学习笔记-AIGC全栈认知与落地(4)
第4章 · 大模型推理加速与服务化落地
开场:从"训完了"到"能用"之间的鸿沟
算法团队发来消息:"模型训完了!效果评测很好,明天给你看Demo。"
Demo确实惊艳。你开始兴奋地盘算上线时间表。然后,现实的问题接踵而至:
- "一次推理要6秒——用户能等吗?"
- "一台8卡服务器每分钟只能处理15个请求——够吗?"
- "按这个速度,如果上万人同时用,需要多少GPU?算一下成本……"
- "算下来每月推理费用80万——商业模式能Cover吗?"
这就是"训完"和"能用"之间的真实鸿沟。
训练是花三年读博,推理是每天接诊看病。 读博只需要图书馆和时间,你可以一个人闷头学。接诊需要诊室、护士、挂号系统、排队管理、急诊分流——这完全是另一套体系,另一种工程思维。
这一章,我们就讲这套"接诊体系"。
我记得第一次和推理优化团队开会,他们说"TTFT现在P99是4.2s,需要压到1s以下"。我当时心里想:TTFT是什么?P99又是什么?这些数字对产品有什么影响?那次会我基本是个听众。后来我才发现,这些指标不只是技术数字——它们直接决定了你的产品在用户面前的体验是"流畅对话"还是"等待焦虑"。推理层的性能指标,是产品架构师必须能读懂的语言。
4.1 训练 vs 推理:两件完全不同的事
在第3章我们讲了"怎么造模型"。很多人会直觉地认为:训练是"难"的部分,推理只是"跑一下"。
错。它们面对的是完全不同的工程挑战。
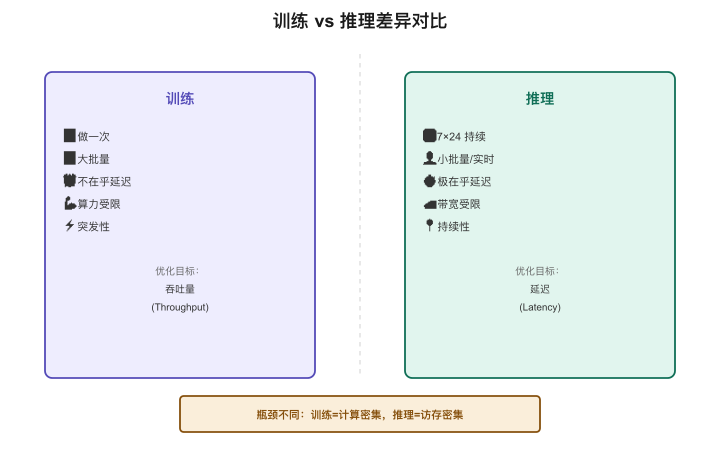
【图4-1:训练vs推理核心差异对比】
| 维度 | 训练 | 推理 |
|---|---|---|
| 频率 | 做一次(或偶尔微调) | 7×24小时持续运行 |
| 批量 | 超大batch(数千样本/批) | 小batch(1-几十个请求) |
| 延迟要求 | 不在乎(慢就等着) | 极在乎(用户在等) |
| 核心指标 | loss能不能降下去 | TTFT、TPS、QPS |
| 瓶颈 | 计算量(算力受限) | 显存带宽(IO受限) |
| 硬件选择 | 最强算力(H100) | 性价比优先(可以用L40S/A10) |
| 故障影响 | 重启续训就行 | 用户直接感知服务中断 |
| 资源模式 | 突发性(训完就释放) | 持续性(必须always-on) |
一个关键洞察:训练的瓶颈是算力(计算密集),推理的瓶颈往往是显存带宽(访存密集)。
这意味着:训练时GPU的计算核心在满负荷工作,但推理时GPU的计算核心可能只在"等数据从显存搬过来"——这就是为什么推理优化的很多技术都在解决"怎么更高效地访问显存"这个问题。
这个区别对产品架构师的实际影响是:评估推理系统时,光看GPU型号不够——还要看显存带宽。 一块新型号GPU的算力可能是老型号的2倍,但如果显存带宽没有相应提升,推理速度的实际提升可能只有30%。这也解释了为什么训练和推理可以用不同类型的GPU——H100是训练王者,但A10在推理性价比上可能更合适。
4.2 推理的不可能三角:延迟、吞吐、成本
做推理优化时,你会很快撞上一个根本性的约束——三个指标不可能同时最优:
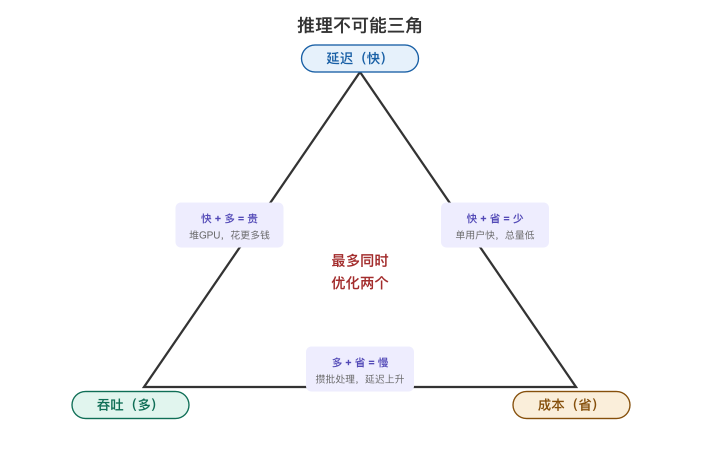
【图4-2:推理不可能三角】
延迟(Latency)——用户体验的命门
两个关键指标:
- TTFT(Time To First Token):从用户发送请求到看到第一个字的时间。这是"感知速度"的核心。
- TPS(Tokens Per Second):后续token的生成速度。这决定"流畅感"。
用户的直觉是:
- TTFT < 1s:感觉"很快"
- TTFT 1-3s:可以接受
- TTFT > 5s:开始焦虑
- TTFT > 10s:想关掉页面
吞吐(Throughput)——系统容量的天花板
- QPS:每秒能处理多少个请求
- 并发数:同时能服务多少用户
这直接决定了"你需要多少台GPU服务器"。
成本(Cost)——商业模式的底线
- $/M tokens:每百万token的费用
- GPU利用率:你花钱买的GPU,有多少时间在真正干活
不可能三角的取舍
| 你的选择 | 延迟 | 吞吐 | 成本 | 适合场景 |
|---|---|---|---|---|
| 大模型 + 多副本 | ✅快 | ✅高 | ❌贵 | 高端AI产品(不差钱) |
| 大模型 + 少副本 | ❌慢 | ❌低 | ✅省 | 离线/批量处理 |
| 小模型 + 量化 | ✅快 | ✅高 | ✅省 | 简单任务(分类/提取) |
| 大模型 + 量化 | ✅较快 | ✅中 | ✅较省 | 大多数生产场景的折中 |
产品架构师的核心判断:你的场景对哪个指标最敏感?
- 实时对话 → 延迟优先
- 高并发API服务 → 吞吐优先
- 内部工具/非实时场景 → 成本优先
先想清楚优先级,再选技术方案——而不是反过来。
4.3 推理加速:五项关键技术
过去两年,推理优化是AI工程领域进展最快的方向之一。你不需要能实现这些技术,但需要理解每项技术"解决什么问题""有什么代价"——这是和算法/Infra团队沟通的基础语言。
技术一:KV Cache——不要重复算已经算过的
问题:在对话中,模型每生成一个新token时,需要回看整段上文。如果每次都重新计算所有上文的Attention,计算量会极其浪费。
解决方案:把之前计算过的Key和Value矩阵缓存起来,下一步直接复用。
类比:考试时可以翻前面的草稿纸。你在前面步骤算出了中间结果,不用每次重新算——直接翻出来看一眼就行。
第1个token生成时:计算全部上文的K,V → 缓存
第2个token生成时:复用缓存的K,V + 只计算新增的部分
第3个token生成时:同上
...
→ 每步只做增量计算,而不是全量重算代价:KV Cache占显存。对话越长、并发越多,Cache越大。一个128K上下文的长对话,KV Cache可能吃掉几十GB显存——和模型本身一样大。
产品含义:长对话比短对话贵,不只是因为token多——还因为KV Cache吃显存,限制了并发能力。
这是我曾经踩过的一个真实的坑:我们做一个客服场景,发现随着对话轮数增加,系统的并发能力在下降——而不是保持稳定。排查了很久才发现,是KV Cache把显存越吃越多,导致同时能服务的用户数越来越少。解法是设置对话轮数上限,超过就自动总结+清空历史,但这个trade-off需要在产品层面决定——不是纯技术问题。
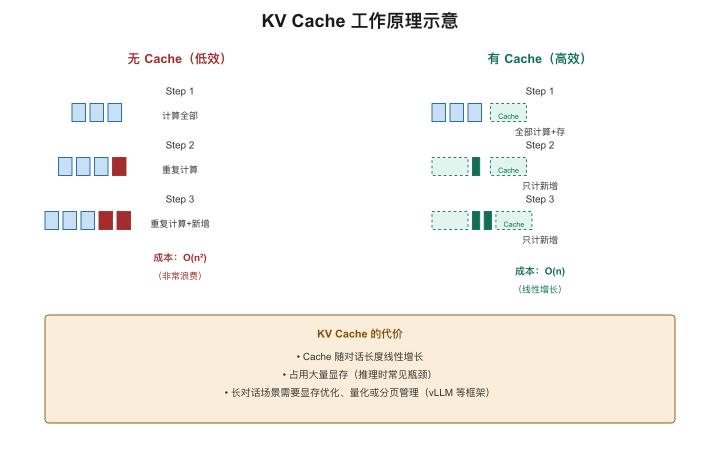
*【图4-3:KV Cache工作原理示意】**
技术二:量化(Quantization)——给模型"瘦身"
问题:模型参数默认用FP16(半精度浮点数,每个参数2字节)存储。一个70B模型需要140GB显存——2块H100才装得下。
解决方案:用更少的位数来表示每个参数。FP16→INT8→INT4,精度递减但空间大幅缩小。
类比:高清照片压缩成JPEG。文件变小了,画质会有一点点损失,但日常使用看不出区别。只有极端情况(放大看细节)才能发现差异。
【图4-4:量化精度对比】
| 精度 | 每参数字节 | 70B模型显存 | 推理速度 | 效果损失 | 适用场景 |
|---|---|---|---|---|---|
| FP16 | 2字节 | 140GB | 基准 | 无 | 训练/高精度推理 |
| INT8 | 1字节 | 70GB | ~1.5-2x | 极小(<1%) | 生产推理首选 |
| INT4 | 0.5字节 | 35GB | ~2-3x | 小(1-3%) | 成本敏感场景 |
产品决策:
- INT8量化是目前"效果几乎无损+成本减半"的甜蜜点——大部分生产场景的默认选择
- INT4适合效果要求不那么极致的场景(如分类、提取、简单QA)
- FP16只有在需要最高精度时才用(如数学推理、复杂代码生成)
技术三:连续批处理(Continuous Batching)——拼车思维
问题:如果每个用户请求都独占GPU直到完成,GPU利用率极低——因为不同请求的生成长度不同,短的请求完了GPU就空着。
解决方案:不等一批请求全部完成再接新的,而是动态地"来一个接一个"。完成的请求离开batch,新的请求随时加入。
类比:传统batch = 旅游大巴(必须凑满一车才走)。连续batch = 顺风车/拼车(有人上有人下,车一直在跑)。
效果:GPU利用率从30-40%提升到70-80%,相当于同样的硬件能服务2倍以上的用户。
踩坑提醒:连续批处理虽然大幅提升了GPU利用率,但它有一个副作用——延迟方差变大了。以前每个请求独立处理,延迟稳定;连续batch之后,你的请求可能和一个"超长回答"被批在一起,你的TTFT因此被拉长。对P99延迟(最慢的1%请求)特别敏感的场景,需要额外做请求优先级设计,避免短请求被长请求拖累。
技术四:投机解码(Speculative Decoding)——让小模型打草稿
问题:大模型生成每个token都要跑一遍完整的前向传播(几百亿参数的矩阵运算),逐token生成天然就慢。
解决方案:
- 用一个小模型(如7B)快速"猜"接下来5-10个token
- 大模型一次性验证这些猜测
- 如果猜对了→直接用(白赚了几步)
- 猜错了→从错误点重新让大模型生成
类比:助手替老板写邮件草稿。助手写得快但不一定完全符合老板意思。老板扫一眼——大部分OK就直接发了,有问题的地方改一下。比老板自己从头写快得多。
效果:在不影响输出质量的前提下(和纯大模型输出完全一致),速度提升30-80%。
技术五:PagedAttention——像操作系统一样管理显存
问题:传统的KV Cache分配是"预先给每个请求分配最大可能的显存"。但大部分请求实际用不了那么多——这导致大量显存碎片和浪费。
解决方案:借鉴操作系统的虚拟内存+分页机制。KV Cache按"页"动态分配——需要多少给多少,不需要了就回收。
类比:租仓库。以前是"按最大可能需求"整租一个大仓库(大部分空间闲置)。现在是"按实际用量"动态租小格子,用多少租多少。
效果:显存利用率提升2-4倍,意味着同一块GPU能同时处理的并发请求翻几倍。这是vLLM能高效服务的核心原因。
推理引擎选型
【图4-5:推理引擎选型对比】
| 引擎 | 开发方 | 核心优势 | 适用场景 | 局限 |
|---|---|---|---|---|
| vLLM | UC Berkeley/开源社区 | PagedAttention、生态好、迭代快 | 通用场景首选 | NVIDIA以外硬件支持有限 |
| TensorRT-LLM | NVIDIA | 性能极致、深度优化 | 追求极致性能 | 学习曲线陡、绑定NVIDIA |
| TGI | HuggingFace | 易用、快速部署 | 快速原型/中小规模 | 大规模性能不如前两者 |
| SGLang | Stanford/开源 | 前端调度优化、RadixAttention | 复杂Prompt场景 | 相对较新 |
产品架构师的选型建议:大多数场景从vLLM开始——生态最好、社区最活跃、性能够用。只有当性能差那5-10%对你的产品至关重要时,才考虑TensorRT-LLM。
4.4 推理服务化:从模型文件到生产级服务
一个模型文件(通常是一堆几十GB的参数文件)变成一个"能7×24稳定服务的API",中间需要一整套工程:

【图4-6:推理服务化核心组件架构图】
模型加载
一个70B FP16模型:
- 模型文件约140GB
- 从磁盘加载到GPU显存需要1-5分钟
- 需要至少2块H100(80GB×2)
这意味着:GPU实例不能像普通服务一样"秒级启动"。弹性扩容时需要预热池——提前加载好模型等着用。
流式输出(Streaming)
上一章讲过:AI的回答是逐token生成的。流式传输(SSE/WebSocket)让用户"边看边等":
- 首字出来后用户就开始阅读→感知延迟 = TTFT而非全量生成时间
- 这是一个"工程成本几乎为零但体验改善巨大"的设计
弹性扩缩容
AI流量的特点:白天是晚上的5-10倍,工作日是周末的2-3倍。
- 扩容挑战:GPU实例启动慢(模型加载1-5分钟)→ 需要预测性扩容
- 缩容决策:GPU很贵,空闲也在烧钱 → 缩容要激进但不能太激进
- 实际做法:保持一定的"预热实例"+ 预测性扩容 + 突发流量排队/降级
多模型路由
一个集群可能同时跑多个模型(不同大小、不同版本):
- 简单任务路由到7B模型(快且便宜)
- 复杂任务路由到70B模型(效果好)
- 灰度发布新版本(10%流量到新模型,对比效果)
这就需要一个"路由层"来做流量分配——这正是AI网关的核心工作之一。
故障处理
GPU不是100%可靠的:
- 单卡故障→自动摘除坏节点,流量切到健康节点
- 显存OOM→请求过长触发OOM,需要拒绝+告警
- 推理卡死→超时熔断+重启实例
产品架构师关注点:故障时用户体验怎么设计?是返回错误、降级到小模型、还是排队等待?这是产品决策,不是纯技术决策。
4.5 AI网关与MaaS:模型服务的"控制面"
如果推理引擎解决的是"模型能不能跑起来"——AI网关解决的是"这个服务怎么管好、用好、卖好"。
这是我工作中最直接参与的层。做AI网关产品这件事,让我对"什么叫做真正的AI基础设施"有了新的认识——它不是简单的"API透传",而是一套完整的治理体系。当你接入了十几个模型、服务着几百个业务方、每天处理几千万次调用的时候,没有一个靠谱的网关层,整个体系就是裸奔。
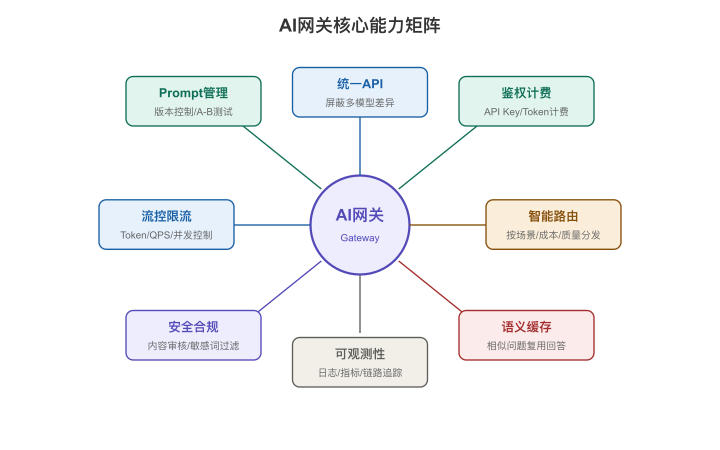
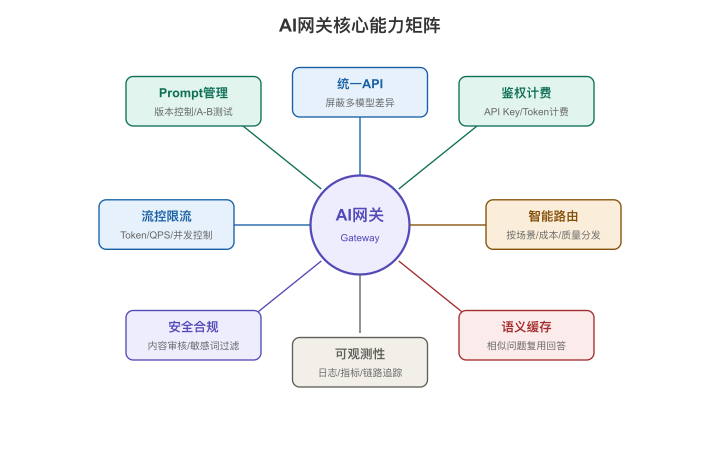
【图4-7:AI网关核心能力矩阵】
| 能力域 | 具体能力 | 解决什么问题 |
|---|---|---|
| 接入管理 | 统一API、多模型封装、协议适配 | 开发者不用关心底层差异 |
| 流量治理 | 鉴权、计费、限流、配额、灰度 | 防滥用、控成本、安全发布 |
| 智能路由 | 按模型/场景/成本/延迟路由 | 自动选最优后端 |
| 语义缓存 | 相似问题命中缓存直接返回 | 节省30-70%推理成本 |
| Prompt管理 | System Prompt版本化、AB测试 | 效果可迭代、可回滚 |
| 可观测性 | 日志、监控、告警、Token统计 | 知道发生了什么、花了多少 |
| 安全合规 | 输入输出过滤、脱敏、审计 | 合规底线 |
为什么推理引擎上面还要再加一层
推理引擎(vLLM等)专注做一件事:把token快速生成出来。它不管:
- 这个请求有没有权限
- 这个用户今天用了多少额度
- 这个回答有没有违规内容
- 应该路由到哪个模型
这些"管理层"的事,就是AI网关的工作。
类比:推理引擎 = 厨师(只负责做菜),AI网关 = 前厅经理(负责接客、点单、收银、质检、投诉处理)。
语义缓存:最容易被低估的降本手段
传统缓存是精确匹配——问题一模一样才命中。但用户不会用完全相同的话问同一个问题。
语义缓存的做法:把问题转为向量,计算语义相似度。如果相似度超过阈值(如0.95),就直接返回之前的答案而不调模型。
效果:
- 企业知识库问答场景:命中率30-50%
- 客服场景:命中率50-70%
- 意味着推理成本直接降低对应比例
产品决策:命中阈值设多少?太高→不命中白花钱;太低→给错答案影响体验。这是一个需要调参和监控的trade-off。
MaaS:云厂商的核心商业模式
Model as a Service——把模型能力封装成标准API,按调用量付费。
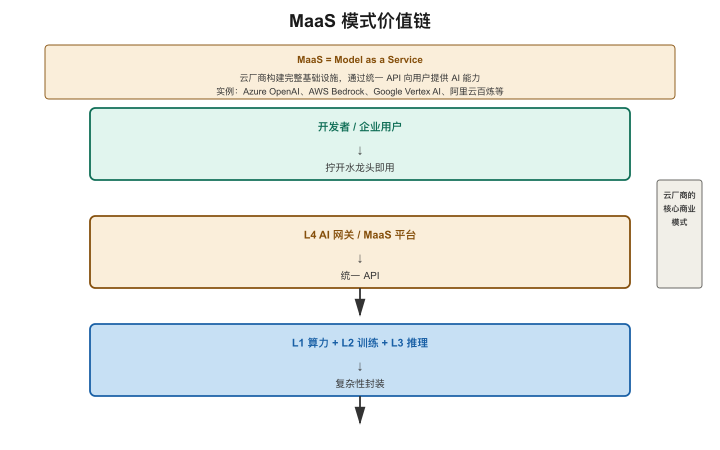
【图4-8:MaaS模式价值链】
底层(L1-L3):算力+训练+推理 → 中间(L4):AI网关/MaaS平台 → 上层:开发者/企业用户
价值链标注:云厂商在中间层把复杂性封装掉,对外暴露简单API
类比:你不需要有发电厂就能用电,不需要有水处理厂就能喝水。MaaS让你不需要有GPU集群就能用大模型。
竞争格局:
- OpenAI API:能力最强,但价格高、数据出境
- AWS Bedrock:多模型商店,灵活但复杂
- Azure OpenAI:企业合规首选,OpenAI绑定
- 腾讯云/阿里云/百度云:国产模型+合规+私有化选项
产品架构师的判断:选MaaS平台不只看模型能力——还要看计费模型、SLA、合规、数据驻留、多模型灵活度。
4.6 产品架构师的"推理成本语感"
这是本章最实用的部分。我要帮你建立对推理成本的直觉——不需要精确计算,但要能快速估算"这个方案大概花多少钱"。
Token计费的直觉
| 模型级别 | 输入价格($/M tokens) | 输出价格($/M tokens) | 1000次对话(平均)约花 |
|---|---|---|---|
| GPT-4o | $2.5 | $10 | ~$10-30 |
| Claude 3.5 Sonnet | $3 | $15 | ~$15-40 |
| DeepSeek-V3 | ¥1 | ¥2 | ~¥3-8 |
| 7B开源模型(自部署) | ~$0.1 | ~$0.1 | ~$0.2-0.5 |
降本手段优先级
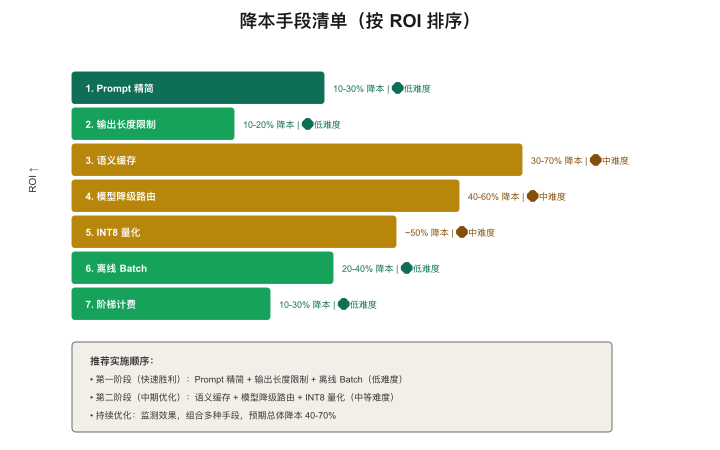
【图4-9:降本手段清单(按ROI排序)】
| 优先级 | 手段 | 预期降本 | 实施难度 | 有无效果损失 |
|---|---|---|---|---|
| 1 | Prompt精简(去冗余指令) | 10-30% | 低 | 无 |
| 2 | 输出长度限制(max_tokens) | 10-20% | 低 | 可能截断 |
| 3 | 语义缓存 | 30-70% | 中 | 极小 |
| 4 | 模型降级路由(简单任务→小模型) | 40-60% | 中 | 需评估 |
| 5 | INT8量化 | ~50% | 中 | 极小(<1%) |
| 6 | 非实时任务走离线batch | 20-40% | 低 | 延迟增加 |
| 7 | 协商阶梯计费/预留实例 | 10-30% | 低 | 无 |
黄金法则:从上到下依次尝试,每一步都是"投入产出比最高"的顺序。 很多团队直接跳到第5步搞量化优化,其实前4步就能解决80%的成本问题。
私有化 vs API调用的成本分界线
粗略估算:
- 一台8卡H100服务器年总成本(含硬件折旧+运维+电费+人力):300-500万元/年
- 它能持续跑一个70B模型,理论上每年能处理的token数:约500-1000亿tokens
- 折合成API调用价格:约¥0.03-0.05/千tokens
所以:
- 如果你的年调用量 < 100亿tokens → 用API更划算
- 如果你的年调用量 > 500亿tokens → 私有化开始有成本优势
- 中间地带 → 看你是否需要数据不出域等合规要求
大部分公司(日调用量百万级以下)用API远比私有化划算。 只有日调用量千万级以上、或有强合规需求的场景,才值得认真考虑私有化。
还有一个容易被忽视的时间成本:私有化部署从立项到生产上线,通常需要3-6个月(采购、机房、部署、测试、调优)。而调API可以在一天内跑通第一个Prototype。对于大部分AI功能来说,快速验证场景假设的价值,远超过用私有化节省的成本。等你用API验证了方向是对的、用量真的到了临界点,再切私有化不迟。
下一章,我们从"怎么跑"回到"选什么跑"——面对眼花缭乱的GPT、Claude、Gemini、DeepSeek、各家国产模型,产品架构师怎么建立一套系统的选型判断力?答案不是看排行榜,而是一套我在实际项目里反复用到的四步评估框架。
本章小结
-
训练和推理是两套完全不同的体系——训练重计算、做一次、不在乎延迟;推理重IO、7×24持续、极度在乎延迟和成本。
-
推理的不可能三角:延迟×吞吐×成本——你的场景对哪个最敏感?先定优先级再选方案。
-
五大推理加速技术——KV Cache(不重复算)、量化(模型瘦身)、连续批处理(拼车)、投机解码(小模型打草稿)、PagedAttention(按需分配显存)。
-
推理服务化不只是"把模型跑起来"——还需要弹性扩缩容、多模型路由、故障恢复、流式输出等工程能力。
-
AI网关是产品架构师的直接战场——统一API、鉴权计费、智能路由、语义缓存、内容安全、可观测性。
-
降本的正确顺序:Prompt精简→缓存→模型路由→量化→批量化。先做ROI最高的。
延伸阅读
- vLLM论文:《Efficient Memory Management for Large Language Model Serving with PagedAttention》—— PagedAttention的技术原理
- 《Medusa: Simple Framework for Accelerating LLM Generation with Multiple Decoding Heads》—— 投机解码的一种实现
- NVIDIA TensorRT-LLM文档 —— 了解工业级推理优化的全貌