学习笔记-AIGC全栈认知与落地(5)
第5章 · 大模型江湖——怎么选模型
开场:那次"选错了"的代价
有一次,我们在做一个内部代码审查助手,需要选一个模型。我打开了几个评测榜单,看到GPT-4在代码评测上得分最高,就直接选了GPT-4——没有测过我们的真实代码样本,没有核算成本,也没有想过延迟要求。
上线两周后问题来了:
- 每次代码审查平均输出2000 tokens,但我们用的是GPT-4的旧版,输出速度只有25 tok/s——用户等了将近80秒才能看到完整结果
- 月均调用量3万次,算下来每月费用8万元——比预算高了三倍
- 开发同学反映,GPT-4给的建议太"通用"了,对我们特定的代码规范几乎没有帮助
后来我们换成了一个用内部代码微调过的Qwen-14B,延迟降到12秒,成本降到每月6000元,代码规范命中率反而从60%涨到82%。
这次教训让我彻底改掉了一个坏习惯:用"排行榜最强"代替"场景适合"。
排行榜解决不了你的选型问题,因为它不知道你的场景、你的预算、你的合规限制——它只知道"在一组统一的测试题上谁答得更好"。这一章,我把这个教训提炼成一套可以复用的选型方法论。
5.1 模型的"能力维度":不存在全面碾压的模型
很多人选模型的方式是看"综合排名"——就像我当初一样。
但在真实的产品场景中,你需要的不是"综合最强",而是"在你最关心的那1-2个维度上够用,同时其他约束能满足"。
把模型能力想象成一个运动员的体测项目:一个人可以在长跑上拿金牌,但短跑可能只是普通水平。综合体能分数高,不代表你选他去跑400米一定是最优解——你得看你需要什么。
一个模型的核心能力可以从7个维度来评估:
【图5-1:模型七维能力示意】
| 维度 | 含义 | 典型评测 | 什么场景关键 |
|---|---|---|---|
| 推理 | 逻辑推导、数学、复杂分析 | MATH, GSM8K | 数据分析、方案评估 |
| 创作 | 文本生成质量、创意、风格 | 人工评测 | 营销文案、报告撰写 |
| 代码 | 代码生成、理解、调试 | HumanEval, SWE-bench | 代码助手、自动化 |
| 多模态 | 图片理解、视频理解 | MMMU, MMBench | 图文识别、视觉分析 |
| 中文 | 中文理解与生成质量 | C-Eval, CMMLU | 国内产品必看 |
| 长文本 | 长上下文处理能力 | RULER, LongBench | 文档处理、会议总结 |
| 工具调用 | Function Calling准确度 | Berkeley FC Bench | Agent、工作流自动化 |
核心认知:没有"全面碾压"这件事
2024-2025年的大模型格局有一个显著特征:头部模型之间差异在缩小,但各有侧重。
- GPT-4o的推理深度目前最强,但中文输出质量不一定比Claude好
- Claude指令遵从和安全性最佳,数学代码稍弱于GPT
- Gemini上下文窗口最长(1M-2M tokens),但中文场景表现一般
- DeepSeek-V3在中文和代码上接近GPT-4级,但成本只有1/10
产品架构师的判断:做选型决策前,先列出你的场景对哪个维度权重最高——不是所有7个维度都同等重要。一个客服意图识别系统,"中文理解"权重70%,"推理"权重10%,"多模态"权重0%。权重想清楚了,选型方向就自然清晰了。
5.2 开源 vs 闭源:不只是技术问题
这是选型时最先要做的战略性判断——而且它不主要是技术问题,是商业和治理问题。
我见过太多团队把这个决策处理得太随意:要么默认用OpenAI("大家都在用"),要么一听到"数据安全"就要私有化(没算清楚成本)。
技术差距的真实状态
先说清楚技术现状:2024年以来,开源和闭源的技术差距已经大幅缩小。
Llama 3 405B / DeepSeek-V3 / Qwen-2.5-72B 在很多任务上接近或达到了GPT-4级别。在特定垂直任务上(经过微调后),开源70B模型甚至可以超越通用闭源模型——就像我在代码审查助手里亲历的那样。
但差距仍然存在:最前沿的推理能力(o1/o3/R1级别)、最新的多模态能力,开源暂时追不上。差距大约是3-6个月——领先方会一直保持这个缓冲。
真正的区别:商业模式、控制力、风险
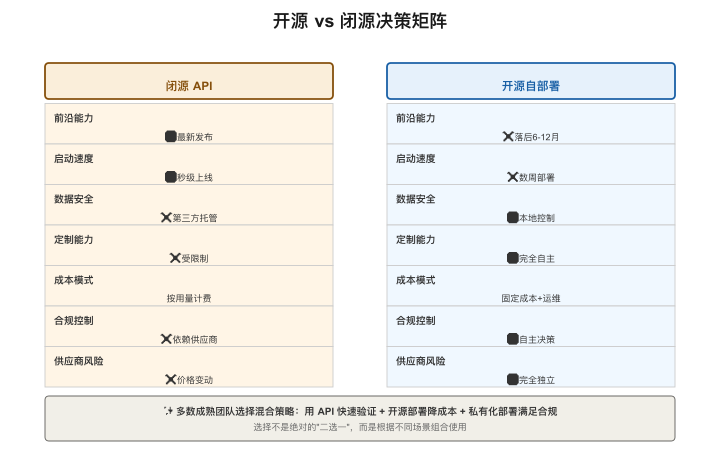
【图5-2:开源vs闭源决策矩阵】
| 维度 | 闭源API | 开源自部署 |
|---|---|---|
| 前沿能力 | 领先3-6个月 | 快速追赶中 |
| 启动速度 | 注册即用 | 需搭建部署环境 |
| 数据安全 | 数据发给第三方 | 数据完全自主 |
| 定制能力 | 仅限Prompt/RAG | 可微调/架构改造 |
| 成本模式 | 按量付费 | 固定资产摊销 |
| 合规控制 | 受供应商政策约束 | 完全自主 |
| 供应商风险 | 涨价/停服/策略变 | 无绑定风险 |
产品架构师的选择框架:
选闭源API的条件(符合以下任一):
- 快速验证阶段——先跑通再说,投入最小
- 团队没有GPU资源和运维能力
- 对前沿能力有硬需求(如最新的推理能力)
- 调用量不大,算下来API费用<私有化年化成本
选开源自部署的条件(符合以下任一):
- 数据合规要求,绝对不能出境
- 需要深度定制模型行为(微调、知识注入)
- 调用量极大且稳定,私有化TCO已有优势
- 无法接受供应商绑定风险
我现在最常用的策略是混合——用闭源API处理能力要求最高的核心流程,用开源自部署处理高频/敏感数据/成本敏感的场景,通过AI网关统一路由。这样既能用到最强能力,又能把成本控在合理范围内。
5.3 大小之辩:不是越大越好
"更大的模型更聪明"——这句话不能说错,但在产品场景中,它是一个危险的简化。
类比:问"哪种车最好",答案一定是"看你跑什么路"。F1赛车上赛道最快,但你每天上下班开它,油钱和停车费能压垮你。大模型也一样——最强的模型在你的场景里不一定"最好用"。
参数量 ≠ 产品表现
我自己做代码审查助手的教训已经说过了。再来一个角度:
你有一个"合同信息提取"任务——从一份合同里提取签约方、金额、日期、违约条款。这个任务有清晰的结构,输入输出都是固定格式。
- GPT-4o:准确率 97%,延迟 1.2s,成本 $15/百万tokens
- Qwen-7B(LoRA微调,专门训合同提取):准确率 95%,延迟 0.2s,成本 $0.1/百万tokens
2%的准确率差距,换来了6倍速度提升和150倍成本降低。在月均100万次调用的情况下,这意味着每月节省约百万元。
这就是"场景专用小模型 vs 通用大模型"的典型价值差距。
模型大小的选择本质
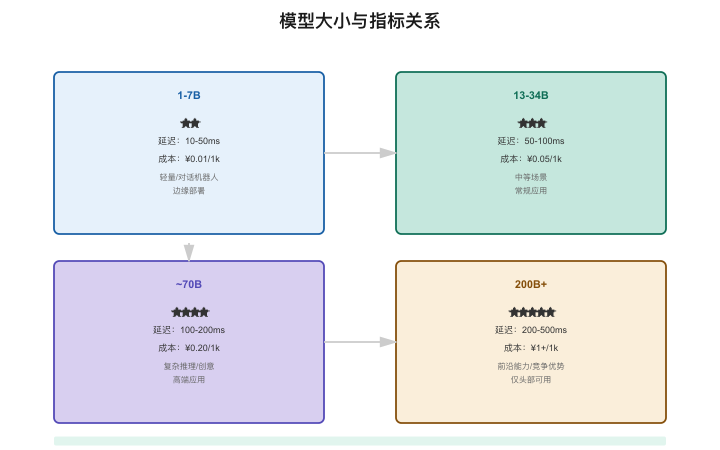
【图5-3:模型大小与产品指标关系】
| 模型规模 | 能力天花板 | 推理延迟 | 单次成本 | 适合场景 |
|---|---|---|---|---|
| 1-7B | ★★★ | 极快(<50ms) | 极低 | 分类、提取、简单QA、格式转换 |
| 13-34B | ★★★★ | 快(50-300ms) | 低 | 通用对话、摘要、翻译、中等推理 |
| 70B+ | ★★★★★ | 中等(300ms-2s) | 中 | 复杂推理、长文创作、高质量分析 |
| 200B+/MoE | ★★★★★+ | 较慢(1-5s) | 高 | 前沿能力、核心高价值任务 |
产品架构师的三条"大小"原则:
① 从小往大试,不要从大往小降。 先用最小的模型试效果——不够再升级。从大往小降会有心理阻力("我已经在用最好的了"),而且往往已经在大模型上做了很多Prompt调优,切换小模型需要重做。
② 多模型协作比单模型选优更重要。 一个成熟的AI产品通常是:简单意图判断走7B,真正任务走70B,输出安全审核走专用安全模型。路由成本(AI网关)远低于全程跑大模型的成本。
③ 微调后的小模型往往比通用大模型更适合垂直场景。 如果你的任务固定、有标注数据,一个微调过的7B可以在你的场景上碾压开箱即用的70B。关键是"有没有足够的高质量标注数据"——这往往是限制因素。
5.4 模型江湖格局:各家的差异化定位
我不打算给你一个"2026年最强模型排名"——那东西半年后就过期了,写进书里就是负资产。
我给你的是各家的战略定位和使用场景的适配性——这些趋势相对稳定,哪怕模型版本换了,选型逻辑依然成立。
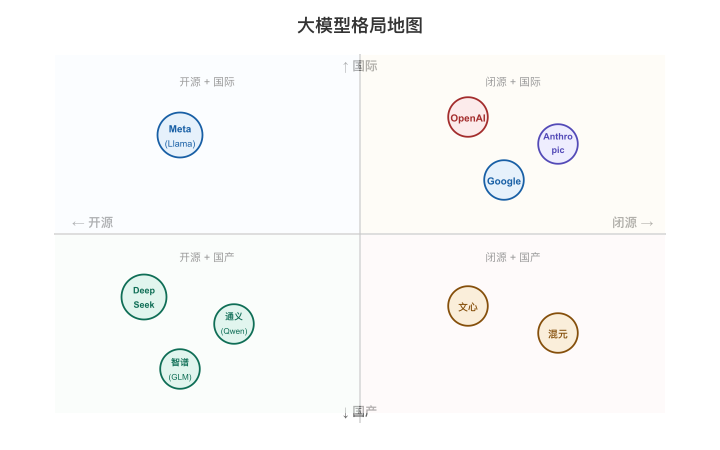
【图5-4:大模型格局地图(四象限)】
X轴:开源←→闭源;Y轴:国际←→国产。各家按定位标注在象限里。
国际玩家:各有绝招
| 厂商 | 代表模型 | 差异化定位 | 最适合场景 |
|---|---|---|---|
| OpenAI | GPT-4o / o1 / o3 | 综合能力天花板、推理深度、生态最大 | 最难的任务、需要最强能力兜底 |
| Anthropic | Claude 3.5 / 4 | 长文本处理最佳、安全性、指令遵从 | 长文档分析、需要高度合规的场景 |
| Gemini 1.5 / 2 | 超长上下文(1M+)、多模态强 | 超大文档处理、视频/图文理解 | |
| Meta | Llama 3 / 4 | 开源领头羊、社区生态最大 | 自部署基座、微调起点首选 |
一个选型直觉:如果你的任务需要"最难的推理"和"最宽的能力边界",首选OpenAI。如果你的任务是"处理超长文档"或"需要极高的指令执行准确度",Claude通常更稳。
国产玩家:合规+性价比+生态
| 厂商 | 代表模型 | 差异化定位 | 最适合场景 |
|---|---|---|---|
| DeepSeek | V3 / R1 | 极致性价比、开源、中文强、推理能力强 | 成本敏感+需要好效果的场景,首选 |
| 阿里(通义) | Qwen-2.5系列 | 全尺寸覆盖(0.5B到72B)、工具调用好 | 全栈AI应用开发,需要不同规模适配 |
| 腾讯(混元) | 混元大模型 | 搜索/推荐/广告场景深度优化 | 腾讯生态内业务、ToC内容生成 |
| 百度(文心) | ERNIE 4.0 | 中文语义深度优化、搜索增强 | 中文知识问答、搜索场景 |
| 智谱(GLM) | GLM-4 | 学术底蕴、中文对话质量稳定 | 教育/科研/中文通用对话 |
一个重要的选型考量:如果你的产品数据不能出境,国产模型是唯一选项。在这个约束下,DeepSeek(开源可私有化)和通义(全尺寸覆盖)通常是最优先考虑的两个。
格局的几个关键趋势(用来建立选型直觉,不是预测未来)
趋势一:开源和闭源技术差距持续收窄。 2023年开源落后约1年,2025年差距已缩到3-6个月。这意味着大多数场景越来越不需要为了能力溢价支付闭源的高价。
趋势二:价格在雪崩式下降。 2024年一年内主流模型API价格降了5-10倍,这个趋势还在持续。这有一个重要的产品架构含义——今天因为成本原因没法做的功能,明年可能直接免费了。所以选型不要只看现在的价格,要想一想"这个价格趋势会如何影响我的商业模型"。
趋势三:推理能力分化出新赛道。 o1/o3/R1这类"思考型"模型出现了——它们用更多的计算换取更深的推理质量,延迟可能是普通模型的5-20倍。产品架构师要判断:你的场景需要的是"快速回答"还是"深度思考"?两者的最优模型选择可能完全不同。
产品架构师的总原则:不要和任何一个模型深度绑定。 今天最强的,6个月后可能不是了。通过标准化接口(OpenAI兼容格式)和AI网关,让模型成为可热切换的零件,而不是系统的核心依赖。
5.5 模型选型方法论:四步流程
到了最实用的部分。我把自己做了十几次模型选型后形成的判断流程,整理成了下面这四步——每一步都来自真实的教训。
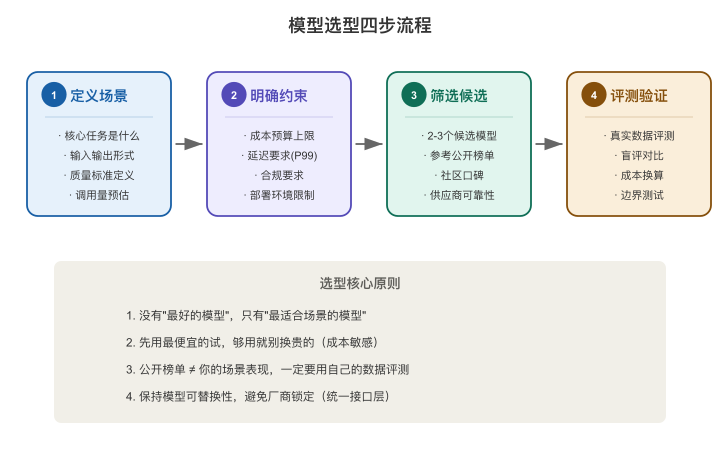
【图5-5:模型选型四步流程图】
横向流程:定义场景 → 明确约束 → 筛选候选 → 评测验证
Step 1:定义场景和任务("你到底要模型干嘛")
这是最常被跳过的一步,也是最多选型失败的根因。
我见过太多团队在没想清楚"任务是什么"之前就开始测模型——结果测到一半才发现测的指标和业务根本不对齐,所有测试报废,重头再来。
在选模型之前,必须能回答这几个问题:
- 核心任务类型:生成?分类?提取?推理?对话?
- 输入形式:用户短消息?长文档?结构化数据?图片?
- 输出要求:自由文本?固定格式?JSON?分类标签?
- 质量底线:可以接受几%的错误率?错误的后果是什么?
- 使用方式:单轮调用?多轮对话?需要多长的上下文记忆?
经验之谈:很多选型失败的根因是"任务定义太模糊"。比如"做一个AI助手"——AI助手做什么?回答通用问题?还是处理特定业务流程?这两个任务对模型能力的要求可能完全不同。
Step 2:明确约束条件(先排除"不可能用的")
约束是筛选的起点,不是评优的终点。排在前面的约束直接决定了哪些模型根本不在候选名单里。
| 约束维度 | 需要确认的问题 |
|---|---|
| 合规/数据安全 | 数据能否出境?能否用非国产服务?需要私有化部署? |
| 成本预算 | 每月推理费用上限?单次调用可接受的成本? |
| 延迟要求 | TTFT需要多少ms以内?总响应时间上限? |
| 部署环境 | 有GPU集群吗?纯API还是可以自部署? |
| 上线时间 | 多久内需要上线?有没有时间做微调? |
关键原则:硬约束优先。 合规是硬约束,GPT-4o再强,数据不能出境就不在候选名单里,不需要测。先用硬约束做减法,剩下的才用软约束做排序。
我在做AI网关相关选型的时候,第一个问题永远是"数据能不能出境"——因为这个问题的答案直接让候选集减少一半。
Step 3:筛选候选模型(限定2-3个,不要多)
基于Step 1和Step 2,把候选集缩小到2-3个。不要一开始就测10个——测太多分散精力,而且模型之间差距没你想的大,真正的差异往往来自Prompt设计和数据质量,不是模型本身。
筛选的三个步骤:
- 硬约束排除:不满足合规/预算/部署要求的直接出局
- 能力维度粗筛:根据Step 1的核心任务,公开评测数据是否达标
- 差异化分析:留下的2-3个候选之间,核心差异是什么
常见的候选组合模式:
- 方案A(效果优先):闭源最强(GPT-4o/Claude)
- 方案B(平衡):开源大模型(Qwen-72B/DeepSeek-V3)
- 方案C(成本优先):开源小模型+微调(7B/14B)
这三个方案通常覆盖了大多数产品的选型决策空间。
Step 4:基于真实场景的评测验证
这是最关键的一步,也是最常被跳过的。
很多团队看完排行榜就拍板了——包括当初的我。但排行榜的benchmark和你的真实场景可能天差地别:benchmark用的是标准化短文本,你的任务可能是500字的长输入;benchmark评的是通用能力,你的场景有特定的行业术语和输出格式。
【图5-6:评测Checklist模板】
| 评测项 | 具体做法 |
|---|---|
| 构建测试集 | 从真实业务数据中抽取50-200条代表性样本,覆盖简单/中等/困难 |
| 定义评价维度 | 准确率?格式正确率?信息完整度?用户满意度?明确权重 |
| 统一测试条件 | 相同Prompt、相同temperature、相同max_tokens |
| 盲评 | 让评测者不知道哪个回答来自哪个模型——减少主观偏见 |
| 分场景统计 | 简单case和难case分开看——整体均分会掩盖关键差异 |
| 成本换算 | 用实际输入/输出token长度换算真实月成本 |
| 延迟实测 | 用真实输入长度(非benchmark短文本)测TTFT和TPS |
一个我用过的评测结论格式:
评测结论:内部代码审查助手(第二版选型)
候选模型:GPT-4o / DeepSeek-V3 / Qwen-14B(LoRA微调)
测试集:200条真实代码审查请求(混合简单/中等/复杂)
结果:
- 规范命中率:GPT-4o 91% / DeepSeek-V3 85% / Qwen-14B 87%
- P50 TTFT:1.8s / 0.4s / 0.2s
- 月成本(3万次/月):¥8万 / ¥0.8万 / ¥0.06万
决策:选 Qwen-14B(微调版)
理由:规范命中率与GPT-4o差4%,但这4%可以通过补充训练数据缩小。
速度快9倍,成本低130倍。这是这次选型真正重要的两个维度。5.6 选型心法:五条不后悔的原则
最后,总结几条在多次选型实践中验证过的原则:
1. 不要追新——追"稳"
最新版本的模型往往API不稳定、文档滞后、社区经验不足。除非新版本在你最关心的维度上有明显提升,优先选上一代已经稳定运行的版本。"稳"在生产环境里是比"强"更重要的特性。
2. 不要绑死——保持可替换
今天最优的选择,6个月后可能已经被新出的模型替代。从架构设计上,通过标准化接口(OpenAI兼容格式)和AI网关让模型成为可热切换的组件——这不只是一个工程决策,是避免被供应商绑死的商业决策。
3. 先跑通链路,再优化模型
很多团队花了几个月选模型,结果上线后发现瓶颈在RAG检索质量、在Prompt设计、在数据清洗——和模型选型无关。先用一个"够用"的模型把整条链路跑通,搞清真正的瓶颈在哪,再针对性优化模型或其他环节。
4. 场景精确度 > 模型通用能力
通用排行榜高≠你的场景效果好。专门微调的小模型往往在垂直场景上超过通用大模型。我自己的两次直接教训(代码审查助手、合同提取)都在证明这一点。
5. 成本是变量,不是常量
模型能力在提升、价格在下降——这两个趋势都还在继续。今天"太贵用不起"的功能,明年可能已经是白菜价。做选型的时候,不只要看现在的成本,还要估一下"半年后这个成本会是什么水平"——这会影响你今天做多大的工程投入。
本章小结
-
选型的根本是场景匹配,不是能力排名——7个维度的权重取决于你的任务,综合最强≠你的场景最优。
-
开源vs闭源是商业决策——技术差距在缩小,真正的区别在控制力、数据合规、成本模式和供应商风险。
-
不是越大越好,专用小模型有竞争力——微调后的7B在垂直场景可以碾压开箱即用的70B。从小往大试,不要从大往小降。
-
四步选型流程:定义场景→明确约束(硬约束先排除)→筛选2-3个候选→用真实数据评测。跳过第4步的选型几乎必然返工。
-
架构上保持模型可替换——通过标准化接口和AI网关,让模型成为零件而非依赖。今天绑死的代价,在6个月的快速迭代期里会被无限放大。
第一部分到这里就结束了。从"大模型是什么"(第1章),到"技术链路全景"(第2章),到"训练怎么发生的"(第3章),到"推理怎么服务的"(第4章),到"模型怎么选"(第5章)——这五章建立的是一套完整的认知地基。
第二部分开始,我们进入"核心技能"——Prompt工程、RAG、Agent。从"知道是什么"到"能自己动手做出来"。
延伸阅读
- LMSYS Chatbot Arena(https://chat.lmsys.org/)—— 基于真人盲评的模型排名,比固定benchmark更贴近真实对话体验
- OpenAI Evals 框架文档 —— 学习如何系统地评测LLM在特定任务上的效果
- 各模型官方文档的Pricing页面 —— 做真实成本估算的第一手数据,每个季度变化很大