地预案。
- 追踪目标:知名科技公司(如 Meta、Netflix、Pinterest、Uber)的 Engineering Blog,以及权威 AI 社区的工程周报。
- 获取秘诀:
- 阅读 Andrew Ng(吴恩达)的 Newsletter 《The Batch》,里面对每周技术进展的产品与商业落地点评极其深刻。
- 阅读 Semianalysis 或者是 Anyscale Blog,里面关于 GPU 算力成本、吞吐效率和推理加速的实测数据,是架构师做财务预算折算时的黄金参考。
第三层:每月商业与行业风向评估(Tier 3: Executive Summary)
这一层旨在判定宏观商业环境变化对你所设计系统的边界影响。
- 追踪目标:主流大模型厂商(如 OpenAI、Anthropic、Google DeepMind、腾讯云、智谱)的官方产品发布会和开发者技术文档。
- 获取秘诀:
- 重点看他们的 API 定价变化趋势和上下文窗口升级说明。这直接决定了你下个月的“语义缓存拦截率目标”和“超长上下文直塞可行性”。
架构师遇到“新技术”时的“灵魂三问判定法”
每次你在朋友圈或自媒体上刷到所谓的“XXX新技术彻底干掉了XXX旧技术”时,不要惊慌,为了帮大家建立客观、笃定的判断力,我们用最近业界热议的两个大热点——“投机采样(Speculative Decoding)”与“百万超长上下文(Million-Context)”来实战走一遍这“灵魂三问判定法”:
案例 A:大热技术“投机采样(Speculative Decoding)”
- “它改变了我们 L1-L6 分层架构中哪一层(Level)的能力边界?”
- 回答:它改变了 L1 算力基础层(推理加速引擎)的性能边界。它利用一个小参数模型(Draft Model)去猜测 Token,再用高阶大模型(Target Model)快速并行验证,从而在不损失智商的前提下将推理速度提升 2 到 3 倍。
- “如果我立刻用它平替,系统指标能获得 10倍 的数量级提升吗?还是只有微弱增益?”
- 回答:对于实时流式(Streaming)对话,它能将首字延迟(TTFT)和单字生成耗时(TPOT)直接减半,费用却完全不变。这是一次显著的性能越升。
- “这是长期的底层技术演进(Evolution),还是一次性的商业 PR 秀?”
- 回答:这是确定性的技术演进。在 vLLM、TGI 等主流底层开源推理后端中已经成为了默认内置参数。
- 架构师最终决策:极力支持。安排运维和算法同学在部署 L1 推理引擎时直接开启该配置,前端和业务编排层代码无需修改一行。
案例 B:大热宣传“百万 Token 超长上下文直塞全面杀死 RAG”
- “它改变了我们 L1-L6 分层架构中哪一层(Level)的能力边界?”
- 回答:它拓展了 L1 层的上下文输入窗口硬上限。
- “如果我立刻用它平替,系统指标能获得 10倍 的数量级提升吗?还是只有微弱增益?”
- 回答:完全没有提升,反而会导致费用雪崩。我们在第7.1节和第10.3节做过财务计算,对于 1000 万字的数据,单次直塞消耗上千元 API 费用,而 RAG 只需要几分钱。
- “这是长期的底层技术演进(Evolution),还是一次性的商业 PR 秀?”
- 回答:大模型能读完长文本是事实,但“低成本高并发下使用它”在现阶段是厂商夸大其词的商业 PR。
- 架构师最终决策:不为所动,死守 RAG 底线。不投入任何工程时间去重构系统。
12.3 学习方法:输出倒逼输入的“螺旋演进学习法”
看十遍关于 RAG 的视频,其学习效果也远不如你亲手把一个 PDF 切片存入向量库一次;写十个本地 Demo,其学习效果也远不如你经历一次线上 429 TPM 超限的系统性崩溃。
在 AIGC 时代,学习知识唯一的捷径是“螺旋演进学习法(Spiral Learning Method)”。其核心理念是:用物理世界的输出,无情地倒逼并校准你脑海中的输入。
[ 阶段一:概念内化 ] ──► [ 阶段二:动手建立玩具 Demo (30分钟) ] ──► [ 阶段三:产品与业务折算 ] ──► [ 阶段四:物理输出 (写作/授课/带新人) ]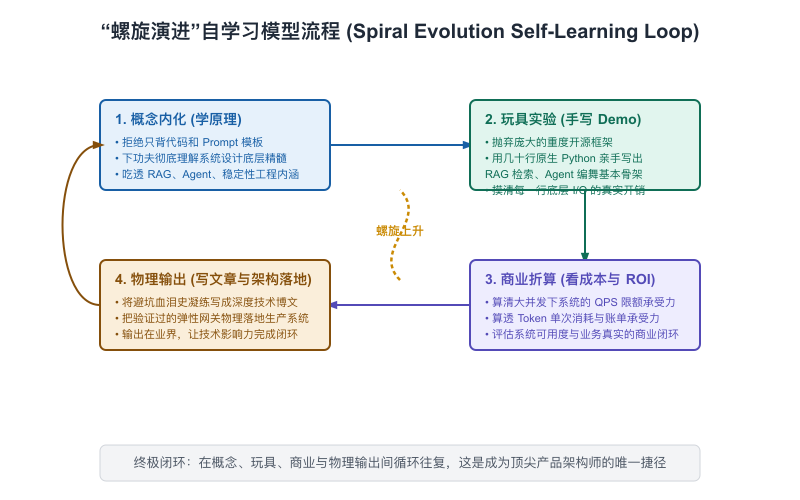
【图12-3】“螺旋演进”自学习模型流程
阶段一:概念内化(Durable Concept Internalization)
不满足于“看懂了”,用自己的话在小本子上,用一句话写出新技术的“日常生活类比”和“架构师决策含义”(就像我们在全书中每一章所做的那样)。如果一个概念你无法给出日常类比,说明你根本没有真正理解它的底层逻辑。
阶段二:30分钟极速动手实验(30-Min Toy Project)
不要一上来就搞宏大的系统。每学一个新概念(如“HyDE 假设性文档检索”),逼自己在半小时内,用 Python 或者是现成的 Jupyter Notebook 跑通一个最简的 MVP 脚本。
为了让你的动手实验不沦为散沙,我强烈建议你在个人的电脑里建立一个持久的“AI技术尖刺实验库(AIGC Spikes Kit)”,其目录结构建议如下,每次学到新概念,在半小时内丰富这个实验库:
/aigc-spikes/ # 你的个人自学习黄金武器库
├── Makefile # 统一的极速运行命令
├── spikes_env/ # 本地隔离的 python 虚拟环境 (Managed venv)
├── 01_prompt_compress/ # 第9章:基于 LLMLingua 的 Prompt 压缩实验
│ └── compress_test.ipynb
├── 02_semantic_cache/ # 第9章:基于 RedisVL 的向量相似度缓存实验
│ └── cache_spike.py
├── 03_hybrid_bge_m3/ # 第7章:BGE-M3 的稀疏-稠密多路检索实验
│ └── search_test.py
└── 04_agent_loop_breaker/ # 第8章:自杀熔断拦截器实验
└── circuit_breaker.py在跑通每一个 Jupyter 的那一个瞬间,你对技术的优点、缺陷和 trade-off 的理解,就会深深烙印在你的架构直觉里。
阶段三:产品化与商业价值折算(Business Translation)
一旦跑通了 Demo,立刻自问:“这个技术能解决我们公司哪个部门的什么痛苦?如果全量推广,它的算力费用和网络延迟大概是多少?我们该怎么在 L6 展现层设计人机交互卡片?”
将技术指标翻译成商业账本,这是成为顶尖产品架构师最核心的本能。
阶段四:物理输出(Physical Output & Teaching)
“教,是最好的学。”
逼自己将你这个星期学到的这个新技术,写成一篇 500 字的“极简科普短文”,发在公司的 Wiki 社区上;或者在下周五的团队例会上,申请 15 分钟的分享时间,用本书教给你的“场景-挑战-方案-决策-踩坑”的标准大厂汇报结构,向你的同事们讲明白。
为了让你的输出高密度且易于团队接受,我强烈建议你使用以下这套标准的“AI技术短文写作结构模板(Micro-blog Template)”:
# 标题: 【架构师视点】 5分钟搞懂 XXX 技术的工程边界
## 1. 它解决什么真实痛点(Scenario & Tension)
- 描述一个在生产环境中让人头疼的真实错误表现。
## 2. 底层物理原理是什么(Concept & Analogy)
- 用大白话和最通俗的日常生活类比(如考试、看书),解释其底层的算法/工程原理。
## 3. 核心决策 Trade-off 是什么(Architect's Trade-off)
- 详细计算它的物理代偿:它降低了什么?(如算力成本降了50%);它提升了什么?(如首字延迟增加了200ms)。
- 给出你作为总设计师的明确判定:什么场景下无条件用,什么场景下坚决不用。
## 4. 线上防身踩坑提醒(The Pitfalls)
- 至少列出一处它在线上可能会引发安全或高并发抖动的隐患,并给出防身兜底策略。当你在白板上画图给同事讲,并成功解答了他们针对“出了错怎么熔断”的质疑时,这个知识就彻底沉淀为了你终身受用的无形资产。
12.4 产品架构师的 AI 终身工具箱
工欲善其事,必先利其器。产品架构师并不需要安装几百个花哨的 AI 浏览器插件。你只需要以下五个稳定、免费且久经考验的物理生产力外挂:
1. 思考与草稿伙伴:Claude 3.5 Sonnet / ChatGPT
- 用途:
用来做架构方案的“红军/蓝军对垒测试(Red Teaming)”。 - 高阶用法:
你画完架构图后,把方案文字贴给它,输入这个 Prompt:“你是一个极其苛刻、眼里不揉沙子的技术 VP。你现在正在主持我的系统方案评审会。请针对我以下方案中关于高并发限流、RAG越权隔离、Fallback自愈熔断和语义缓存漂移这四个方面,提出 3 个最可能让我线上崩溃的漏洞,并要求我回答你的质疑。”
在接受它 3 轮无情的“拷问”后,你的方案在真实的专家评审会上就会变得无懈可击。
2. 代码开发与快速实验外挂:Cursor / GitHub Copilot
- 用途:
产品架构师也必须保持手感。利用 Cursor,你可以用自然语言在 10 分钟内写出我们第9章、第10章里提供的限流器和数据脱敏 Python 过滤器,并当场运行。 - 元原则:AI 负责在 3 秒内帮你生成所有的样板代码(Boilerplate),而你只负责最核心的数据流逻辑设计和关键决策审计。
3. 本地运行模型的终极利器:Ollama
- 用途:
了解模型尺寸、资源消耗与延迟直觉的“物理温度计”。 - 实战动作:
在你的 Mac 或电脑上,下载安装 Ollama 客户端。在终端直接运行带有--verbose(显示性能诊断信息) 的指令:ollama run qwen2.5:7b --verbose当我们输入提问生成完毕后,Ollama 会在控制台底部流式吐出如下的性能时序统计(Performance Metrics)。作为合格的架构师,你必须能读懂这些数字背后的“物理直觉”:
total duration: 1420ms load duration: 12ms prompt eval count: 32 tokens # 输入 Token 数 prompt eval duration: 180ms # 输入预处理耗时(计算 KVCache 耗时) eval count: 120 tokens # 输出 Token 数 eval duration: 1220ms # 输出推理总耗时 throughput: 98.36 tok/s # 核心指标:吞吐速度(每秒近 100 字)通过这 5 分钟的本地肉身感知,当以后开发同学向你抱怨“7B 模型高并发下服务器显存扛不住了”,你就能立刻在脑海中对所需的显卡张数(如一张 4090 或 A10G)产生最精准的架构直觉,而不是凭空瞎猜。
4. 搜索与行业调研外挂:Perplexity / 秘塔 AI 搜索
- 用途:
无痛过滤自媒体软文,一键寻找行业客观数据与论文出处。 - 实战动作:
不要再用旧搜索引擎去搜“什么是 RAG”,去 Perplexity 输入:“请客观对比 Reranker 模型中,Cohere-Rerank 与 BGE-Reranker 在中文评测集上的性能损耗和召回率差异,并给出学术界和工业界的论文/博客出处。”它会直接给你最干净的、带有角标引用的专业研究报告。
5. 本地语义检索与特征直觉外挂:Chroma / LanceDB
- 用途:
亲手感知“向量距离与语义相似度”物理关系的离线实验室。 -
实战动作:
在你的本地 Python 环境中,通过极简的几行代码,你就能在本地运行一个内存级向量数据库,亲手体验相似度阈值(如我们在第9.4节设定的0.96)在物理底层是如何计算出来的:import chromadb # 1. 初始化本地内存级 Chroma 客户端(不需要任何分布式数据库集群,极其轻量) chroma_client = chromadb.Client() collection = chroma_client.create_collection(name="local_quick_cache") # 2. 异步插入三条历史提问 collection.add( documents=["公司的深圳出差酒店报销标准上限是多少?", "请问怎么申请VP报销特批?", "如何清理C盘空间?"], ids=["doc_1", "doc_2", "doc_3"] ) # 3. 运行语义检索(Chroma 会在本地自动调用轻量级 Embedding 模型进行特征匹配) results = collection.query( query_texts=["我想去深圳出差,住宿费能报销吗?"], n_results=1 ) # 4. 打印召回结果与距离得分 print(f"最匹配的问题: {results['documents'][0][0]}") print(f"向量 L2 欧氏距离得分: {results['distances'][0][0]}") # 欧氏距离越接近0,代表语义越接近。通过在本地手动修改提问,观察 scores 的变动, # 你就能瞬间建立起“多大的语义差距对应多大相似度得分”的硬核架构直觉,彻底告别玄学调参。
12.5 产品架构师 30天快速行动进化清单
书本有终点,但你的进化之路没有终点。
为了防止“合上书本,生活照旧”的遗忘效应,我为你量身定制了一套“30天产品架构师快速行动清单”。请将这张表格截图保存、或者彩色打印出来贴在你的办公桌最醒目的地方,从下周一开始,完成你人生的“自进化跃迁”:
| 时间节点 | 核心任务 | 具体执行动作说明与量化产出目标 |
|---|---|---|
| 第 1 周:内化 | 绘制你自己的“架构速查表” | 将本书第二部分(第6-8章核心技能)和第三部分(第9-11章工程落地)的核心方法、公式,总结在一张 A4 纸上。这是你在评审会上的“防身符”。目标:完成一张高度浓缩、可单页双面打印的架构知识大图。 |
| 第 2 周:推演 | 人肉推演一个你工作中的真实需求 | 挑选你公司目前最痛的一个业务痛点。走一遍第10.2节的黄金四步法需求转化。写出你的需求转化卡片(Worksheet),在纸上画出分层架构图。目标:输出一份包含 L1-L6 分层设计和 3 个核心痛点转化 Worksheet 的顶层方案底稿。 |
| 第 3 周:肉身感知 | 运行你的第一个本地大模型 | 在你的个人电脑上安装 Ollama,并运行 Qwen 或 Llama。连续向它提问 10 个问题,观察、记录并手感体验 TTFT 延迟、显存占用和生成卡顿的物理界限。目标:完成一本关于本地 7B 模型并发延迟和吞吐(tok/s)实测的本地实验笔记。 |
| 第 4 周:输出倒逼 | 完成你的第一次团队公开技术分享 | 向你的组长或团队申请一次 30 分钟的 Friday Sharing。利用本书的 L1-L6 分层骨架和 10 大架构决策清单,讲解你第二周推演出的那个业务方案。目标:收获 5 个以上开发同学的真实反馈问题,并回答他们的熔断和合规安全质疑,用输出完美闭环输入! |
全书闭环总结:送别礼物,去成为那个画第一根线的人
写到这里,我的手指在键盘上敲下了最后几个字。
在这本《大模型与AIGC全栈认知:产品架构师的学习笔记》里,我们一起经历了一场漫长、厚重而又充满挑战的技术长征:
- 我们从大模型的逻辑起源开始(第一部分:第1-5章),探寻了 Next Token Prediction 的本质,打破了对 Emergence(涌现)的玄学迷信,建立起了冷冰冰但客观科学的“不可能三角”成本意识。
- 我们深入底层,打磨了提示词四要素(第6章)、攻克了安全 ACL 动态过滤的 RAG 水平级联(第7章)、亲手设计了防无限死循环的 Agent 挂起状态机(第8章)。
- 我们最终跨入钢铁丛林(第三部分:第9-11章),在流量治理、分布式 Tracing 可观测性、语义缓存削减 90% 算力开销、DLP 敏感匿名化脱敏中,体验了生产化高并发大流量的洗礼。并最终提炼出了一套科学的“四步法转化框架”和“6周黄金项目甘特图”。
读完这本书,你已经不是一个对 AI 充满狂热和迷信的技术追随者了。你已经是一个手握重炮、心有边界、在不确定的大模型地基上构建确定性高可用商业系统的“殿堂级总设计师”了。
在这本笔记的最后一页,我想分享一个我深信不疑的职业信念:
在 AIGC 的惊涛骇浪中,平庸的系统随波逐流,它们拼凑着市面上的各种开源玩具,最终在生产网并发的巨浪和安全审查的礁石上撞得粉碎。
而伟大的产品架构师,则能在滔天的未知海浪前,极其冷静地掏出尺子,测量海水风向的流速,无情地计算着算力和 Token 的边际成本。他们会极其高傲、极其理智地在白纸上,画下第一根界定人类智慧与概率机器的物理隔离线。
这张白纸,现在已经在你的案头铺开。CTO 已经在门外等候。
去吧,跨出书本,迈向你真实的战场。
去在白纸上,画下属于你自己的、改变世界的“第一根线”!
本章小结
这一章,我们完成了本书最温情、也最赋能的完美终章。我们没有谈复杂的算法细节,但我们看清了如何在瞬息万变的技术红皇后领地里,锚定自己终身竞争力的秘密通道。
本章核心要点:
- 分清知识生命周期是防止焦虑的前提:将 80% 的时间精力倾注于基本原理、Trade-off 系统思维、可观测度量学等“5年以上不倒的持久地 foundations”上;而把模型排行、工具库具体 API 等“短命知识”降级为做项目时的速查配角。
- 三层过滤网过滤科技噪音:建立每日 ArXiv 源头学术、每周知名工程 Blog、每月主流厂商 API 定价的三层信息分层过滤器,用“灵魂三问判定法”无情撕碎伪技术和商业公关秀(PR)的包装。
- 螺旋演进法是唯一的自进化捷径:拒绝无痛的“看懂了”,坚持概念内化 → 30分钟玩具 Demo 实验 → 商业算力成本折算 → 水平物理输出(写文章/授课)的四阶段闭环沉淀。
- 架构师的口袋里要装有物理温度计:熟练运用 Claude 蓝军拷问方案漏洞、使用 Ollama 本地跑 7B 模型感知高并发延迟和显存占用的真实物理直觉。
- 30天行动计划开启跃迁之旅:通过第 1 周速查表、第 2 周四步法推演、第 3 周 Ollama 实操、第 4 周 30分钟团队分享,将书本中的散装技能真正转化为你不可被剥夺的 category authority。
延伸阅读
- 《The Batch》by Andrew Ng(https://www.deeplearning.ai/the-batch/)—— AI 领域公认质量最高、最客观清醒的工程与商业落地 Newsletter。每一期吴恩达老师亲自撰写的 editorial 点评都极具产品架构师的全局启发。
- Karpathy's Blog & YouTube:《Intro to Large Language Models》(https://karpathy.ai/)—— 前 Tesla Autopilot 负责人、OpenAI 联合创始人 Andrej Karpathy 制作的、被誉为 AIGC 领域最震撼最底层的科普视频与博客,是每个架构师构筑“持久知识基础”的必看课程。
- LLMLingua 官方技术白皮书(https://llmlingua.com/)—— 微软亚洲研究院发布的关于如何用小模型计算语义熵进行 Prompt 压缩的技术细节,阅读它能帮你对“什么是无用文本、什么是高熵信息”产生最深刻的信息论直觉。
- 《Aigc Observability: Emerging Best Practices for Tracing LLM Chains》(https://opentelemetry.io/blog/)—— OpenTelemetry 社区关于如何在分布式微服务环境下部署 AI 调用链分布式追踪(Tracing)、Span 设计和 TTFT 延迟抓取的最新最佳实践指南。