学习笔记-AIGC全栈认知与落地(10)
第10章 · AI产品架构方法论——如何主导一个AI系统的设计
开场:白纸一张,这就是你成为架构师的终极考验
在产品架构师的职业生涯中,最令人兴奋也最让人焦虑的时刻,莫过于面对一张白纸。
那是2025年底,我的一位前同事——他当时在一家头部大型集团担任技术负责人——突然面临了公司要成立一个横跨所有业务线的“AI 赋能技术平台(Enterprise AI Hub)”的宏大考验。这个项目的目标极其宏大,也极其模糊:要支持客服部门降低 40% 的人力成本、帮法务部门实现合同秒级合规审查、帮开发团队自动定位并生成漏洞修复代码,还要在全公司推广 AI 编程助手。
作为这个平台的架构总负责人,CTO 给他的启动指令极其冷酷且只有一句话:
“给你 6 周时间。我需要看到一套能够统一支撑起全公司这些不同 AI 业务的顶层架构方案。不仅要画出技术盒子,还要说清楚模型怎么选、算力怎么省、安全红线怎么保,以及我们怎么一步步落地验证。6 周后的集团技术执委会(TC)会议上,你要向全体合规官和技术 VP 汇报。”
当他来找我喝酒,聊起当他回到座位、打开空白的电脑文档时,他说那种巨大的虚无感和压迫感简直要让人窒息。
在过去的几个月里,我们学会了写优雅的提示词(第6章),学会了搭安全稳健的 RAG(第7章),甚至手写了精妙的 Agent 状态机(第8章),并且在生产网架设了限流熔断的流量网关(第9章)。
但是,当你面对一个如此庞大、复杂的企业级混沌需求时,你该从哪里画第一根线?你该怎么让法务、客服、开发这些完全不同的业务共享同一套算力底层?怎么向老板证明你的高昂预算是合理的、系统是稳定的?
我见过太多优秀的研发人员和产品经理,在面对这个考验时败下阵来。
- 技术派的常见死法:直接陷入局部技术细节。一上来就跟业务讨论是用 PGVector 还是 Milvus,是用 Llama-3 还是 Qwen-2.5,结果被法务部门质疑数据出海合规、被财务部门质疑算力预算,最后方案因为缺乏商业可行性被无情枪毙。
- 产品派的常见死法:画了一堆精美但虚无的 PPT,写满了一套套“AI 赋能”的口号,却说不清系统在高并发下怎么熔断、多步骤决策失败怎么自愈、如何接入企业现有的 ACL 权限体系。最终被技术 VP 评价为“空中楼阁,无法落地”。
主导一个 AI 系统设计的核心,绝不是“画盒子”,而是在高度不确定的模型边界上,为企业推演出一套科学的、可重复的决策路径和确定性的架构边界。
这一章,我将把我主导大厂百余次 AI 系统顶层设计时沉淀下的“四步法需求转化框架”、“十项核心架构决策清单”、“三层效果评估体系”以及“6周黄金落地节奏手册”毫无保留地交给你。带你跨越从“技能工匠”到“顶层总设计师”的终极台阶。
10.1 AI 系统的特殊性:为什么传统软件方法论不够用
在画第一张架构图之前,作为总设计师,你必须在脑海中建立起一个深刻的认知:AI 系统不是传统的 IT 系统,生搬硬套传统的软件架构方法论,只会让你南辕北辙。
我们通过下面这张图,来看清传统软件与 AI 系统在底层逻辑上的根本性分歧:

【图10-1】传统软件与 AI 系统三大特殊性对比
我将这种特殊性总结为三个底层分歧:
1. 从“确定性”到“概率性”:不确定性边界的设计
- 传统软件:代码是确定性的。逻辑分叉靠
if-else。如果输入合规,输出的格式和内容在 100% 的情况下是稳定的、可预测的。 - AI 系统:模型的输出是概率性的(Next Token Prediction)。即便你把温度(Temperature)设为 0,多轮对话下的注意力累积依然会产生微弱的语义偏移。
- 产品架构师的思维转变:传统架构师的目标是“100% 消除异常并实现预期功能”;而 AI 架构师的目标是“接受模型会出错、会产生幻觉的前提,在系统外围设计严密的防御红线与柔性降级(Graceful Degradation)边界”。你要设计的不是一个“绝不犯错的上帝”,而是一个“犯了错也会被系统机制完美兜底的安全网”。
2. 从“系统可用性”到“用户满意度”:效果度量的升维
- 传统软件:服务可用性(Service Availability)指标极其简单:QPS 达到多少、CPU 占用率低于 70%、接口 HTTP 200 占比 99.9% 就算成功。
- AI 系统:即便你的后台服务器接口 100% 返回了 HTTP 200,但如果大模型吐出的是一句毫无用处的胡言乱语,或者产生了一次严重的涉政违规,对于用户和业务来说,你的系统可用性依然是零。
- 产品架构师的思维转变:你必须跳出“纯技术指标监控”的旧框框,将语义准确度(Semantic Accuracy)、幻觉率、首字响应延迟(TTFT)以及用户流失率作为系统的第一核心指标,建立起一套“算法-工程-产品体验”三位一体的全新度量模型。
3. 从“一次性交付”到“持续进化”:数据飞轮的构建
- 传统软件:系统上线、通过了回归测试,项目的核心研发期就结束了,后续进入被动的运维期(Bug Fix)。
- AI 系统:上线的那一天,才是系统生命周期的刚刚开始。真实的线上用户输入(用户提问的真实分布、真实犯错案例)是稀缺的黄金资产。
- 产品架构师的思维转变:你必须在第一天就把“数据飞轮(Data Flywheel)”写进架构图中。你需要设计自动化的机制:如何收集点踩的数据、如何异步清洗这些数据、如何用这些真实世界的负反馈去驱动下一轮的 Prompt 调试、RAG 优化和模型微调。不能持续进化的 AI系统,在上线那一刻起就已经在被时代淘汰了。
10.2 从用户问题到系统架构:黄金四步法需求转化框架
面对白纸,你该如何开始?
我在大厂最常用的、也是最稳固的设计框架是“四步法需求转化框架”:
[ Step 1: 用户问题拆解 ] ──► [ Step 2: AI 能力需求转化 ] ──► [ Step 3: 技术方案选型 ] ──► [ Step 4: 顶层系统架构设计 ]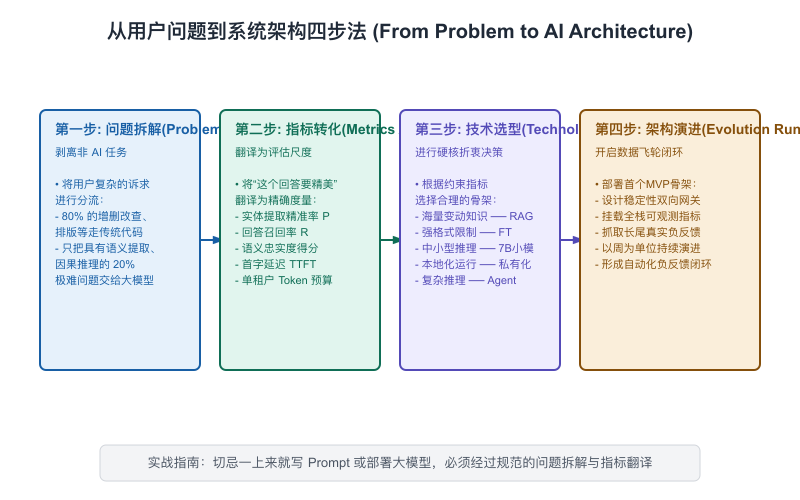
【图10-2】从用户问题到系统架构四步法
Step 1:用户问题拆解(User Workflow Deconstruction)
千万不要一上来就问业务“你们想怎么用 AI”,大部分非技术业务人员给不出科学的回答。
正确的做法是:隐去 AI 这个词,人肉观察并解构他们当下的真实工作流(Workflow)和认知负荷(Cognitive Load)。
通过与退款审核运营同事一起工作,我整理出了他们当下的工作步骤:
- 接收申请:在后台接收用户的退款小作文。
- 事实检索:去 ERP 系统查订单详情、去客服系统看历史聊天记录、去物流系统查快递状态(耗时最长,需要在 3 个系统间来回切窗口,这是第一核心痛点)。
- 规则评判:核对“退款标准手册”(例如:超过 7 天了吗?外包装破损了吗?历史退款频次高吗?)。
- 人工决策:符合标准,点击【同意退款】按钮,后台调用退款接口。不符合,人工手写退款拒绝信发给用户(这是第二核心痛点,手写信耗时极长且容易引发用户情绪对立)。
Step 2:AI 能力需求转化(AI Capability Mapping)
在看清工作流后,我们需要将这些口语化的、繁琐的业务动作,翻译成标准的、机器可读的 AI 技术需求卡片(Worksheet):
为了让大家理解这套转化机制的普适性,我不仅列出了上述“智能客服退款”的案例,还补充了另外两个我们在大厂极高频遇到的企业级硬核场景——“法务合同审查”与“IT故障自愈”:
场景 A:智能客服自动退款判定
| 业务动作步骤 | 人类认知瓶颈与痛点 | 对应的 AI 任务类型 | 具体的 AI 能力需求 | 核心技术选型范围 |
|---|---|---|---|---|
| 读取申请与历史 | 用户退款申请极其冗长,含有大量发泄性废话 | 文本摘要(Text Summarization) | 提取用户退款的根本诉求和争议核心点 | Prompt 结构化指令 + Few-Shot |
| 多系统检索 | 需要在多系统检索订单、物流与历史退款政策 | 检索增强生成(RAG) | 精准检索差旅、退款手册及该用户的 CRM 属性 | 向量混合检索(Dense+BM25) + 动态权限 ACL |
| 规则匹配判定 | 对比复杂的多条件规则,极易产生人工漏看 | 逻辑推理(Reasoning) | 自动比对物流状态与退款准则,给出合规性判定 | 高阶 Reasoning 大模型(如 Qwen-Max 或 GPT-4o) |
| 退款动作执行 | 手写拒绝信效率低;直接划扣具有高副作用风险 | 工具执行(Agent Calling)+ 文本生成 | 自动生成不合规拒绝信草稿;准备划扣参数 | Function Calling + Human-in-the-loop 审批 |
场景 B:法务合同合规审查
| 业务动作步骤 | 人类认知瓶颈与痛点 | 对应的 AI 任务类型 | 具体的 AI 能力需求 | 核心技术选型范围 |
|---|---|---|---|---|
| 条款提取 | 上百页的合同,条款极度冗长,人工寻找特定免责条款极其耗时 | 信息抽取(Information Extraction) | 精准定位并提取买卖双方、争议管辖权、违约金上限等核心要素 | 结构化 JSON Schema 输出约束(第6.2节模式) |
| 合规性比对 | 逐条比对合同条款是否符合集团法务制定的“黄金合规标准书” | 语义相似度 + 逻辑判断 | 判断合同条款与集团标准条款是否存在逻辑冲突(如付款账期是否超标) | 知识图谱关联检索(Graph RAG) + 高阶推理模型 |
| 漏洞修补与撰写 | 发现违规条款后,人工重新起草合规替代条款并写明驳回批注 | 文本生成(Text Generation) | 针对不合规条款,自动生成既符合我方利益又在法理上说得通的修改建议 | RAG 召回标准替代条款 + 针对性 System Prompt |
场景 C:IT 运维故障自愈
| 业务动作步骤 | 人类认知瓶颈与痛点 | 对应的 AI 任务类型 | 具体的 AI 能力并发 | 核心技术选型范围 |
|---|---|---|---|---|
| 日志异常诊断 | 生产环境每秒产生数万条日志,人工定位根因大有大海捞针 | 模式识别(Pattern Recognition) | 从庞杂的报错日志中识别出核心报错信息(如 OOM、DB死锁) | 异步 Batch 批处理分析 + 专有小模型提取分类 |
| 故障库关联检索 | 查找历史有没有类似故障的处理记录(Runbook) | 语义检索(RAG) | 快速找回历史上处理过当前报错代码的 Wiki 或 Checkpoint 手册 | Hybrid Search + Reranker 重排序(第7.3节) |
| 自愈脚本执行 | 找到了处理预案(如重启服务、扩容),需手动写脚本并在终端运行 | 代码生成与执行(Agent Code Interpreter) | 自动组装安全的 Shell/Python 重启脚本,并在沙箱环境中测试运行 | Agentic Code Interpreter + 关键节点人工点击确认 |
典型的新手错误:我第一次做这种转化时,试图用一个大模型把这四步一次性做完。结果模型在处理复杂的退款手册和多系统数据时,顾此失彼,格式崩溃,拒绝信里经常胡说八道。后来我明白了一个道理:在架构设计上,必须将复杂的长链路解耦为多步串联或并联的微任务(Micro-tasks),每一个微任务只用最适合、成本最低的模型和 Prompt 去解决。
Step 3:技术方案设计(Technical Path Selection)
有了技术需求卡片后,我们要对核心架构路径进行判定。你可以利用我为你梳理的这个“AI 架构师路径判定决策树”:
[ 核心问题:新知识更新频繁吗?]
│
┌────────────────┴────────────────┐
▼ (是) ▼ (否)
[ 需要高可解释性吗?] [ 核心诉求是输出特定格式吗?]
│ │
┌─────────┴─────────┐ ┌─────────┴─────────┐
▼ (是) ▼ (否) ▼ (是) ▼ (否)
【 RAG 】 【 超长上下文 】 【 领域微调 】 【 提示工程 】
│ │
▼ ▼
[ 需自主多步执行? ] [ 需自主多步执行? ]
- 是: 【 Agentic RAG 】 - 是: 【 规划 Agent 】
- 否: 【 标准 RAG 】 - 否: 【 单模型调用 】在我们的“AI 智能退款平台”案例中,判定逻辑如下:
- 退款政策和订单数据变化极快(秒级更新)→ 锁死 RAG 路线;
- 输出必须能够明确展示退款依据,便于合规审计 → 锁死标准 RAG 并配置引用追溯;
- 系统不仅要答,还要自动调用退款接口(有副作用的动作) → 锁死 Agentic RAG + Human-in-the-loop 关键节点审批。
Step 4:系统架构设计(High-Level System Design)
根据前面三步的推导,现在我们可以非常自信地在白纸上,画出这套系统标准的 L1-L6 分层企业架构图。
为了向技术执委会清晰证明这套架构在实际执行时的流转效率,我们必须能够向高管们系统讲解“一个提问在系统中的数据流转 Trace 生命周期(Data Flow Trace)与各层边界载荷(Payload)”:
真实数据流的 L1-L6 穿梭之旅:
- L6 展现层启动:
用户在客户端输入提问并发送:// L6 输入 Payload { "user_id": "usr_asarshen", "session_id": "sess_991823", "user_input": "我5月出差深圳的酒店超标了,金额为850元。我的手机是13812345678。这单能报销吗?" } - L5 编排层截获并初始化状态机:
Agent 编排引擎启动一轮 Session 事务状态机。编排引擎开始调用 L3/L4 层的能力卡片。 - L3 流量网关前置脱敏与拦截:
请求在流向大模型前,必须经过 L3 Gateway。DLP 过滤器(DLPManager)执行正则和命名实体匹配,将用户输入的手机号脱敏:// L3 脱敏后的传输 Payload { "user_id": "usr_asarshen", "user_input_masked": "我5月出差深圳的酒店超标了,金额为850元。我的手机是[PHONE_MASK_0]。这单能报销吗?", "token_map": {"[PHONE_MASK_0]": "13812345678"} }同时,双令牌桶限流器(Rate Limiter)检查当前 TPM 额度,确认安全,放行。
- L4 缓存拦截与 RAG 召回:
- 首先检索 L4 语义缓存(SemanticCacheManager),未命中。
- 编排引擎发起 RAG 混合检索:首先去 L2 层的 PostgreSQL 数据库查询用户
usr_asarshen的当前部门与安全标签。 - 将查询到的权限标签
{"department": "cloud_architecture", "clearance": "level_3"}作为 Metadata Filter,向 L2 的 Milvus 向量库发起带有 ACL 权限硬拦截的语义检索。 - 召回子文档:“深圳及北京一线城市协议酒店上限为每天600元。”
- 通过父文档 ID 回捞大落:“第4章 住宿标准。4.1 境内一线城市(深圳、北京)上限为每天600元。若因重大展会超标,需部门VP在系统内特批...”
- 利用“U型注意力曲线”重排序拼接 Prompt,并注入严格的“幻觉引用红线规则”。
- L1 算力层生成:
拼装好的高密度 Prompt 被投递给 L1 的高阶大模型,模型在 1200ms 内流式生成了高度精准、带有引用标记的退款依据说明。 - L3/L6 安全过滤与呈现:
大模型流式吐出的 Answer 字符流在流经 L3 流量网关时:- 还原敏感信息:根据
token_map自动将[PHONE_MASK_0]物理还原为13812345678; - 双向内容过滤:内容过滤引擎进行毫秒级敏感词检测,确认绿色合规。
- 前端打字机渲染:最终在 L6 客户端以丝滑的 Stream 传输和打字机特效向用户吐出。
- 还原敏感信息:根据
10.3 关键架构决策清单(Ten Core Architectural Decisions)
在方案评审阶段,技术 VP 和架构专家会像寻找猎物一样盯着你的方案,寻找设计的漏洞。
为了保证你的方案无懈可击,在撰写方案时,你必须在心中逐一核对并回答这 10个核心架构决策。每一个决策,都代表了一个经典的系统 Trade-off:
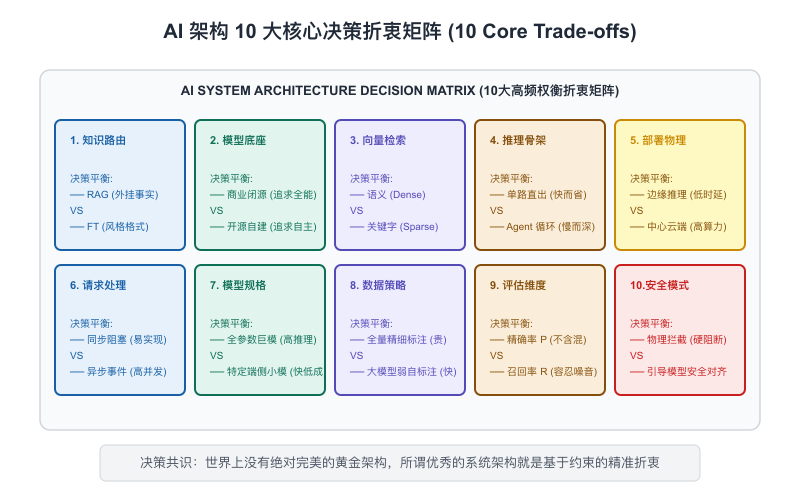
【图10-3】AI 架构 10 大核心决策矩阵
决策 1:闭源公有云 API vs 开源私有部署
- 权衡核心:安全与费用的长周期折算。
- 许多团队在算这笔账时只看单次请求的 API Token 价格。但作为总设计师,你必须从三年整体拥有成本(3-Year TCO)的角度去推算。
【公有云 API 财务公式】:
TCO_Cloud = 每日查询量 × 平均单次消耗 Token × Token单价 × 365天 × 3年【本地私有部署 财务公式】:
TCO_Private = 8卡GPU服务器采购费 + 机房电费与带宽(3年) + 2名专职运维年薪(3年) + 基础模型授权费根据我们的实测数据:若企业每日大模型调用量低于 10 万次,100% 应该走云端 API 配合 DLP 脱敏网关,因为此时采购服务器的固定资产折旧(CapEx)极不划算;只有当企业每日大模型调用量突破 50 万次、且核心业务线被法律法规明文禁止数据离境时,私有化部署 H80G 或 A800 算力集群才会在第 18 个月达到财务平衡拐点(Breakeven Point)。
决策 2:知识路径:RAG vs 微调 vs 超长上下文
- 决策标准:如果你的知识库需要秒级/天级频繁更新,且你需要答案带有清晰的引用出处,100% 走 RAG。只有当你的知识库绝对静态(如医学古籍、法律文书格式规范),且你的核心需求是改变模型的输出格式或语法风格时,才考虑微调。
- 高阶混合设计:在很多大厂高并发大项目中,我们通常设计 “RAG事实检索 + 微调格式塑造”的双轨混合架构。我们并不强求用 RAG 去教模型认识行业专有词汇,也不强求用微调去让模型记住实时的产品定价。而是通过微调让模型 100% 稳定输出特定格式的 Markdown 和 JSON(防止格式在并发时漂移),而在推理时,用 RAG 往这个高精格式骨架里填充实时事实知识。这才是业界最优雅的高阶架构设计。
决策 3:用户体验的底线:同步(Sync)vs 异步(Async)
- 同步接口(Real-time Streaming):用户等在屏幕前,必须使用 SSE(Server-Sent Events)流式打字机输出。TTFT(首字延迟)必须控制在 1 秒以内。
- 异步任务(Batch Job):对于复杂的 Agent 任务(需要执行 10 步、调用多次爬虫和数据库),严禁使用同步等待。必须在后端使用 Celery/Kafka 等消息队列将任务挂起,前端通过进度条渐进式展示执行状态(“正在分析第3个页面...”),并在完成后通过企业微信或系统弹窗向用户推送结果。
决策 4:协作拓扑:单 Agent vs 多 Agent(Multi-Agent)
- 中心化控制(Orchestrator-Workers):适合任务目标极度明确,且需要严格、按部就班地由上而下分发和审计的流程(如:发票信息识别后自动填报财务表单)。
- 去中心化事件总线(Event-driven Choreography):适合高复杂度、跨领域的深度协同(如我们的“安全合规代码生成团队”,让 PM、Coder、Reviewer 拥有完全对等的通信地位,能实现多轮、自发的碰撞纠错)。
决策 5:人机协作红线:AI 自主执行 vs 人工关键节点审批
- 决策标准:根据“副作用风险等级(Side-effect Risk)”。任何具有真实世界物理写操作、涉及真实资金流转、涉及对外发布公开舆论的工具调用,必须在 L6 端强加 Human-in-the-loop 人工审批卡片。严禁将不可逆的高危物理执行权完全托付给概率性决策的大模型。
-
挂起状态机设计(The Hanging State Machine Pattern):在工程上,实现“关键节点审批”千万不能让 Web 服务器线程原地挂起等待(会耗尽系统连接池导致崩溃)。
我们的核心架构模式是异步挂起状态机:当 Agent 规划出一步高危操作(如“执行退款”)时,Agent 编排引擎会将当前 Session 序列化,把状态以
STATUS_PENDING_APPROVAL写入 Redis 缓存,同时释放当前 Web 执行线程。系统通过企业微信接口向部门 VP 派发一张带有“同意/驳回”按钮的交互式卡片(Interactive Card Webhook)。当 VP 点击同意后,微信服务器发送 Webhook 回调我们的 API,API 重新从 Redis 中反序列化读取该 Session 状态,将其唤醒(Resume),并调用真实的物理划扣接口。这才是高可用的软件工程设计。
决策 6:极致成本优化:单一大模型 vs 大小模型并联分流(Cascade Routing)
- 决策标准:不能让高阶模型处理所有流量。在 LLM Gateway 层必须设计前置意图分类器。将 60% 以上的简单日常对话、闲聊和格式转换路由到 7B-13B 的开源小模型;只有 40% 需要高维推理的任务才放行给千亿参数的高阶大模型。
决策 7:数据主权:企业 ACL 权限物理隔离设计
- 决策标准:拒绝无状态的裸搜索。向量数据库底层的切片必须和企业统一的 IAM(身份权限访问管理系统)进行双向解耦,利用元数据过滤(Metadata Filtering)将用户的实时权限令牌注入检索请求,从物理底层确保越权隔离。
-
LDAP 树形权限扁平化解耦设计:企业内的权限通常是树形层级结构的(例如:张三属于
总办 -> 秘书处 -> 一组,他天然继承了上面所有父级节点的文档权限)。在向向量数据库发起检索时,我们绝不能让向量库去实时遍历这棵树(性能极差)。正确的架构设计是:在用户请求到达网关时,由 IAM 拦截器实时把张三所在的 LDAP 树进行“水平展开与扁平化(Flattening)”,把张三所有继承到的用户组、角色、以及他个人的特殊白名单,水平序列化为一个扁平的标识符列表(如
["dept_groups": ["total_office", "sec_office", "group_one"]]),作为元数据过滤的$in数组,一次性投入向量库扫描。这保证了高并发下的极速权限响应。
决策 8:系统的退路:优雅降级与熔断机制(Fail-Safe Design)
- 决策标准:当 L1 层的核心模型厂商服务全线崩溃、或者你的账号被厂商判定为 429 速率限制时,系统怎么活下去?你必须在网关层配置自动 Fallback。降级路线:高阶公有云 → 备用公有云 → 备用本地 7B 小模型 → 本地硬编码缓存友好提示。
- 熔断器状态转换(Circuit Breaker State Machine):我们在 LLM Gateway 中,为每一个模型提供商通道都配置了标准的熔断状态机:
| 状态 | 触发判定标准 | 路由动作 | 恢复判定标准 |
|---|---|---|---|
| CLOSED(通道正常关闭) | 连续失败次数 < 3 次 | 正常路由 100% 流量 | 无需恢复 |
| OPEN(通道熔断打开) | 连续失败次数 ≥ 3 次(抛出 429 / 503 / 超时) | 物理拦截,不向该通道分发任何流量,直接回退(Fallback)到下一备份路由。 | 保持熔断状态 600 秒(10分钟)后,自动转换为 HALF_OPEN 状态。 |
| HALF_OPEN(半开状态) | 10分钟惩罚期满,自动切入 | 分发 5% 的测试探测流量给该通道。 | 若 5% 流量调用 100% 成功:状态自动恢复为 CLOSED; 若产生任何一次失败:状态重新恶化为 OPEN,重置 10分钟 惩罚钟。 |
决策 9:数据飞轮的起点:用户点踩(Negative Feedback)的自动捕获
- 决策标准:大模型没有自主进化的能力,你必须帮它建飞轮。任何在线上收到用户“点踩”或者“差评”的对话,系统必须在后台秒级触发一个“快照动作(Snapshot)”:将这轮对话的 User Input、RAG Context、Generated Answer 以及 System Prompt 完整打包,发送到离线的 LLMOps 评测数据集中,作为算法工程师每周一首要分析并用于微调的黄金训练资产。
决策 10:合规生死线:敏感内容安全(Moderation)的双向拦截
- 决策标准:不能只管入,不管出。必须配置双向拦截中间件。输入端防御 Prompt 注入和敏感词汇;输出端在流式传输流中进行毫秒级敏感词检测,确保违规内容在吐给用户前的第 1 毫秒就被网关硬性掐断(Break Stream Connection)。
10.4 三层效果评估体系:如何客观衡量 AI 系统的智商
在方案答辩和上线后的效果汇报中,你一定会面临这样的挑战:
“亚哥,你说你优化了系统的 Prompt 和 RAG,那么你怎么证明现在的版本比上个星期好?”
“我们有 10 万个用户,他们每天问的问题五花八门,我们怎么知道系统在线上的真实生成表现?”
回答这些问题的唯一路径,是搭建“三层效果评估体系(Triad Evaluation Framework)”。
传统软件测试依赖于硬编码的“单元测试(Unit Tests)”。但在 AI 系统中,因为输出是随机的、概率性的,我们必须引入一套基于黄金测试集、大模型裁判(LLM-as-a-Judge)以及在线 A/B 测试的科学度量体系:
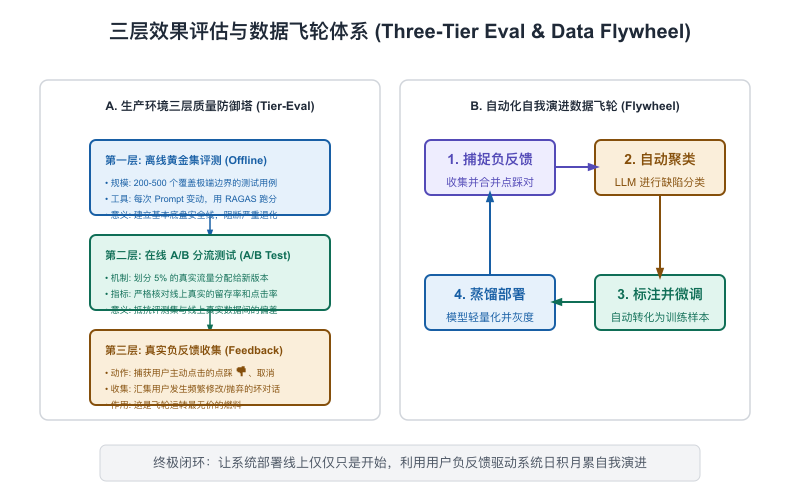
【图10-4】三层效果评估与数据飞轮体系
第一层:离线基准评测(Offline Golden Benchmark)
这是系统的第一道防线。在系统正式合并代码或上线前,必须在离线环境中通过基准测试。
- 构建黄金测试集(Golden Dataset):
由业务专家、产品经理和算法工程师,共同人工编写并整理一个包含至少 200-500个 典型用户提问的测试集。每一个测试用例包含三个核心字段:Query:用户的典型真实提问;Reference_Context:人工确认的、回答该问题所需要的标准内部参考文档段落;Ground_Truth:由业务专家人工撰写并确认的最完美的标准答案。
- 自动化打分机制(LLM-as-a-Judge):
除了 Ragas 指标,针对企业特定的定制化业务需求(例如:审查回复是否带有推荐竞品的倾向、是否违背了客服亲和力标准、有没有输出特定的敏感信息),我们必须自己配置 G-Eval(基于长思维链裁判模型的定制评测机制):
# G-Eval 裁判评估提示词模板:客服亲和力与格式合规打分
你是一个极其严格的企业服务质量合规官。你需要对 [大模型生成的回答] 进行 1 到 5 分的打分。
# 评分标准
1分 - 回答冷冰冰,包含了硬编码的机器报错,或者完全没有使用礼貌用语。
2分 - 态度勉强合规,但没有主动引导和安抚用户的语句。
3分 - 态度良好,正确解答了问题,使用了“您好、谢谢”等标准礼貌词,格式合规。
4分 - 态度热情,在3分的基础上,主动对用户可能遇到的关联问题(如退款失败后的VP特批流程)进行了前置温馨提醒。
5分 - 态度极佳,完美展现了企业共情能力,在4分的基础上,针对点踩或投诉表现出高度真诚的歉意,并给出了明确的线下人工服务电话。
# 评估输入
---
[标准事实 Ground Truth]
{ground_truth}
[参考文档 Context]
{context}
[大模型生成的回答 Answer]
{answer}
---
# 评分要求
请在你的大脑中执行 Chain-of-Thought(思维链推理),一步步写下你的分析过程,最终以严格的 JSON 格式输出打分和原因:
{
"thought_process": "首先,我注意到生成回答中...",
"score": 4,
"reason": "该回答不仅解答了报销规则,还主动指引了超标时的特批路径,非常贴心。但缺乏5分要求的共情歉意。"
}- 合并准入红线(Gatekeeping Rule):
在 CI/CD 流水线中,只有当新版方案的 Ragas 综合得分不低于旧版本,且没有产生任何核心指标抖动时,代码才允许合并通过。这彻底消除了“拍脑袋决定上线”的原始作风。
第二层:在线灰度 A/B 测试(Online Canary A/B Test)
任何黄金数据集都无法 100% 模拟真实世界中千奇百怪的用户输入。所以,新版系统在通过第一层离线基准测试后,必须走灰度分流测试。
我们在 A/B 测试中,为了防止由于偶然的流量抖动导致的误差,必须引入假设检验(Hypothesis Testing)中的 P值(P-value)统计学计算,确保版本B的获胜绝非偶然:
# 验证 A/B 测试两组点踩率差异的显著性(双样本比例 Z 检验)
import numpy as np
import scipy.stats as stats
def calculate_ab_test_p_value(clicks_a, clicks_b, sample_size_a, sample_size_b):
"""
clicks_a: 版本A在线收到的总点踩次数
sample_size_a: 版本A总请求样本数
"""
p_a = clicks_a / sample_size_a
p_b = clicks_b / sample_size_b
# 综合比例
p_combined = (clicks_a + clicks_b) / (sample_size_a + sample_size_b)
# 计算 Z 统计量
se = np.sqrt(p_combined * (1 - p_combined) * (1/sample_size_a + 1/sample_size_b))
z_stat = (p_a - p_b) / se
# 计算双尾 P 值
p_value = 2 * (1 - stats.norm.cdf(abs(z_stat)))
# 判定统计显著性(α 设为经典的 0.05)
is_significant = p_value < 0.05
return p_value, is_significant
# 只有当 is_significant 为 True 且 p_value < 0.05 时,
# 我们才允许在技术报告中得出“版本B的效果在统计学上显著优于版本A”的硬核结论。第三层:用户负反馈数据飞轮(Negative Feedback Loop)
这是系统实现自我进化、跨越 session 局限的核心闭轮。
- 快照收集:一旦线上用户点击了“点踩(Dislike)”按钮,或者在对话中表现出愤怒情绪(输入了辱骂性词汇),后端系统立即将该用户的当前会话上下文打包。
- 异常归因(Semantic Anomaly Grouping):利用一个异步的小模型,每天对这些负反馈快照进行语义聚类(比如:今天有 30 个点踩案例都指向了“401数据库无法连接”或者“退款额度计算错误”)。
- 定向注入与回归:
根据聚类后的最高频错误原因,架构师定向修改 Prompt,或者算法工程师定向微调模型。修改后的方案会产生 20 个新用例注入到第一层离线黄金测试集中,防止未来再次犯错,完成数据飞轮的闭环运转。
10.5 项目落地节奏:产品架构师的 6周黄金实战指南
很多高管对 AI 项目的期望值是“今天提需求,下个星期就要看效果”。作为项目总设计师,你不能被这种非理性的狂热打乱阵脚,更不能慢吞吞地按照传统瀑布流开发磨蹭半年。
为了让你的团队能够在 6 周内高效、敏捷、无故障地将一个庞大的 AI 系统推向生产线,我将各岗位的协同分工矩阵(RACI)和每周核心交付清单梳理如下:

【图10-5】AI 产品 6周黄金实战落地指南
各岗位在6周项目中的核心职责分配(RACI Matrix)
- 前端(FE):负责 L6 终端展现层。重点攻克 SSE 渐进式渲染、流式打字机防抖、以及异步状态进度条展示。
- 后端(BE):负责 L5 编排层与 L2 存储层。手写状态机调度、打通企业原有业务 API 以及 pgvector 数据库。
- 算法同学(Algorithm):负责 L4 核心能力层。优化切片策略、评测并微调 Embedding 模型、组装 System Prompt,以及运行 Ragas/G-Eval 离线打分流水线。
- 安全与运维(Sec-Ops):负责 L3 流量网关。部署 DLP 数据防泄露网关、敏感词双向检测拦截器以及只读审计 COS 归档。
6周黄金实战落地任务清单与甘特里程碑:
Week 1-2:问题澄清与技术尖刺验证(Feasibility Spike)
- 前端交付:完成各业务场景的流式打字机界面及异步进度卡片原型。
- 后端交付:打通与企业内部业务系统(CRM/数据库)的只读连接。
- 算法交付:收集 20 个高难度长 PDF/表格文档,验证 Table Transformer 解析效果;人工编写第一版包含 150个 问答对的黄金离线测试集。
- 安全运维交付:完成外网 API 连通性测试与 RPM/TPM 限额压力测试。
- 阶段里程碑:黄金测试集 1.0 版本签署锁定;技术可行性(Spike)100%通过。
Week 3-4:骨架搭建与 MVP 静默灰度(Canary Deployment)
- 前端交付:对接流式 SSE 接口,实现平滑、防抖的打字机输出体验。
- 后端交付:完成基于状态机的 Agent 多步任务调度引擎搭建。
- 算法交付:上线标准 RAG(父子文档级联结构),将系统在 150 个黄金测试集上运行评测,输出版本 1.0 的初始 Ragas 雷达图得分,作为后续优化的科学基准线。
- 安全运维交付:在测试环境跑通 DLP 匿名化和敏感词双向检测。
- 阶段里程碑:MVP 1.0 版本上线,向 5% 真实用户进行“静默灰度”(不展示给用户,只在后台并行跑,对比 AI 建议与人类真实的决策差异,收集真实世界的输入)。
Week 5-6:工程硬化、成本削减与安全固化(Engineering Hardening & Roll-out)
- 前端交付:上线带有 Human-in-the-loop 人工物理审核卡片界面(在企业微信或审批工作台中完美接入)。
- 后端交付:打通与企业统一 IAM(身份权限体系)的物理隔离,支持动态权限 Metadata Filtering 检索。
- 算法交付:部署阈值 0.96 的语义缓存系统(Semantic Cache),上线意图分类与小模型级联路由。
- 安全运维交付:在 LLM Gateway 中固化双令牌桶 TPM 限流、自动 Fallback 回退自愈路由、DLP 脱敏以及只读审计归档。
- AI上线前哨检查清单(Production Readiness Checklist):
在点击按钮切换 100% 流量前,架构师必须组织团队进行以下四项“生死大考”:- 高并发压力测试(Stress Test):使用 Locust 模拟 10 倍 TPM/RPM 峰值冲击,验证 Gateway 双令牌桶限流与备用 Fallback 通道的切换耗时(目标:主备切换无抖动,熔断状态机响应正常)。
- 提示词回归回归(Prompt Regression Testing):在新版 Prompt 上运行 150 个离线黄金测试集,确保综合得分(Faithfulness、Relevance)不低于 0.85,且没有任何一类旧有 BUG 重现。
- 合规与数据漏洞审计(Security Audit):模拟输入真实的高管手机、员工银行卡、核心业务机密代码,抓取网络抓包,100% 确认 DLP 匿名化网关对这些敏感字段进行了物理 Mask 过滤。
- SLA 服务等级兜底(SLA Guarantee):流式传输状态下,P95 的 TTFT(首字延迟)必须稳定在 900ms 以下,TPOT 控制在 30ms/token 以内,提供流畅的用户阅读心理反馈。
- 阶段里程碑:系统在 5% 灰度用户中正式上线,监测两周内 Z检验 的 P值 稳定性,各项核心业务指标(如解决率、投诉率、算力Token开销)均符合预期后,全量向全集团发布上线!
本章小结
这一章,我们站在一个高阶总设计师的视角,彻底完成了从局部技能到系统方法论的升维之旅。面对白纸,你已经不再畏惧,因为你手里掌握了一套可以应对任何复杂 AI 系统落地的工程决策框架。
本章核心要点:
- AI 产品要求架构师思维升维:必须接受大模型输出的概率性本质,将系统的核心精力从“期冀大模型绝不犯错”转移到“在系统外围搭建严密的防御红线、容错调度与优雅降级”上。
- 四步法实现无缝转化:通过用户问题拆解、AI 能力转化、技术路径选型、分层架构设计,将模糊的混沌业务需求转化为科学、落地、可审计的技术盒子。
- 10大架构决策是架构师的基石:在方案评审前,必须对模型选型、私有化、时效、同步异步、多Agent、安全红线等10个决策点做出清晰、具有商业和工程合理性的 Trade-off 权衡。
- 三层效果评估捍卫系统智商:建立离线黄金数据集(Ragas打分)、在线 A/B 灰度(P值显著性计算)、线上负反馈快照蒸馏的三层闭环度量模型,让每一次 Prompt 和模型的版本迭代落到雷达图的数字上。
- 6周黄金落地节奏拒绝技术拖延:遵循前两周 Feasibility Spike、中间两周 MVP 灰度、最后两周工程硬化与成本控制的敏捷战役,以最快速度在不确定性中交出确定性的商业结果。
下章预告
到这一章结束,我们已经完成了全书最具深度、最硬核的“认知与核心架构部分”(第一部分:第1-5章认知,第二部分:第6-8章散装技能,第三部分:第9-10章工程化与顶层设计)。
你现在已经掌握了一套完美的、顶级的 AI 产品架构师操作手册。
但是,方法论只有在真实的行业熔炉中进行洗礼,才能爆发出最耀眼的商业价值。
在不同的行业里,这些架构模式该怎么变形?
在金融行业,面对敏感的客户资产和繁多的研报,我们该怎么落地?在教育领域,面对多样的学情和作文批改,我们该怎么落地?在电商零售、医疗诊断、代码协作、企业日常办公等六大核心行业,大模型的落地地图到底长什么样?各行各业有哪些被反复验证的架构套路,又有哪些一踩即炸的行业级深坑?
下一章,我们推开全书场景最丰富、商业张力最大的一扇大门:
第11章 · 行业实践地图——大模型在各领域怎么落地。
我们将为你一一把脉金融、电商、教育等六大核心垂直领域,带你将这套架构方法论深深地插进产业落地的泥土中。
延伸阅读
- 《Software Engineering for Machine Learning: A Systematic Robustness Evaluation》(https://arxiv.org/abs/2010.02210)—— 微软及学界关于机器学习和 AI 系统鲁棒性设计的经典论文,系统性探讨了如何用工程化外围手段对抗底层算法不确定性的核心架构方法论。
- Ragas Evaluation Best Practices(https://docs.ragas.io/en/stable/concepts/metrics/index.html)—— 全面介绍了我们在 10.4 节重点讲授的 Ragas 离线打分框架中,各项核心语义语义指标的严密数学模型和裁判 Prompt 设计。
- 《Designing Data-Intensive Applications》 (DDIA) —— 虽是传统分布式系统的神书,但其关于系统可观测性、事务一致性边界、以及数据解耦的设计思想,在构建 AI Data Flywheel(数据飞轮)时依然是不可或缺的灵魂基石。
- Canary Deployments and A/B Testing in LLM-Ops(https://www.comet.com/site/blog/)—— 探讨在 AIGC 落地全生命周期中,如何通过流量中间件进行科学的 A/B 灰度测试、新旧模型性能回归以及用户体验指标(UX Metrics)归因。