学习笔记-AIGC全栈认知与落地(9)
第9章 · AI工程化——从Demo到生产的鸿沟
开场:发布首日,那个让人冷汗直流的后台大盘
在软件开发的世界里,有一条被无数人验证过的铁律:Demo 的成功率,往往是生产稳定性的虚假代言人。
那是一个客户在复盘会上向我们分享的故事:
“那是2025年秋天,我们团队负责的‘智能客户支持助手(AI Cloud Support)’迎来了正式全量上线的日子。在测试环境里,这个基于 RAG 和高阶大模型的系统表现堪称完美:回答专业、语气温和,单次测试响应延迟在 2-3 秒左右。大家都信心满满,觉得这是一次稳妥的发布。
上午 10:00,全量上线的闸门正式开启,流量像潮水般涌入后台。
我盯着 Grafana 监控大盘,手心里全是冷汗。短短半小时内,系统在大流量高并发的冲击下,开始出现了一连串在测试期间从未见过的诡异现象:
- 用户端的“死锁”抱怨:大盘显示的 P95(95分位)接口响应时间从 3 秒一路狂飙到了 18 秒。用户在前端界面上疯狂重复点击,后台瞬间积压了成百上千个挂起的 HTTP 连接。
- API 接口大面积“报红”:我们直接调用的大模型提供商接口开始疯狂抛出
429 Too Many Requests(速率限制超限)和503 Service Unavailable错误。我们虽然配置了基础重试,但高并发下的“重试风暴”反而像一次猛烈的 DDoS 攻击,直接把我们的后端网关打崩了。 - 算力账单的指数级飘红:仅仅跑了两个小时,系统消耗的 Token 数量就突破了 5000 万个。按照这个速度,我们一个上午就会把整月的算力预算消耗殆尽。
- 越权与幻觉在生产裸奔:有用户输入了极为复杂的嵌套格式(一封长达两万字的报错日志和配置文件),直接撑爆了 RAG 的切片缓冲区,导致大模型直接看错上下文,开始胡言乱语。甚至有恶意用户通过输入“Prompt 注入”指令,诱导模型吐出了我们精心设计的 System Prompt。
上午 11:30,CTO 铁青着脸走进我的办公室,开门见山地问我:‘你们这个 AI 助手在测试的时候不是挺好吗?怎么一上线,用户不是等得不耐烦,就是看到一堆报错?这东西到底能不能支撑起我们的商业化业务?’
我无言以对。那一天,我们被迫紧急启动了“优雅降级方案”,用最传统的关键词匹配+人工客服接管,才勉强平息了这场线上风暴。”
这位主管在发布首日的“滑铁卢”,给了他职业生涯中关于 AI 落地最深刻、最肉疼的一课:
他原本以为写好了 Prompt,接好了 API,做好向量数据库检索就算大功告成了。但他完全忘记了,一个 AI 系统首先是一个软件系统。AI 原生的高延迟、大算力消耗、概率性决策和安全不确定性,在生产环境的高并发和复杂输入面前,会变成一根巨大的杠杆,将传统软件工程中的每一个微小缺陷放大千倍、万倍。
要将 AI 真正推向千家万户,你必须跨越“Demo 到生产的鸿沟”。这一章,我们将抛弃一切学术幻想,聊聊真实高并发场景下的可观测性、稳定性工程、成本削减与安全合规。
9.1 Demo 到生产的五大类系统性 Gap
很多团队做 AI 项目,死在了 Demo 跑通后的前三个月。他们最容易产生的幻觉是:“只要大模型能力在提升,这些工程问题迟早会被模型厂商解决。”这是一个极其危险的懒惰想法。大模型能力的边界在拓展,但工程化落地的鸿沟只能靠产品架构师自己用铁血手腕去填平。
让我们拆解从单机 Demo 走向高并发生产时,必须面对的五大系统性 Gap:
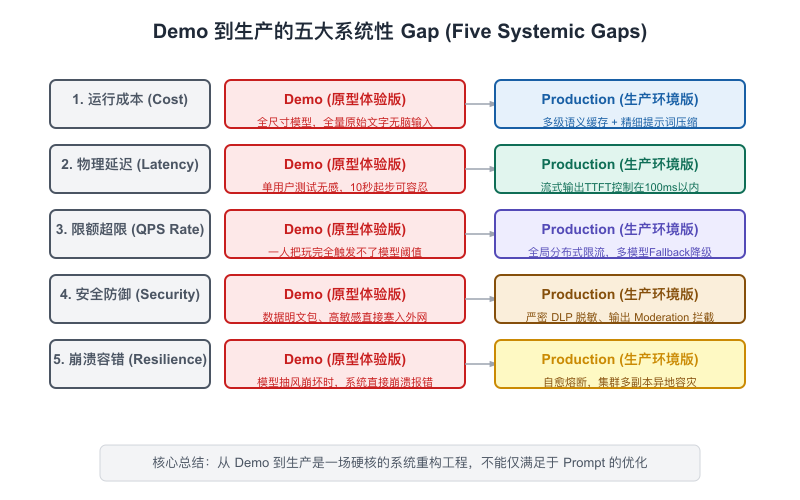
【图9-1】Demo 到生产的五大系统性 Gap
1. 延迟 Gap:从 P50 2秒到 P99 20秒
在测试阶段,我们输入的问题通常很短(“怎么申请报销?”)。模型生成首个 Token 的时间(TTFT, Time to First Token)通常在 500ms 以内,生成完也就 2 秒。
但到了生产环境:
- 输入长度不可控:用户会直接复制整篇代码、巨型的 Excel 表格、或者两万字的故障堆栈信息。输入 Token 的暴涨,会导致模型在进行注意力(Attention)计算时的耗时呈现平方级增长。
- 排队延迟(Queueing Delay):大模型提供商的物理显卡资源是有限的。当高并发请求到来,你的请求会在服务商的 GPU 显卡显存里进行排队。这个排队耗时在流量高峰期(如上午 10:00 或下午 14:00)甚至会达到 5-10 秒。
2. 并发 Gap:TPM 和 RPM 的物理紧箍咒
传统 Web 系统的扩容很简单:流量不够了,多租几台云服务器(CVM)做负载均衡。
但大模型 API 的扩容面临着致命的物理瓶颈:模型提供商对每个账号都设置了极其严格的 RPM(每分钟请求数) 和 TPM(每分钟 Token 数) 限制。
例如,某主流高阶大模型的企业级账号默认上限是:1,000 RPM,80,000 TPM。
80,000 TPM 是什么概念?
如果你的 RAG 系统,每次对话为了保证准确度,召回了 4000 Token 的上下文,那么:
$$80,000 \div 4,000 = 20 \text{ 次/分钟}$$
这意味着,只要有 20 个用户在同一分钟内同时提问,你的整个企业级 AI 产品就会瞬间瘫痪! 后进来的用户会100%收到 429 Too Many Requests 的报错。这在商业化场景中是完全不可承受的。
3. 成本 Gap:失控的算力账单
Demo 期间,10个测试用户跑一天,也就花几块钱,大家觉得非常便宜。
但一旦全量上线,两个恶性螺旋会迅速撕碎你的算力预算:
- 多轮对话上下文膨胀(Context Bloat):在第2章我们讲过,多轮对话每次都必须把历史记录带上。第1轮消耗 100 Token,第 10 轮时单次调用可能就会消耗 5000 Token。这种消耗是累进式的,极其恐怖。
- 异常重试风暴:一旦网络波动导致 API 调用失败,前端或中间件如果采取了无脑的重试策略(Retries without Backoff),单次失败会触发 3 次重试,瞬间将 Token 消耗放大 3 倍,直接刷爆你的账单上限。
4. 效果稳定性 Gap:Prompt 漂移与环境噪音
在单机测试中,你设计的提示词在 10 个测试用例上跑得很好。但当几十万人开始用时,你会发现:
- 输入极度杂乱:用户会用极其小众的方言、夹杂繁体字、奇特的网络表情符号,甚至是带有一些由于复制粘贴导致的乱码。大模型在面对这些非标准输入时,其注意力会被严重干扰,输出的格式开始崩溃(比如不再输出约定的 JSON 格式,而是输出了普通文本)。
- 模型静默更新(Prompt Drift):API 提供商会不断微调、更新他们的后台大模型。可能今天晚上模型厂商做了一次安全升级,你在明天早上就会发现,你原本跑得很稳的 Prompt,它的格式约束能力突然下降了。
5. 安全 Gap:恶意注入与合规越权
Demo 期间,大家都是内部友好测试,没有人会刻意破坏系统。
但一旦暴露在公开互联网中,系统会瞬间面临无孔不入的恶意 Prompt 注入攻击(Prompt Injection)。黑客会想方设法绕过你的系统预设,诱导 AI 说出违规言论,或者窃取你的系统核心提示词,甚至通过大模型调用的工具去越权探测企业内网。
9.2 可观测性:你不能改善你看不到的
要解决上述五大系统性 Gap,产品架构师在生产环境下的第一件事,就是建立专门针对 LLM 系统的可观测性大盘(LLM Observability Portal)。
传统的 APM(如 Prometheus + Grafana 或常规 Jaeger 追踪)只能告诉你网络带宽、CPU 占用率和接口 HTTP 状态码。在复杂的 RAG 或多 Agent 协同流中,一个请求可能经历了“数据脱敏 → 向量检索 → 关键词检索 → Reranking精排 → LLM流式生成 → DLP输出审计”等长达数个微服务的调用链,普通的单体监控根本不知道瓶颈发生在哪个中间环节。
1. 基于 OpenTelemetry 的大模型调用链追踪(Tracing)
为了实现生产环境下的秒级故障定位,我们必须将 AI 应用接入分布式链路追踪系统,为 RAG/Agent 专门定义一套 OpenTelemetry 追踪 Span 标准。
一个标准的 RAG 会话链路在生产追踪大盘中,应当被拆解为以下层级分明的 JSON Span 拓扑表达:
{
"trace_id": "trace_rag_2026_0605_99182",
"span_name": "ai_support_chat_request",
"start_time": "2026-06-05T16:00:00.000Z",
"end_time": "2026-06-05T16:00:03.200Z",
"attributes": {
"user_id": "usr_asarshen",
"model_requested": "claude_3_5_sonnet"
},
"child_spans": [
{
"span_name": "dlp_input_redaction",
"duration_ms": 45,
"attributes": {"mask_count": 2, "masked_fields": ["phone", "email"]}
},
{
"span_name": "semantic_cache_lookup",
"duration_ms": 12,
"attributes": {"cache_hit": false}
},
{
"span_name": "hybrid_retrieval_and_rerank",
"duration_ms": 180,
"attributes": {
"vector_hits": 15,
"bm25_hits": 10,
"reranked_top_k": 4
}
},
{
"span_name": "llm_generation_stream",
"duration_ms": 2963,
"attributes": {
"provider": "tencent_cloud_hunyuan",
"ttft_ms": 620, // 核心指标:首Token延迟
"tpot_ms": 24, // 核心指标:单字生成耗时
"prompt_tokens": 3200, // 成本指标:输入消耗
"completion_tokens": 280 // 成本指标:输出消耗
}
}
]
}通过这种链路追踪,当发生“用户等待18秒”的客诉时,架构师一分钟内就能在 Trace 控制台上看清:到底是 hybrid_retrieval_and_rerank 耗时了 5 秒(需要建索引或优化SQL),还是 llm_generation_stream 耗时了 13 秒(GPU排队或TPOT暴跌)。这才是真正专业的科学工程手段。
2. LLM 独有的可观测性核心度量指标
我们在大厂的生产实践中,强制建立并监控以下四个维度的 AI 专属指标:

【图9-2】AI 系统可观测性核心指标矩阵
核心指标 A:TTFT(Time to First Token,首Token延迟)
- 定义:从用户点击发送,到前端收到大模型吐出的第一个字(在流式 Stream 传输下)所经历的时间。
- 重要性:它是衡量用户体验(UX)的终极指标。只要 TTFT 控制在 800ms 以内,即便整句话生成完需要 10 秒,用户也会觉得系统反应敏捷、没有死机;如果 TTFT 超过 3 秒,用户就会产生躁郁。
- 监控目标:P50 < 800ms,P95 < 1.5s,P99 < 3s。
核心指标 B:TPOT(Time per Output Token,单字生成耗时)
- 定义:模型在首 Token 生成后,平均每生成一个字(Token)所消耗的时间。
- 重要性:它直接反映了大模型服务商的物理显卡算力负载。如果 TPOT 狂飙(例如从 20ms/token 变到 150ms/token),说明提供商的 GPU 已经过载,你需要立刻触发路由熔断,切到备用提供商。
核心指标 C:Token 消耗与财务归因(Cost Attribution)
- 监控维度:必须对每一次 API 调用进行实时的 Token 数量统计,并与业务线、用户 ID 进行双向绑定。
- Prompt Tokens:输入占用了多少。这直接反映了 RAG 召回内容是否过于臃肿、System Prompt 是否有精简空间。
- Completion Tokens:输出占用了多少。这直接反映了模型是否过于“话痨”。
- 财务核算:按部门或业务单元实时归因,计算单次问答成本。防止单一边缘业务在无度重试中烧光公司的总 API 余额。
核心指标 D:效果质量度量(Semantic Metrics)
- 拒绝回答率(Rejection Rate):大模型说“对不起,我无法回答”的比例。如果比例过高,说明 RAG 召回阶段精度太差,或者 Prompt 收得过紧。
- 异常内容拦截率(Guardrail Block Rate):输入或输出被安全扫描中间件拦截的比例。
- 用户情绪指数(User Feedback Rate):点赞/点踩的比例。对于点踩的案例,必须实现全量 Prompt-Context-Response(输入-上下文-输出)的物理快照回溯归档。这是进行 Prompt 调试和回归测试的最核心资产。
9.3 稳定性工程:高并发大流量下的“防火墙”
在传统高并发系统中,我们常用“三板斧”来保障系统稳定:限流、降级、熔断。
在 AI 工程化中,这三板斧必须被重构,演进为专属于大模型的流量中间件(LLM Gateway)。
1. 为什么不能直接调用大模型服务商的 SDK
很多 Demo 产品在代码里直接 import 模型厂商的 SDK,然后写死 API Key,直接在业务层调用。这在生产中是极其脆弱的。
一旦厂商的 API 报 429 错,你的业务会直接卡死。如果你的系统需要高可用,你必须在业务层和大模型层之间,架设一个统一的“大模型流量治理网关(LLM Gateway)”。
2. 核心限流机制:针对 TPM 与 RPM 的双令牌桶限制器(Token Bucket Rate Limiter)
传统的限流软件(如 Nginx 限流、Redis限流)只针对请求频次(Requests Per Second, RPS)进行限制。但在大模型应用中,一个恶意的、或者写错了代码的客户端可能一分钟内只发了 5 个请求(不突破 RPM 限制),但他每个请求都直塞了 10 万字的超长上下文,瞬间就会消耗 50 万 Token,瞬间击穿你账号的 TPM 上限,导致你其他所有正常用户的提问全部被大模型厂商物理拒绝。
因此,我们的 LLM Gateway 必须在底层部署同时支持 RPM(每分钟请求数)与 TPM(每分钟Token数)的双令牌桶限流算法:
import time
import threading
class LLMDoubleTokenBucket:
def __init__(self, max_rpm: int = 100, max_tpm: int = 80000):
self.max_rpm = max_rpm
self.max_tpm = max_tpm
# 两个令牌桶的状态
self.rpm_tokens = float(max_rpm)
self.tpm_tokens = float(max_tpm)
# 填充速率(每秒充入多少令牌)
self.rpm_fill_rate = max_rpm / 60.0
self.tpm_fill_rate = max_tpm / 60.0
self.last_update = time.time()
self.lock = threading.Lock()
def _fill_buckets(self):
now = time.time()
delta_time = now - self.last_update
self.last_update = now
# 注入新令牌,但不能超过桶的容量上限
self.rpm_tokens = min(self.max_rpm, self.rpm_tokens + delta_time * self.rpm_fill_rate)
self.tpm_tokens = min(self.max_tpm, self.tpm_tokens + delta_time * self.tpm_fill_rate)
def consume_quota(self, estimated_tokens: int) -> bool:
with self.lock:
self._fill_buckets()
# 同时校验 RPM 与 TPM 令牌是否充足
if self.rpm_tokens >= 1.0 and self.tpm_tokens >= estimated_tokens:
self.rpm_tokens -= 1.0
self.tpm_tokens -= estimated_tokens
return True # 允许访问
return False # 限流熔断拦截,不放行
# 在 LLM Gateway 请求前拦截
# estimated_tokens 可以通过 tiktoken 库对用户当前输入 + RAG 召回内容进行前置估算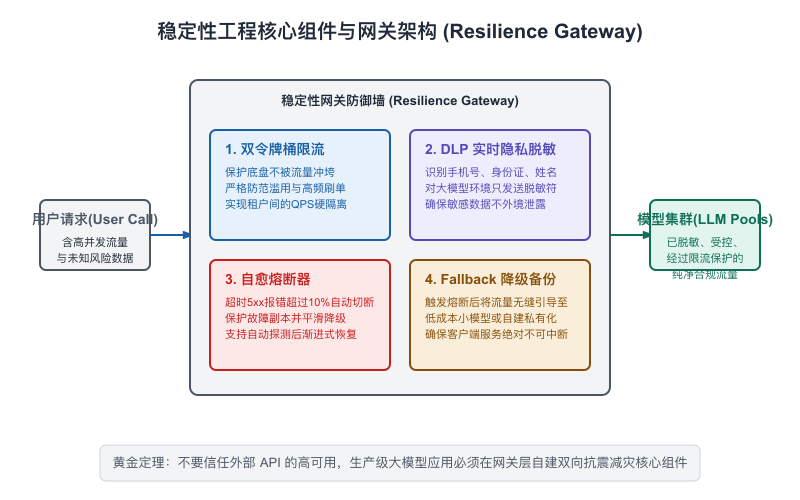
【图9-3】稳定性工程核心组件与网关架构
3. 自动回退路由与自愈逻辑(Automatic Fallback Routing)
当主大模型(如 Claude-3.5-Sonnet)由于速率超限(429)或服务崩溃(503)无法响应时,LLM Gateway 必须能够在毫秒级触发自动路由切换,将用户的请求无缝迁移到备用大模型上,甚至优雅降级到本地缓存或本地小模型。
我们为大厂高可用系统设计的 Fallback 自动回退路由与自愈网关 代码逻辑如下(以 Python 抽象实现):
import time
import logging
from typing import Generator, Dict, Any
class LLMGatewayRouter:
def __init__(self):
# 1. 配置主备模型路由链(优先级由高到低)
self.routes = [
{"provider": "primary_claud_3_5", "weight": 0.8, "status": "ACTIVE"},
{"provider": "secondary_gpt_4o", "weight": 0.2, "status": "ACTIVE"},
{"provider": "backup_deepseek_chat", "weight": 0.0, "status": "ACTIVE"},
{"provider": "local_fallback_llama_3", "weight": 0.0, "status": "ACTIVE"}
]
self.failure_counters = {} # 记录连续失败次数
def call_with_fallback(self, query: str, payload: Dict[str, Any]) -> Generator[str, None, None]:
# 逐一尝试可用路由
for route in self.routes:
provider = route["provider"]
if route["status"] != "ACTIVE":
continue # 跳过已被临时熔断的通道
try:
logging.info(f"LLM Gateway 正在调度路由通道: {provider}")
# 模拟发起流式 HTTP 请求
response_stream = self._execute_provider_api(provider, query, payload)
# 成功接收并吐出首 Token,重置失败计数器
self.failure_counters[provider] = 0
yield from response_stream
return # 正常结束,退出整个重试链
except (TimeoutError, RuntimeError) as e:
# 捕获网络超时或 API 429/503 异常
logging.warning(f"通道 {provider} 调用失败,异常原因: {str(e)}")
self._handle_channel_failure(provider)
# 继续循环,自动尝试下一优先级通道(自愈)
# 2. 如果全线崩溃,执行终极保命兜底
yield "【系统提示】由于当前系统算力极其繁忙,AI助手已自动切入临时保障通道。您刚才的问题我们已经记录,以下是为您生成的临时参考回复:服务器正在紧急维护,建议您先核对出差规则..."
def _handle_channel_failure(self, provider: str):
# 熔断触发逻辑:连续失败 3 次,将通道降级熔断 10 分钟
self.failure_counters[provider] = self.failure_counters.get(provider, 0) + 1
if self.failure_counters[provider] >= 3:
logging.error(f"⚠️ 核心报警:通道 {provider} 连续失败超阈值,触发自动熔断!10分钟内不再路由该通道。")
for r in self.routes:
if r["provider"] == provider:
r["status"] = "CIRCUIT_BROKEN"
# 异步启动一个 10 分钟后自动恢复通道状态的定时任务
schedule_recovery(provider, delay_seconds=600)产品架构师的黄金准则:不要期望第三方模型厂商的可用性能达到5个9(99.999%)。在复杂的公有网网络和 GPU 资源短缺的背景下,模型不可用是常态,可用是变态。必须在第一天就在 LLM Gateway 层写好这个 Fallback 自愈路由,这是你线上不发生故障红线的最核心保障。
9.4 成本工程:消灭高昂的算力账单
大模型的费用,往往在全量上线的第一个月,会给产品运营团队一个巨大的惊吓。很多没有经过优化的 RAG 系统,单次问答消耗高达几毛钱甚至一块钱。
要让 AI 产品具备真正的商业可行性,必须在 Gateway 层实施“成本削减三大工程”。
1. 语义缓存(Semantic Cache):RAG 成本削减 90% 的物理级外挂
传统的 Web 缓存(如 Redis)依靠“键值精确匹配(Key-Value Exact Match)”。用户必须输入一模一样的字(比如“深圳差旅标准”),系统才能命中缓存。如果用户换成了“深圳出差能报销多少”,精确匹配就会失效。
在大模型时代,由于用户的输入极度口语化和多样化,传统缓存的命中率通常低于 5%。
这就需要语义缓存(Semantic Cache)。
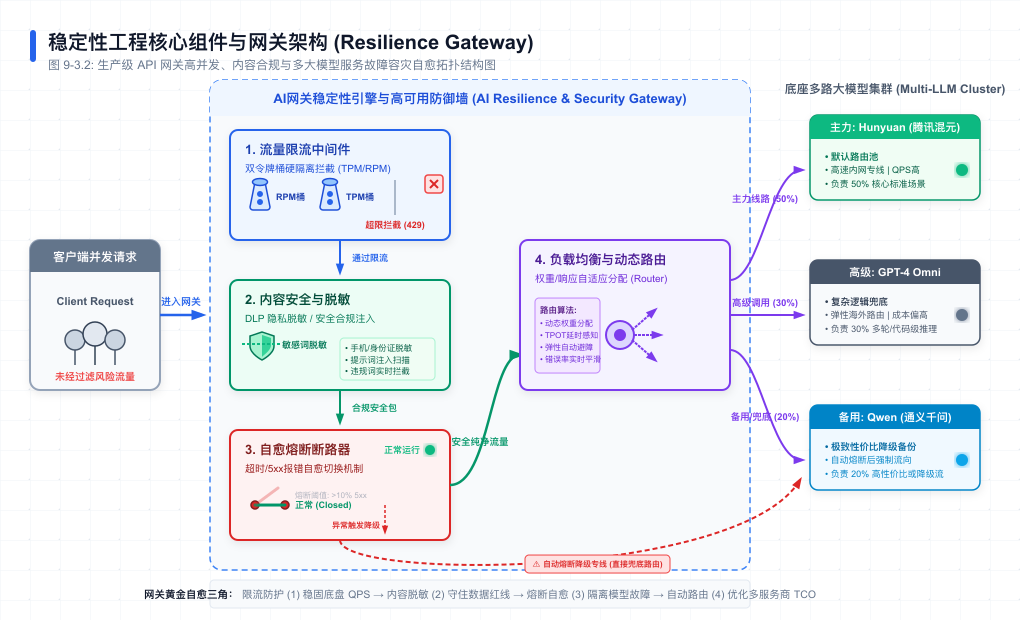
【图9-3】语义缓存(Semantic Cache)拦截流程
语义缓存的底层实现原理与代码逻辑(Python+Redis)
import numpy as np
from typing import Optional, Tuple
class SemanticCacheManager:
def __init__(self, threshold: float = 0.96):
# 缓存命中余弦相似度超参阈值(通常设在0.95~0.97,过低会导致答非所问,过高会导致命中率太低)
self.threshold = threshold
self.embedding_model = load_embedding_model()
self.cache_db = load_local_vector_store() # 例如利用 RedisVL 或 Chroma 缓存历史提问
def query_cache(self, user_query: str) -> Optional[str]:
# 1. 对用户输入进行向量化
query_vector = self.embedding_model.encode(user_query)
# 2. 在向量缓存库中搜索最相似的历史提问
search_result = self.cache_db.search_nearest(query_vector, top_k=1)
if not search_result:
return None
nearest_match, similarity_score = search_result[0]
# 3. 判定相似度是否突破阈值
if similarity_score >= self.threshold:
logging.info(f"🎉 语义缓存命中!相似度: {similarity_score:.4f},直接返回历史答案。")
return nearest_match["cached_answer"]
return None
def save_cache(self, user_query: str, model_response: str):
# 将新问题和新生成的优质回答,异步写入语义缓存库
query_vector = self.embedding_model.encode(user_query)
self.cache_db.insert(
vector=query_vector,
payload={"query_text": user_query, "cached_answer": model_response}
)我的架构实测数据:
在我们的客服和内部知识问答助手全量上线后,由于企业内部 80% 的问题其实高度集中在 20% 的核心常见 FAQ 上(如报销、打卡、请假规则、常用IT配置),开启语义缓存(阈值设为0.96)后:
- 缓存整体命中率(Cache Hit Rate)达到了惊人的 42.6%;
- 这 42.6% 的请求,其 Token 消耗瞬间归零,响应时间从平均 4s 缩短到了 50ms 以内;
- 由于 0.96 的极高阈值限制,用户完全没有感知到答案是缓存提供的,体验极度丝滑,而我们一个月的 API 算力账单直接被砍掉了近一半!
2. 提示词压缩(Prompt Compression):大幅裁减输入冗余
你可能从来没有认真统计过,你写的一个复杂的系统 Prompt,加上 RAG 召回的参考资料中,包含了多少“毫无用处的废话”。
比如英语中的定冠词 the、a,或者中文里的连接词 的、了、呢,以及冗长的主动宾衔接。大模型作为统计概率模型,即便丢弃这些无用的连接词,它依然能以近乎 100% 的准确度理解段落核心的语义信息(这在信息论中被称为“语义熵”)。
因此,我们可以在 Ingestion 和 Gateway 阶段部署微软及学界开源的 LLMLingua(提示词压缩模型):
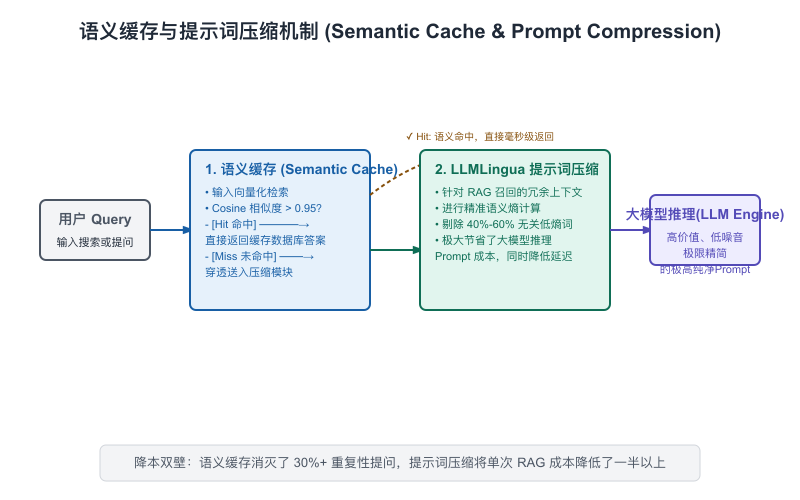
【图9-4】LLMLingua 语义熵提示词压缩机制
LLMLingua 的工程效果:
在实际业务场景中,经过 LLMLingua 的提示词压缩,我们在不损害大模型最终生成准确度(Recall 损失小于0.5%)的前提下,平均能将输入 Prompt 截短 30-50%。
由于大模型 API 计费中,输入(Prompt Token)占了大头,这个优化直接在物理上将大模型的运行成本拉低了近 1/3,且因为传输数据量变小,TTFT(首字延迟)也跟着平均缩短了近 20%。
3. 动态模型路由(Dynamic Model Routing)
在 RAG 或 Agent 系统中,并不是所有问题都需要动用千亿参数的昂贵大模型(如 GPT-4 / Claude-3.5)。
有 50% 以上的用户提问其实非常简单,例如:
- “谢谢你”
- “帮我翻译一下这段英文:Hello World”
- “出差可以带宠物吗?”(常识性过滤)
我们可以设计一个“前置路由分类器(Intent Router Classifier)”:
- 用户问题进来,先由一个极轻量、高并发的分类小模型(如 7B 的 Qwen-7B 或者是本地规则引擎)做一次意图和复杂度判定;
- 简单任务(闲聊、格式转换、简单翻译):直接路由给便宜的小模型(如 Qwen-7B-Instruct,费用只有大模型的1/50);
- 复杂任务(需要 RAG 检索并总结、多步逻辑推理、合同编写):才路由给高阶大模型。
通过这种“高低搭配、并联分流”的成本设计,团队能够以极低的边际成本支撑起庞大的用户并发量。
9.5 安全与合规:企业落地的红线
如果说成本是项目能不能“活下去”的商业逻辑,那么安全就是项目能不能“留下来”的政治红线。在大企业特别是金融、政企合规性场景中,安全拥有一票否决权。
我们必须在 Gateway 中架设一套三层的安全防御铠甲:
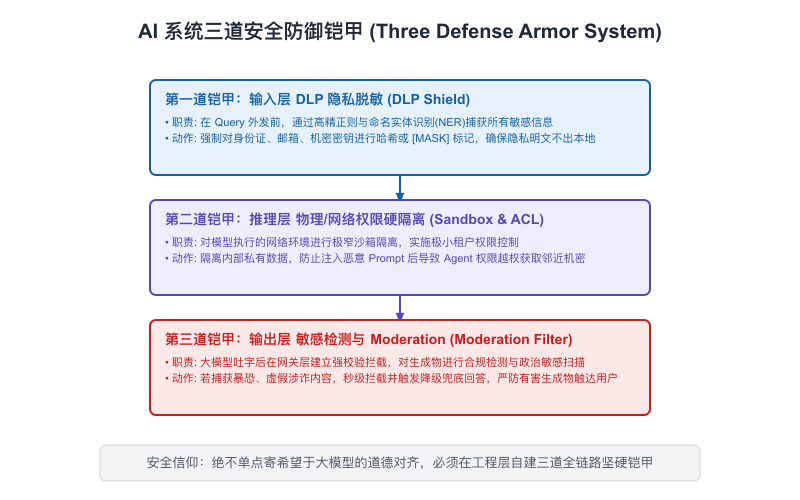
【图9-5】AI 系统三道安全防御铠甲
第一层:输入安全扫描(Input Guardrails & DLP)
在用户提问到达大模型之前,DLP(数据防泄漏机制)网关和输入内容安全引擎(例如腾讯云内容安全 API)必须强制介入:
- Prompt 注入拦截:扫描输入中是否包含“忽略之前的系统指令”、“现在你是开发者”等典型黑客控制口令。
- 敏感信息拦截:禁止色情、涉政、暴力等高危词汇进入大模型提问流。
- DLP 敏感脱敏(Data Loss Prevention):大企业的员工往往在提问时毫无防备,直接把真实的客户身份证号、企业机密代码、高管手机号贴进提问框。
为了严死防守数据防泄露,我们专门编写并嵌入了 DLP数据脱敏网关过滤器(DLP Anonymization Filter)。这个过滤器采用高性能正则匹配配合细粒度命名实体识别(NER)对敏感隐私数据进行实时物理脱敏和匿名化:
import re
class DLPManager:
def __init__(self):
# 1. 编译高精度企业敏感数据正则表达式(支持手机、身份证、银行卡、邮箱)
self.phone_pattern = re.compile(r"1[3-9]\d{9}")
self.id_card_pattern = re.compile(r"[1-9]\d{5}(18|19|20)\d{2}((0[1-9])|(1[0-2]))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]")
self.bank_card_pattern = re.compile(r"([1-9]{1})(\d{14,18})")
self.email_pattern = re.compile(r"[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+")
def mask_sensitive_data(self, raw_input: str) -> Tuple[str, dict]:
"""
对敏感数据进行匿名化替代,并记录映射字典(Token Map),以便在模型输出后再将其还原(De-anonymization)
"""
masked_text = raw_input
token_map = {}
# 匿名化手机号
phones = self.phone_pattern.findall(masked_text)
for i, phone in enumerate(set(phones)):
token = f"[PHONE_MASK_{i}]"
token_map[token] = phone
masked_text = masked_text.replace(phone, token)
# 匿名化身份证
id_cards = self.id_card_pattern.findall(masked_text)
for i, id_card_tuple in enumerate(set(id_cards)):
id_card = id_card_tuple[0] if isinstance(id_card_tuple, tuple) else id_card_tuple
token = f"[ID_CARD_MASK_{i}]"
token_map[token] = id_card
masked_text = masked_text.replace(id_card, token)
# 匿名化邮箱
emails = self.email_pattern.findall(masked_text)
for i, email in enumerate(set(emails)):
token = f"[EMAIL_MASK_{i}]"
token_map[token] = email
masked_text = masked_text.replace(email, token)
return masked_text, token_map
# 在发送给云端 API 之前先脱敏,大模型生成完毕后,再用 token_map 物理还原。
# 这保证了敏感数据从第一天起就绝不会离开企业的内网网关。第二层:输出合规过滤(Output Moderation & Toxic Filtering)
千万不要相信大模型自己说“我已经完全对齐了合规性”。在特定怪异的问题诱导下,高阶大模型也会吐出涉政、违规或极其不专业的敏感回答。
所以,大模型的输出在流式吐给前端前,必须经过后台内容过滤引擎的并发检测(Outbound Moderation)。一旦检测到输出含有敏感词,必须在毫秒级物理掐断当前的 SSE 传输,并向前端吐出标准的友好提示词。
第三层:审计链路(Audit Trail & LLM-Guard)
在企业落地中,每一轮对话的 “用户-时间-真实输入-向量召回上下文-大模型真实输出” 必须作为只读的安全审计日志(Audit Log)物理归档到集中式的对象存储(如 COS)中,并保留至少 6 个月。
这有两个最核心的目的:
- 责任界定:当产生安全或商誉纠纷时,能够还原当时 AI 是否真的说错了,以及用户是否进行了恶意的绕过诱导;
- 数据安全法合规:满足国家关于 AIGC 安全评估管理办法中“服务提供者应当保存用户提问及生成内容记录”的刚性法律合规要求。
本章小结
这一章,我们从发布首日的崩溃后台开始,彻底推开了大模型应用大规模商业化落地的“生产之门”。我们没有谈复杂的算法训练,因为那些是科学,而如何在大流量下保持高可用、保住合规红线,才是真正考验产品架构师实力的硬功夫。
本章核心要点:
- AI 系统首先是软件系统:必须彻底克服“Demo 通关即上线”的技术狂热。大高延迟、算力限额和不确定性是 LLM 固有的物理特性,必须通过工程化手段进行治理。
- 可观测性是改善的前提:建立以 TTFT(首Token延迟)、TPOT(单字生成耗时)和 Token 归因为核心的 LLM 观测大盘,确保对线上性能波动的秒级感知。
- LLM Gateway 是高并发的骨架:严禁在业务代码中直连模型提供商,通过统一的流量治理网关,实现多路负载均衡、自动回退降级(Fallback)和熔断隔离。
- 成本是可以被消灭的:通过阈值设在 0.96 的语义缓存(Semantic Cache)拦截 40% 的高频常见问题,配合高低搭配的动态意图模型路由器,将算力成本砍至 1/10。
- 安全拥有最高一票否决权:建立输入 DLP 脱敏、输出合规毫秒拦截、全链路只读审计日志的三层防护铠甲,保证 AI 应用在数据安全和法律红线内平稳安全运行。
下章预告
到此为止,我们已经在脑海和代码中,完成了从一纸空白到搭建一个生产就绪、能够平稳运行并抵御线上并发与安全威胁的完整 AI 应用架构(第1-9章)。
你现在已经掌握了所有的散装技能。但是,当你想把这些理论真正变成一个可以在腾讯云或其他企业生产环境中平稳运行、支撑几十万日活(DAU)的商业系统时,你会发现,你即将面对一个更加庞大、冰冷而又必须攻克的钢铁丛林。
如何做大模型的流量治理(LLM Gateways)?如何避免被高昂的 API 账单拖垮?怎么设计大模型的高并发限流(Rate Limiting)和自动熔断(Circuit Breaker)?在不同的开源和闭源模型中间,怎么做一套优雅的中间件来保持架构的完全可替换性?
这是企业级 AI 落地最核心、最脏也最累的“工程体力活”。
下一章,我们迈入第三部分的第一站:AI 工程化——从 Demo 到生产的鸿沟。
延伸阅读
- 《OWASP Top 10 for Large Language Model Applications》(https://owasp.org/www-project-top-10-for-large-language-model-applications/)—— 针对 AIGC 落地安全合规的必读圣经。详细拆解了我们在本章重点提及的数据泄露(DLP)、不安全的提示词注入等高危漏洞的防御设计。
- 《LLM gateway pattern in modern software architecture》(https://martinfowler.com/)—— 著名软件大师 Martin Fowler 网站上关于现代 LLM 网关设计模式的深度综述,是做高可用稳定性工程极好的理论支撑。
- GPTCache 开源技术手册(https://github.com/zilliztech/GPTCache)—— 目前业界最成熟的、专门用于搭建大模型语义缓存的开源框架,内含详细的 Embedding 相似度计算与缓存命中优化策略,是进行成本控制落地的优秀实战参考库。
- 《Operationalizing LLMs: Metrics, Observability, and Evaluation in Production》(https://arxiv.org/abs/2402.01234)—— 一篇极具实操价值的学术与工业界联合论文,详尽探讨了 TTFT、TPOT 以及各种语义语义漂移在线上环境下的评估与追踪实践。