学习笔记-AIGC全栈认知与落地(6)
第6章 · 提示工程——产品架构师的第一个AI硬技能
开场:同一个需求,两种截然不同的结果
那是一个普通的下午。我们团队里两位架构师——我姑且叫他们A和B——需要用AI帮助分析一份竞品文档,输出一份有结构的对比报告。他们拿到了同一个大模型、同样的文档材料。
A发出去的是这个:
"帮我分析这份竞品文档,写一个分析报告。"
B发出去的是这个:
"你是一位有10年经验的产品架构师,擅长SaaS行业的竞品分析。请基于以下竞品文档,从产品定位、核心功能、技术架构、差异化优势四个维度进行对比分析。每个维度用100-200字说明,最后给出一个3条以内的战略建议。输出格式为Markdown,使用##二级标题划分维度。"
A得到了一篇两千字的流水账,里面什么都有但又什么都不深入,格式乱到没法直接用。
B得到了一份可以直接放进PPT的结构化分析,不仅格式对,连用词都接近他平时的报告风格。
两个人用的是同一个模型。差距完全来自Prompt。
我看着这两份输出,想起了自己刚开始用大模型的时候——那段"随便问"的阶段,总觉得AI不够好用,殊不知问题全在自己这边。Prompt工程这件事,听起来很虚,实际上是一项可以系统学习、可以模板化、可以工程化的硬技能。
这一章,我们就把它拆开来讲。
6.1 Prompt的本质:一份给AI的精确需求说明书
从PRD到Prompt:同一种思维
我学会Prompt工程的那个转折点,不是看了什么教程,而是某天突然意识到:我在写Prompt的时候,用的是和写产品需求文档一模一样的思维框架。
想想你写一份PRD的时候在做什么——
- 你要告诉研发团队:角色(谁来做这件事,是前端还是后端?)
- 你要交代:背景(这个需求的上下文是什么,为什么需要?)
- 你要描述:任务(具体要实现什么功能?)
- 你要约束:边界(不需要做什么、不能做什么?)
- 你要规定:输出格式(返回什么数据格式、页面长什么样?)
Prompt的结构和这个一模一样:角色设定 + 背景交代 + 任务描述 + 约束条件 + 输出格式。
区别只是:对象从研发团队变成了大模型,但信息完整度的要求是一样的——甚至更严格,因为模型不会像研发同学那样主动追问你"这里是什么意思?"
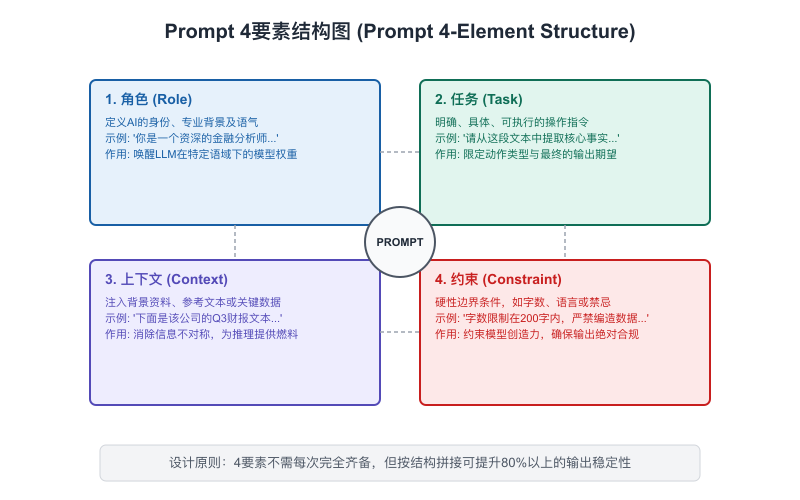
【图6-1:Prompt四要素结构图】
为什么"随便问"效果差
当你只说"帮我写个分析报告"时,模型实际上面临巨大的不确定性:
- 写什么角度的?市场分析?技术分析?用户分析?
- 给谁看的?高管汇报?还是团队内部参考?
- 要多详细?一页纸还是十页纸?
- 什么格式?纯文本、Markdown、表格?
- 语气是什么风格?正式、轻松、咨询报告风格?
模型会做一个"最合理的猜测"——但这个猜测和你的期望很可能相差甚远。
这就像你跟新来的实习生说"帮我做个PPT",然后等他交稿。如果你之前没说清楚,你大概率会拿到一份让你改到想哭的初稿。
"随便问"的代价,不是AI不聪明,而是你没说清楚。 这是一个认知转变,很多人花了很长时间才接受这件事。
Prompt的四个核心要素
一个完整的Prompt通常包含四个部分:
1. 角色设定(Role):告诉模型"你是谁"
你是一位有10年经验的云原生架构师,擅长微服务和Kubernetes...这不是玄学。角色设定会激活模型训练数据里对应职业背景下的知识模式,让输出更贴近那个角色的思维方式和表达风格。
2. 背景交代(Context):告诉模型"这件事的来龙去脉"
我们公司正在评估是否将现有的单体应用拆分为微服务架构。
当前系统有300万日活用户,技术栈是Java Spring Boot + MySQL...背景越充分,模型的回答越贴合你的实际情况,而不是给你一个通用答案。
3. 任务描述(Task):告诉模型"具体要干嘛"
请从技术风险、团队能力要求、迁移成本、预期收益四个维度,
分析这次架构升级的可行性,给出你的评估和建议。任务要具体、可验证——"写一个分析"太模糊,"从X/Y/Z三个维度分析,每个维度200字"就具体多了。
4. 输出格式(Format):告诉模型"输出什么样子"
输出格式要求:
- 使用Markdown格式
- 每个维度用##二级标题
- 最后用一个表格总结优劣势
- 结论部分不超过150字格式约束越清晰,输出越可以直接用——这对需要下游处理(放进报告、接入系统)的场景尤其重要。
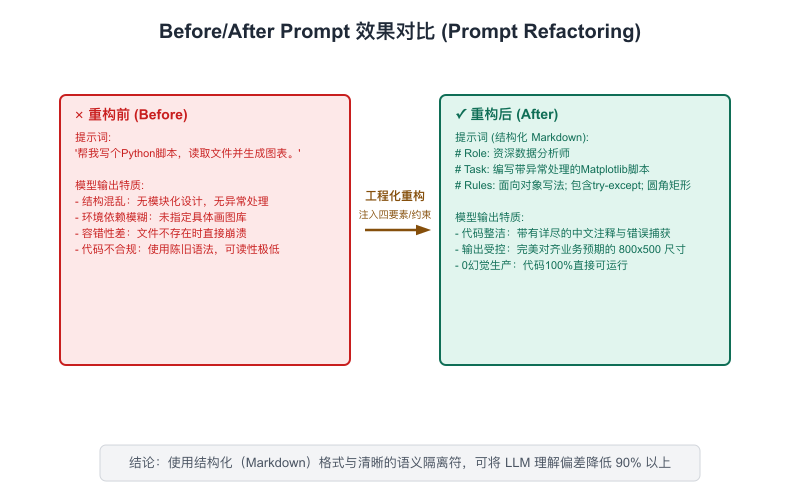
一个完整的Before/After对比
【图6-2:Before/After Prompt效果对比】
Before(差):
帮我分析一下这个技术方案的风险。After(好):
角色:你是一位有经验的技术风险评估专家,熟悉云原生系统设计。
背景:我们计划在下季度上线一个新的AI推荐系统,该系统将接入现有的
电商平台,日均调用量预计50万次,要求P99延迟<500ms。
任务:请从以下三个维度评估技术风险:
1. 系统稳定性风险(服务依赖、单点故障)
2. 性能风险(延迟目标可达性、容量规划)
3. 数据安全风险(用户行为数据处理合规)
输出格式:
- 每个风险维度用###三级标题
- 每个维度:风险描述(2-3句)+ 风险等级(高/中/低)+ 缓解建议(1-2条)
- 最后给一个整体风险评估(不超过100字)这两个Prompt的信息量差了3-4倍,输出质量的差距会更大。
Prompt质量自检:写完后问自己三个问题
每次写完一个Prompt,在发出去之前,我会快速问自己三个问题:
问题一:如果我把这个Prompt给一个聪明的实习生,他看完之后知道要做什么吗?
如果答案是"不确定"——那模型也不会知道。Prompt的清晰度标准是:一个完全不了解背景的人也能照着做。
问题二:我的"期望输出"在脑子里是清晰的吗?
很多人在写Prompt的时候自己都没想清楚要什么。如果你不能在脑子里描述"完美输出"是什么样的,那Prompt里也不可能把它说清楚。先想清楚自己要什么,再写Prompt。
问题三:Prompt里有没有可以更具体的地方?
把所有模糊的形容词换成可量化的标准:
- "简洁" → "不超过150字"
- "专业风格" → "采用McKinsey报告风格,多用数据和逻辑链"
- "全面覆盖" → "覆盖以下三个维度:X、Y、Z"
这三个问题只需要30秒,但能把Prompt的有效率提高50%以上。
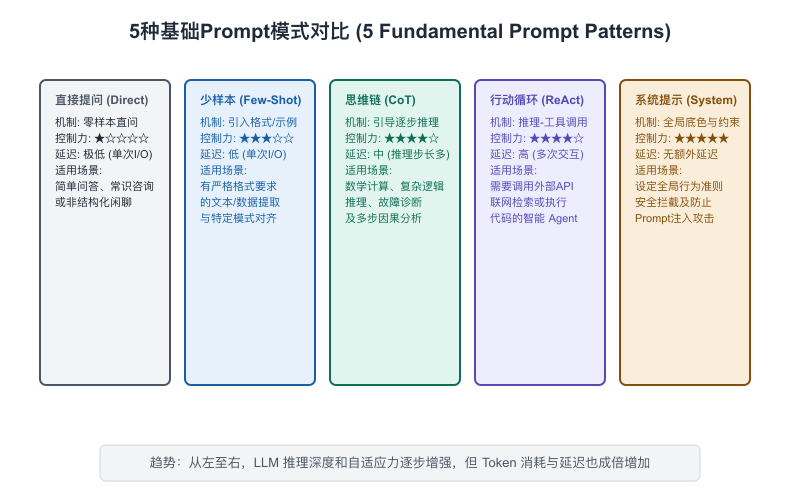
6.2 五种基础Prompt模式
掌握了Prompt的基本结构,下一步是学会几种可以立即上手的模式。这五种模式覆盖了80%的日常使用场景,每种都有固定的套路和适用场景。
【图6-2(补充):五种基础Prompt模式对比卡片】
模式一:角色设定(Role Prompting)——让模型扮演专家
本质:激活模型训练数据中特定职业领域的知识和表达方式。
类比:你聘请了一位顾问,在他开口之前,你先告诉他:"你是一位专注于SaaS增长的前大厂产品总监,面对的是B端企业客户。"他给你的建议会因此和"一位刚毕业的产品助理"给的建议截然不同——不是因为模型变了,而是激活的知识域不同了。
适用场景:
- 需要专业视角的分析(技术评估、商业分析、法律合规)
- 需要特定风格的写作(技术文档、学术摘要、营销文案)
- 需要跨领域思考(从用户视角评价技术方案)
模板:
你是一位[职业+经验年限],擅长[核心专长],
曾经处理过[相关背景]类型的问题。
现在请你[具体任务]...产品架构师使用技巧:角色设定不是越复杂越好。三个要素就够——职业定位、核心专长、相关背景。超过这三个通常是信息过载。
模式二:Few-shot示例——给例子比讲道理更有效
本质:给模型几个"这是好的,这是不好的"的例子,让它学会你的判断标准。
类比:带新员工不是靠讲道理,是靠看案例。你说"写邮件要简洁专业",他理解可能不同;你给他看三封好邮件和三封差邮件,他立刻就知道了。
适用场景:
- 格式固定、需要批量处理的任务(信息提取、分类、格式转换)
- 有特定风格要求的输出(写作风格、措辞习惯)
- 需要模型"猜懂你心思"的任务(主观评估、定制化输出)
模板:
我需要你完成以下格式的信息提取任务。
以下是几个示例:
输入:[示例输入1]
输出:[示例输出1]
输入:[示例输入2]
输出:[示例输出2]
现在请对以下内容做同样的处理:
输入:[实际输入]产品架构师使用技巧:示例的质量比数量更重要。3个高质量示例远胜过10个随手写的示例。示例要覆盖典型情况和边界情况。
一个踩坑经验:我曾经在一个文档分类任务里用了5个示例,全是"这是好的",没有给任何"这是不好的"(负例)。结果模型把所有输入都分成了我示例里的类别,因为它不知道什么情况应该输出"其他/不适用"。Few-shot要同时给正例和反例。
模式三:Chain-of-Thought(CoT)——让模型一步步想
本质:要求模型在给出最终答案之前,先把推理过程写出来。
类比:让实习生不要直接给结论,先把分析过程写出来。一方面他的答案会更准确(写的过程就是在验证逻辑),另一方面你也能看出他是真的想清楚了还是在猜。
为什么有效:大模型的逻辑推理是在生成过程中一步步完成的——如果你直接要结论,模型的"推理空间"就是那短短几个输出token;如果你让它先写推理过程,模型实际上在生成答案之前做了更多的"思考"。
适用场景:
- 数学计算、逻辑推导类任务
- 需要多步分析的复杂问题(风险评估、架构决策)
- 需要追溯推理过程的场景(便于审查和修正)
触发方式:
# 简单触发:
请一步步分析,最后给出结论。
# 更明确的触发:
请先列出你的分析思路,然后逐步推导,最后给出你的建议。
# 最强的触发(适合复杂问题):
请按以下结构思考:
第一步:识别问题的核心约束
第二步:列出可能的方案
第三步:对每个方案评估优劣
第四步:给出你的推荐和理由产品架构师注意点:CoT会让输出变长。如果你只需要结论(比如分类任务),不需要用CoT——它会增加token消耗和延迟。
模式四:结构化输出约束——让输出可以直接用
本质:约束模型输出的格式,让它可以被下游系统直接处理。
类比:与其让员工写一篇自由格式的报告,不如给他一个标准表格填写——既节省审阅时间,又方便汇总。
适用场景:
- AI输出需要接入系统(JSON格式解析、表格导入)
- 需要多维度统一对比(产品评测、方案比较)
- 批量处理时需要一致格式
常见格式约束方式:
# JSON输出
请以JSON格式返回结果,包含以下字段:
{
"风险等级": "高/中/低",
"主要风险点": ["风险1", "风险2"],
"缓解建议": "...",
"置信度": 0.0-1.0
}
# Markdown表格
请以Markdown表格格式输出,列标题为:模型名称 | 核心优势 | 适用场景 | 推荐度
# 固定段落结构
每个分析项目请按以下结构输出:
**问题描述**:...(1-2句)
**影响范围**:...(具体范围)
**建议动作**:...(1-3条可执行建议)踩坑提醒:JSON格式约束有时会让模型"装模作样"——它会输出格式正确的JSON,但里面的内容是编的。如果你的场景对准确性有高要求,JSON输出后必须有验证步骤。
模式五:System Prompt——产品级AI的基础设施
本质:在所有用户输入之前,设置一个固定的"角色定义和行为规范",在整个对话中持续生效。
类比:员工入职培训。你在他正式开始工作前,先告诉他:"我们公司的规定是……我们的服务理念是……遇到这类问题你应该……"这些不需要每次交代,一次说清楚,后面他自然会按这套原则行事。
System Prompt vs 普通Prompt的区别:
- 普通Prompt:每次对话都要写,影响本次对话
- System Prompt:写一次,对所有对话生效;用户的输入在System Prompt之后进入
适用场景:
- 产品中的AI角色固定化("你是XX产品的智能客服,专注于解答……")
- 行为规范设定("你的回答必须基于提供的文档,不得编造")
- 输出风格固定化("所有回答用简洁的中文,不超过200字")
一个好的System Prompt的结构:
## 角色定义
你是[产品名称]的AI助手,专注于[核心职责]。
## 能力范围
你可以:[能做的事]
你不能:[不能做的事,如"不提供具体法律建议"]
## 行为规范
- 回答必须基于提供的材料,不得编造数据
- 如果不确定,明确告知用户你不确定
- 保持专业简洁的语气
## 输出格式
[具体的格式要求]产品架构师关注点:System Prompt是成本大户。如果你的System Prompt有2000 tokens,每次对话的"起步成本"就是2000 tokens——无论用户问多短。精简System Prompt是降低AI产品成本最直接的手段之一(第4章讲到降本手段时也提到了这点)。
6.3 进阶模式:从单次调用到工程化Prompt
掌握了五种基础模式,你在日常工作中用AI的效率就会大幅提升。但如果你在做的是一个AI产品——不是自己用,而是给成千上万用户用——你需要把Prompt从"个人技能"升级为"工程资产"。
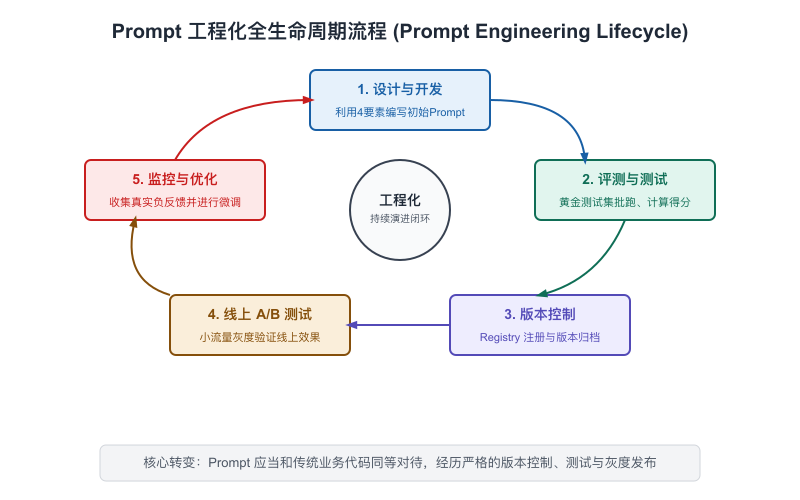
【图6-4:Prompt工程化流程图】
Prompt模板化:让Prompt成为可复用资产
当你有一个好Prompt,下一步是把它变成一个模板——把固定的部分固定下来,把变化的部分用变量占位:
# 竞品分析模板 v1.2
你是一位有{years_of_experience}年经验的{industry}行业产品分析师。
背景:{company_name}正在评估进入{target_market}市场。
请基于以下材料,从以下{analysis_dimensions}个维度进行分析:
{dimension_list}
输出格式:{output_format}
材料:
{source_material}这个模板可以用于不同的竞品、不同的行业、不同的分析维度,而不需要每次从头写。这是Prompt从"一次性工具"到"可重复资产"的关键一步。
产品架构师的判断:什么时候把Prompt模板化?当你发现同一类任务需要反复使用时。一个经验是:如果你已经写了3次类似的Prompt,第4次就应该把它模板化。
Multi-turn策略:对话历史的管理艺术
在多轮对话中,你需要主动管理上下文,而不是被动地让对话越来越长。
策略一:开场定调
对话开始时用一条"定调信息"设定整个对话的规则和目标,而不是每次都重复:
接下来我们要讨论一个技术架构方案。
在整个讨论过程中:
1. 你扮演一位经验丰富的系统架构师
2. 每次回答后,列出你还需要了解的关键信息
3. 最终目标是输出一份可执行的架构决策文档策略二:对话摘要注入
当对话轮数超过10轮,对话历史开始吃token。主动要求模型总结前面的关键信息,然后"清空"历史,带着总结继续:
请把我们目前讨论的核心决策和待解决问题总结成一段话(200字以内),
我将用这个总结继续我们的对话。策略三:明确重置
当话题切换时,告诉模型"上面的讨论已经结束,现在我们来讨论一个新问题"——这样模型就不会被之前的上下文干扰。
输出约束与验证:从Prompt到产品的最后一公里
在产品场景中,模型输出需要接入系统,格式验证必不可少:
# 伪代码示意
response = model.call(prompt)
# 格式验证
try:
data = json.parse(response)
assert "risk_level" in data
assert "suggestions" in data
except:
# 格式错误,触发retry或降级
response = model.call(prompt + "\n请严格按JSON格式输出,不要有任何额外文字")产品架构师的设计原则:不要假设模型总是输出正确格式。为格式异常设计retry逻辑和降级方案——这和你为API超时设计重试逻辑是一样的思维。
Prompt AB测试:哪版Prompt更好
当你有两个候选Prompt时,用数据决定而不是靠感觉:
- 测试集:准备50-100条真实业务输入
- 评估维度:准确率、格式符合率、输出长度(成本)
- 评测方式:有条件做人工盲评,没条件用另一个LLM做自动评测
- 决策规则:质量提升>5%且成本不超过10% → 切新版;质量提升<5%但成本降低>20% → 也值得切
Prompt版本管理:Prompt也是代码,要有版本号、要有测试、要有回滚机制。一个简单的做法是在代码仓库里为每个Prompt创建一个Markdown文件,用git管理版本历史。
一个真实的惨痛教训:我们有一次对一个核心功能的System Prompt做了优化,没有走版本管理流程,直接覆盖部署了。上线后两天发现某类输出质量下降,排查了很久才发现是新Prompt在一个特定场景下有问题。但因为没有版本历史,我们连"改了什么"都要靠记忆来重建。最后用了大半天时间才恢复。
经验之谈:把Prompt版本管理纳入你的上线流程——和代码变更一样要有审批、要有测试、要有备份。Prompt变更引起的问题和代码bug一样严重,但大多数团队的保护机制却远不如代码规范。
实时Prompt质量监控
Prompt部署之后并不是万事大吉。随着用户输入的变化、模型版本的更新(很多云端API会静默更新模型版本),效果可能在你不知情的情况下漂移。
监控的核心指标:
- 格式合规率:输出是否符合你约束的格式(JSON是否可解析、指定字段是否存在)
- 拒答率:模型拒绝回答的比例(过高说明约束太严或有大量不适合的输入)
- 输出长度分布:P50/P95输出token数(异常变长可能是Prompt漂移)
- 用户反馈分:点赞/点踩的比率趋势
告警设置建议:
- 格式合规率下降超过5%:触发告警,检查是否有模型版本更新
- 拒答率超过10%:触发告警,检查输入分布和安全过滤策略
- 平均输出长度增加超过30%:可能有Prompt行为变化,人工审查
这些监控不复杂,但大多数团队在Prompt上线后就"放手不管"了。定期的Prompt健康检查是保持AI系统质量的重要工作,产品架构师要把它列进运营日程里。
6.4 常见反模式:为什么你的Prompt不工作
了解Prompt为什么会失败,比只学"好Prompt是什么样的"更有价值——因为失败有规律,掌握了规律就有了诊断能力。
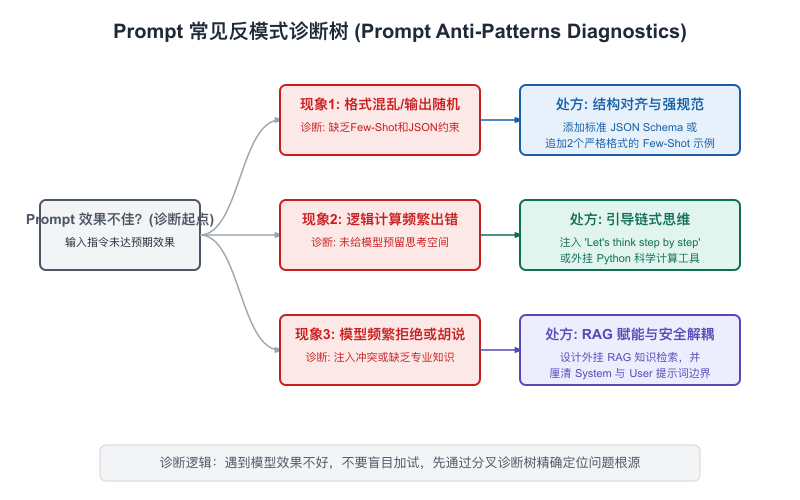
【图6-5:常见反模式诊断树】
从"Prompt效果差"开始,分支到各类问题,每个末端节点标注修复方法。
反模式一:任务描述模糊
症状:输出跑题、太宽泛、不够具体。
根因:你用了"写一个分析""做一个总结"这类动词,但没有告诉模型"分析什么角度""总结到什么深度"。
修法:把任务从动词升级到"动词+维度+深度+边界":
- ❌ "分析这个产品的问题"
- ✅ "从用户体验、核心功能、商业模式三个维度分析这个产品存在的问题,每个维度找出1-2个最关键的问题,给出具体改进建议"
反模式二:背景信息不足
症状:输出太通用,像在讲"一般原则"而不是"你的情况"。
根因:模型不了解你的具体情境,只能给出最大公约数的答案。
修法:补充关键背景——用户规模、技术栈、团队规模、时间约束、已知限制。
# 加了背景之后:
背景:我们是一个50人规模的SaaS公司,主要做B端HR软件,
技术团队15人,主力技术栈是React + Node.js,
明年Q2需要上线一个AI简历筛选功能,预算150万。这些背景信息会让模型的回答从"理论上AI可以……"变成"对于你们这个规模和技术栈,最合适的方案是……"
反模式三:示例选得不好(Wrong Shot)
症状:用了Few-shot示例,但效果还是不好。
根因:
- 示例太简单,不能代表真实输入的复杂性
- 只给了正例,没有反例
- 示例和真实输入的风格差距太大
修法:
- 从真实业务数据中选示例,不要手写理想化的示例
- 同时给正例和反例("这是应该的输出" + "这是不应该的输出,因为……")
- 示例数量3-5个够了,不要超过10个
反模式四:System Prompt指令冲突
症状:模型的行为前后不一致,有时遵守规则有时不遵守。
根因:System Prompt里有互相矛盾的指令,比如"你应该简洁回答(不超过100字)"同时又"你应该详细解释每个细节"。
修法:
- 排查System Prompt里所有的约束性指令("不超过""必须""总是""永远不要"这类词)
- 用一致性检查:把所有约束列出来,看有没有逻辑冲突
- 用优先级来解决冲突:明确告诉模型"如果这两条指令冲突,以第一条为准"
反模式五:期望值超出模型能力
症状:不管怎么调Prompt,模型就是输出不了你想要的东西。
根因:有些任务不是Prompt优化能解决的——它超出了模型的能力上限。比如:
- 要模型做实时数据查询(它没有)
- 要模型做精确的数值计算(它做不可靠)
- 要模型保持跨会话的记忆(它做不到)
诊断方法:
- 这个任务需要模型"知道"一个它训练数据截止后的事实吗?→ 需要RAG/工具调用
- 这个任务需要精确计算吗?→ 需要代码执行器
- 这个任务需要"记住"上次会话的内容吗?→ 需要外部记忆系统
架构师的判断原则:Prompt优化不是万能药。当你优化了5次以上仍然效果不好,先问问自己:这是Prompt问题,还是能力边界问题?如果是后者,答案不是更好的Prompt,而是更合适的技术方案。
反模式六:过度依赖Prompt而忽视数据质量
这是一个更隐蔽的反模式,也是我见过最多团队掉进去的坑。
症状:花了大量时间调Prompt,效果提升始终有限,迭代陷入瓶颈。
根因:数据质量问题被误解为Prompt问题。比如在RAG场景下:
- 知识库里的文档本身是错的或过期的——无论Prompt多好,给错的材料生成的仍然是错答案
- 文档分块策略不对,关键信息被切断——Prompt无法补救检索层的问题
- 测试集本身有歧义——评测分数低不是因为模型不好,而是评测标准不清
修法:遇到效果瓶颈时,先排查数据链路:
- 抽查10条效果差的case,看错误来自哪里:Prompt层、检索层,还是数据本身?
- 错误来自数据本身 → 清洗数据、修正知识库
- 错误来自检索层 → 优化分块和检索策略(第7章展开)
- 错误确认在Prompt层 → 才回到调Prompt
经验公式:效果 = 数据质量 × Prompt质量 × 模型能力。其中任何一项趋近于0,整体效果就趋近于0。大多数人只盯着Prompt,忘了另外两个乘数。
6.5 产品架构师的Prompt工具箱
理论够了,现在来些可以直接复用的模板。这些模板我在实际工作中反复用过,每一个都经过了多轮打磨。
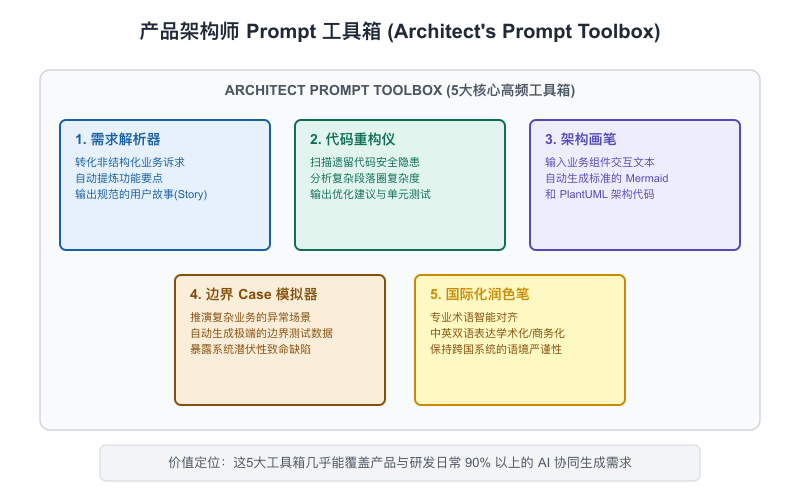
【图6-6:产品架构师Prompt工具箱卡片集】
工具1:方案评审——让AI找漏洞
场景:你有一份技术/产品方案,想在正式评审前找出潜在问题。
角色:你是一位经验丰富的技术架构师,以挑剔著称,
擅长发现方案中的边界情况和潜在风险。
任务:请评审以下方案,你的目标是找到漏洞,而不是夸方案写得好。
重点检查以下几类问题:
1. 技术假设是否成立(有没有依赖未经验证的技术能力)
2. 边界情况处理(极端情况、错误情况有没有考虑)
3. 性能和扩展性(如果流量增加10倍会发生什么)
4. 安全和合规风险(数据安全、访问控制有没有考虑)
5. 实施难点(哪个环节最难实现、风险最高)
输出格式:
每个问题用###标题,包含:问题描述、风险等级(高/中/低)、建议
方案内容:
{your_design_doc}工具2:竞品调研——结构化对比
场景:快速对比多个竞品/方案,输出可以直接放进汇报文档的对比表。
角色:你是一位SaaS产品分析师,擅长竞品分析和市场调研。
任务:对以下{product_count}个产品/方案进行对比分析。
对比维度:{dimensions}
每个维度的评估标准:{evaluation_criteria}
请输出:
1. Markdown表格格式的对比矩阵(行=产品,列=维度)
2. 每个维度的简短说明(2-3句话)
3. 综合建议:我的场景是{your_context},推荐选择哪个,理由是什么
产品信息:
{product_info}工具3:架构文档生成——从设计稿到文档
场景:你在头脑里已经有了架构设计,需要输出一份标准格式的架构文档。
角色:你是一位技术文档专家,擅长将工程师的思路整理成清晰的技术文档。
我将描述一个系统架构设计,请基于我的描述,
输出一份标准技术架构文档,包含以下章节:
1. 设计目标和约束条件
2. 整体架构图说明(文字描述,用ASCII图或列表形式)
3. 核心模块说明(每个模块的职责、输入输出、关键技术选型)
4. 数据流描述(关键业务流程的数据流转)
5. 关键设计决策和背后的理由
6. 已知局限性和待解决问题
语气:技术评审用,清晰专业
我的设计描述:
{your_design_description}工具4:会议纪要处理——提取决策和行动项
场景:一大段会议记录,需要快速提取出有价值的信息。
请处理以下会议记录,提取关键信息。
输出格式(严格按以下结构):
**会议主题**:(1句话)
**核心决策**(已拍板的事):
- [负责人] 事项:... 截止时间:...
**待跟进事项**(需要进一步讨论或确认的):
- [负责人] 事项:... 截止时间:...
**关键信息点**(讨论中出现的重要判断/数据/背景):
- ...
**下次会议建议议题**(如有):
- ...
会议记录:
{meeting_transcript}工具5:技术选型分析
场景:需要在几个技术方案中做选择,想让AI帮你系统梳理。
我需要在以下几个方案中做技术选型:
方案列表:{options}
我的场景约束:
- 团队规模:{team_size}
- 技术栈:{tech_stack}
- 时间约束:{timeline}
- 预算约束:{budget}
- 关键需求:{key_requirements}
请从以下维度进行分析:
1. 技术成熟度和社区活跃度
2. 与现有技术栈的契合度
3. 学习曲线和上手难度
4. 维护成本(长期)
5. 场景适配度(针对我的关键需求)
输出:
- 每个方案的评分矩阵(维度×方案,1-5分)
- 我的场景下的推荐方案及详细理由
- 使用该方案最需要注意的1-2个风险点如何在实际工作中养成用模板的习惯
有了这些模板,下一个问题是:怎么让自己真的用起来,而不是收藏了就再也不开?
方法一:工作流绑定
把最常用的Prompt模板嵌入你的工作工具。例如:
- 在你的笔记软件里(Notion/飞书文档/Obsidian)创建一个"AI Prompt快捷键"页面
- 在浏览器收藏夹里建一个专门的Prompt文件夹
- 如果你的团队用CLI工具,写一个简单的shell函数
prompt-review()直接输出评审模板
方法二:即用即改
不要追求"一个完美的Prompt永远适用"。每次使用后,花60秒记录:哪里需要改、哪里特别好用。下次用时从上次的改良版本开始。这个"持续小迭代"的习惯比"一次写出完美模板"的完美主义更有效。
方法三:每次用完后评估ROI
用一个Prompt完成任务后,快速估算:我花了多少时间写Prompt + 修改输出?如果没有AI我要花多久?这个比值就是这次使用的ROI。当你开始追踪这个数字,你会发现某些类任务AI帮助巨大(文档处理、格式转换、草稿生成),某些类任务AI反而拖慢了你(需要大量背景知识的判断性任务)。这个感知会帮你更精准地选择何时用AI、何时自己做。
给团队建立Prompt文化的三步路
最后讲一个组织视角的话题——如何让Prompt工程不只是你一个人的技能,而是成为团队的集体能力。
第一步:自己先做标杆。在你的工作输出里展示Prompt工程的效果——开会带着用Prompt生成的结构化会议记录;做方案时带着用Prompt做的风险评估;写报告时说明"这份竞品分析是我用AI在1小时内完成的初稿"。用结果说话,比任何培训都有说服力。
第二步:低门槛分享。不要让Prompt分享变成一件正式的事。在日常工作协同(企业微信/飞书群)里,遇到好用的Prompt直接发出去,说明用途和效果。不用写教程,一个截图+"这是我用来做XX的Prompt"就够了。当分享变得轻松,积累就自然发生了。
第三步:让资产库成为工作入口。当有新人入职,给他们指向Prompt资产库,而不是让他们自己摸索。当有新项目启动,先在资产库里找相关Prompt,而不是从头写。把资产库嵌入工作流程,而不是让它停留在"有空去看看"的状态。
建立Prompt文化是一个3-6个月的事情,不是一次性的部署。但当它真正运转起来,团队的AI使用效率会有一个质变——从"几个人会用AI"到"整个团队用AI做事"。
6.6 工程化的最后一步:建立Prompt资产库
前面讲了单个Prompt的写法。这一节讲一个团队视角的话题:当你有了很多有效的Prompt,如何管理它们,让整个团队都能受益?
为什么需要Prompt资产库
很多团队的现状是这样的:A同学摸索出一个很好用的代码Review Prompt,在飞书群里分享了一次,然后就沉底了。B同学不知道这个,又自己摸索了两周。下次有新同学加入,这个过程再来一遍。
Prompt是团队的知识资产,但大多数团队把它当消耗品用。 建立一个简单的Prompt资产库,可以让整个团队的AI使用效率倍增。
而且还有一个更现实的价值:对产品架构师来说,Prompt资产库是你向业务方展示AI工作价值的最直观方式。当你能说"我们已经积累了XX个高效Prompt,覆盖了YY类业务场景,帮助团队节省了ZZ小时/月"——这比任何抽象的汇报都有说服力。
一个轻量级的Prompt资产管理方案
不需要复杂的工具,一个Notion/飞书文档就够:
# Prompt资产库 v1.0
## 场景分类
- 文档处理类
- 代码辅助类
- 分析决策类
- 写作生成类
---
## 代码Review助手
**版本**:v1.3
**最后更新**:2026-05-10
**使用频率**:每周约20次
**Prompt**:
[完整Prompt内容]
**效果说明**:
- 适用场景:Java/Python后端代码Review,侧重安全和性能
- 不适用:前端CSS/HTML样式相关
**已知局限**:
- 对超过500行的文件效果会下降,建议拆分
- 不会检查业务逻辑正确性,只关注代码质量
**贡献者**:@张三产品架构师的判断:这个资产库的维护成本不应该超过使用收益。一个简单的标准:如果一个Prompt被用了超过5次,值得录入;如果录入后超过3个月没人用,可以归档。
Prompt资产库的评估指标
建立了资产库之后,怎么衡量它的价值?我用过三个指标:
1. 人均AI使用频率:团队每人每天使用AI工具的次数,反映资产库的普及效果。没有资产库的团队,AI使用通常集中在少数几个"自己摸索出来"的人。资产库建好之后,这个频率应该全团队均衡提升。
2. 任务完成一次通过率:第一次发出Prompt就得到可用输出的比率。有资产库时可以直接复用高质量Prompt,通过率显著高于"每次重新写"。
3. Prompt迭代速度:一个新任务类型从"第一次尝试"到"有稳定高效Prompt"需要多少轮迭代。有了资产库里的类似Prompt作为起点,新场景的探索速度会快很多——因为你不是从零开始,而是在成功案例上改进。
量化这些指标的简单方式:在资产库里每个Prompt增加一个使用记录字段,记录"用了多少次、成功率如何"。一个季度后你就有数据了。
从Prompt到AI工作流
当你把多个Prompt连接起来,就从"单次调用"升级到了"AI工作流":
阶段1:提取要点
[Meeting Transcript Prompt] → 结构化会议纪要
阶段2:生成行动项
[Action Items Prompt] → 分配到各负责人的待办
阶段3:发送通知
[Notification Draft Prompt] → 邮件/消息草稿
阶段4(可选):更新系统
[Jira/TAPD Ticket Prompt] → 自动创建任务工单这已经是Agent的雏形了——下一章我们会深入讲这个话题。
本章小结
-
Prompt的本质是精确的需求说明书——角色+背景+任务+输出格式,这和写PRD是同一套思维。"随便问"效果差的根本原因是信息不完整,不是模型不好。
-
五种基础模式覆盖80%场景——角色设定、Few-shot示例、Chain-of-Thought、结构化输出、System Prompt。每种有固定的适用场景和使用技巧,不是每个场景都要全用。
-
Prompt工程化是AI产品的基础设施——模板化把Prompt从一次性消耗品变成可复用资产;版本管理让Prompt变更可追溯可回滚;AB测试让效果优化有数据支撑;实时监控让质量漂移可被及时发现。
-
失败有规律可循——六类主要失败模式(任务模糊/背景不足/示例质量差/指令冲突/超出能力边界/数据质量问题),每类有对应的诊断方法和修法。遇到效果瓶颈先排查是哪类问题,不要在错误维度上过度优化。
-
产品架构师的Prompt工具箱——方案评审、竞品分析、文档生成、会议纪要、技术选型五类模板,可以直接复用并在使用中持续改进。建立团队Prompt资产库是让这些工具真正发挥团队价值的关键步骤。
掌握了Prompt工程,你已经能精确地"指挥"AI。但一个真正有用的AI产品还面临另一个核心挑战:模型的知识来自训练数据,它不了解你的业务、你的文档、你的客户历史。下一章要讲的RAG,就是解决这个问题的答案——让AI在回答问题时,能实时检索和利用你的私有知识,而不只是靠它"记住"的那些训练数据。
附:Prompt跨模型迁移的注意事项
最后说一个很多人会遇到但不常被讨论的实际问题:你在GPT-4o上调好了一个效果很好的Prompt,切换到Claude或DeepSeek之后效果变差了——这是怎么回事?
根本原因:不同模型有不同的"训练偏好",同样的Prompt在不同模型上激活的行为模式不同。
常见的差异:
1. 指令遵从敏感度不同
Claude对指令遵从度非常高——你说"只输出JSON,不要有任何其他文字",它会严格遵守。GPT系列在某些情况下会在JSON前后加一些解释性文字(即使你没有要求)。如果你从Claude迁移到GPT,可能需要在格式约束上更明确地说"不要输出JSON之外的任何内容"。
2. 输出风格偏好不同
Claude倾向于更结构化、更有层次感的输出;GPT系列在创意写作方面更自然;DeepSeek的中文输出更本土化。如果你对风格有要求,迁移时需要明确描述期望风格,而不是假设两个模型会有一样的默认输出风格。
3. 安全过滤的宽严不同
不同模型对"敏感内容"的边界定义不同。Claude整体偏谨慎,某些正常商业问题可能触发拒答;GPT的边界相对宽松一些;国产模型对中文内容的合规敏感度更高。这会导致同一个Prompt在不同模型上的拒答率差异显著。
4. 上下文理解方式不同
超长上下文时,不同模型的"注意力"分布不同。Claude在200K token的上下文里保持较高的信息利用率;某些模型在超过其优化窗口后,对长上下文的末尾部分注意力会明显下降(Lost in the Middle问题)。
迁移建议:
- 不要直接复制粘贴Prompt就期望效果一样好
- 准备一个固定的测试集(30-50条)用于快速验证迁移效果
- 主要调整方向:输出格式约束的精确度、拒答边界的处理、风格描述的明确程度
- 对于关键生产Prompt,做一次专项的"迁移测试"而不是"上线后再说"
这一点在你做第5章的"保持模型可替换"原则时尤其重要——保持可替换不只是架构层面的标准接口,还需要Prompt层面的适配工作。切换模型不是"换一行代码"就搞定,是需要一次Prompt适配的工程工作。
一个完整的Prompt生命周期
综合以上内容,一个在产品中运行的Prompt,有完整的生命周期值得追踪:
- 设计阶段:写第一版Prompt,根据任务明确四要素,选择合适的模式
- 测试阶段:用测试集验证效果,计算准确率和格式合规率
- 上线阶段:版本化存储,走代码上线流程,配置监控
- 运营阶段:持续观察指标,收集真实失败案例
- 迭代阶段:基于运营数据优化,走AB测试,用数据决策
- 退役阶段:如果业务场景消失或被更好的方案替代,归档
大多数团队只经历了阶段1(随便写),有些团队到了阶段2(跑了些测试),能做到阶段3-6的很少。而这正是AI产品"做了很多,但感觉不稳定"和"每次上线都很有把握"之间的差距所在。
把Prompt当成一类工程资产来管理,是从"个人AI技巧"到"团队AI能力"的必经之路。
延伸阅读
- OpenAI Prompt Engineering Guide(https://platform.openai.com/docs/guides/prompt-engineering)—— 官方的Prompt工程指南,简洁实用,是所有Prompt初学者的必读
- Anthropic Claude Prompt Library(https://docs.anthropic.com/en/prompt-library)—— 大量真实场景的Prompt案例,按任务类型分类,可以直接借鉴
- Lilian Weng,《Prompt Engineering》(blog.lilianweng.github.io)—— 技术深度最好的综述文章,兼顾原理和实践,强烈推荐
- Brex,《Prompt Engineering Guide》(https://github.com/brexhq/prompt-engineering)—— 企业级Prompt工程规范,有大量真实业务场景的Prompt模板,对产品架构师特别有参考价值