学习笔记-AIGC全栈认知与落地(3)
第3章 · 算力基础设施与训练平台
开场:当业务方说"我们要训自己的模型"
我参加过不少立项会。有一类问题特别容易出现:
"竞对都在搞大模型了,我们能不能也训一个自己的行业大模型?"
这个问题的正确回答不是"能"或"不能"——而是一连串反问:
- 你希望达到什么效果?
- 你愿意投入多少钱?是百万级还是千万级?
- 你有多少高质量的行业数据?
- 你愿意等多久?三个月还是一年?
- 你确定不能通过Prompt优化 + RAG先试试?
要回答这些反问,你需要对训练这件事有"量感"。这一章就是帮你建立这个量感的。
我第一次听到"张量并行"这个词时完全懵了。但后来我发现,理解训练不需要你会写训练代码——你只需要理解这条流水线的每个工位在干嘛、每个工位要花多少钱。
想象一座工厂:GPU是机器,数据是原料,训练算法是工艺流程。这一章,我们参观这座工厂。
3.1 算力层:为什么GPU是AI的"石油"
CPU vs GPU:一个博士和一万个小学生
为什么训练AI非得用GPU?这要从CPU和GPU的根本区别说起。
CPU(中央处理器):少量但强大的核心(通常4-128个),每个核心擅长处理复杂的逻辑、分支判断、串行任务。像一个博士,一次只解一道难题,但能解很难的题。
GPU(图形处理器):海量但简单的核心(数千到上万个),每个核心只能做简单运算(加法、乘法),但能同时做成千上万个。像一万个小学生,每人只会算加法,但一万人同时算,总速度惊人。
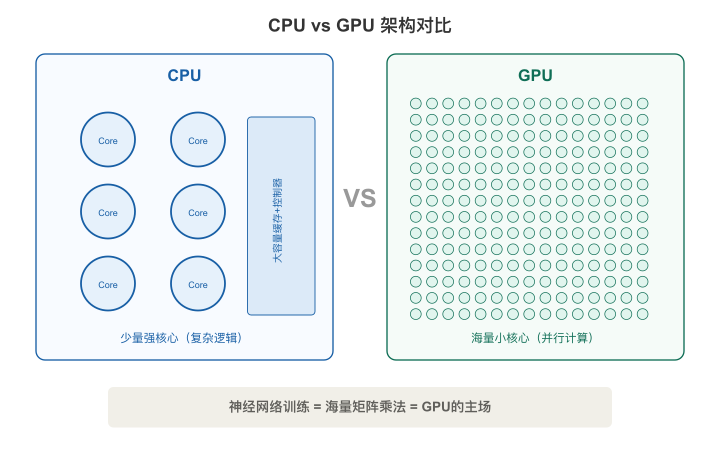
【图3-1:CPU vs GPU架构对比】
而神经网络训练的核心运算是什么?矩阵乘法。大量的、重复的、可以并行的矩阵乘法。
这正是GPU的主场。一块顶级GPU做矩阵乘法的速度可以是CPU的100-1000倍。这就是为什么AI训练非GPU不可。
GPU的三个关键指标
作为产品架构师,你不需要背诵GPU的参数表。但你需要知道三个指标,因为它们直接关联到你的产品决策:

【图3-2:GPU关键指标与模型需求对照】
| 指标 | 含义 | 直觉 | 产品影响 |
|---|---|---|---|
| 显存(VRAM) | GPU的"内存大小" | 决定模型"能不能装得下" | 模型越大→需要越多显存→需要越多卡 |
| 算力(TFLOPS) | 每秒能做多少万亿次浮点运算 | 决定训练/推理"有多快" | 算力越强→训练越快→出结果越早 |
| 显存带宽(TB/s) | 数据在显存和计算单元之间搬运的速度 | 决定数据"搬得快不快" | 推理时的真正瓶颈(计算快但数据跟不上) |
一个形象的比喻:
- 显存 = 你的工作桌面有多大(能同时摊开多少资料)
- 算力 = 你的大脑转得多快
- 带宽 = 你从书架上拿书到桌面的速度
GPU代际:从A100到B200
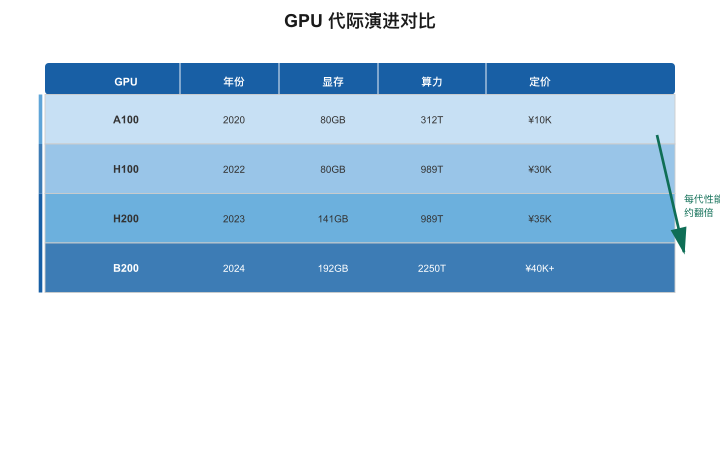
【图3-3:GPU代际演进对比】
| GPU型号 | 发布年份 | 显存 | FP16算力 | 大概单价 | 一句话定位 |
|---|---|---|---|---|---|
| A100 | 2020 | 40/80GB | 312 TFLOPS | ~$10,000 | 当前存量最大的训练卡 |
| H100 | 2022 | 80GB | 989 TFLOPS | ~$30,000 | 当前主力训练卡 |
| H200 | 2023 | 141GB | 989 TFLOPS | ~$35,000 | H100+更大显存 |
| B200 | 2024 | 192GB | 2250 TFLOPS | ~$40,000+ | 下一代旗舰 |
每一代的核心提升:算力翻倍、显存增长50-100%。但价格也在涨,而且经常缺货——这就是为什么"GPU算力"被称为AI时代的"石油"。
产品架构师的量感:
- 一块H100的80GB显存,能跑一个7B模型的推理(刚好装得下)
- 要训练一个70B模型,至少需要一台8卡H100服务器
- Meta训练Llama 3 405B用了16384块H100——普通公司连零头都凑不齐
多卡协同:NVLink与InfiniBand
当一块卡不够用时,多块GPU需要协同工作。但GPU之间需要频繁交换数据——这对网络带宽提出了极高要求。
| 互联技术 | 场景 | 带宽 | 类比 |
|---|---|---|---|
| NVLink | 同一台服务器内的GPU之间 | 900 GB/s | 同一栋楼里的内部电梯 |
| InfiniBand/RDMA | 不同服务器之间 | 200-400 Gb/s | 楼与楼之间的高速天桥 |
| 普通以太网 | 一般数据中心 | 25-100 Gb/s | 普通马路 |
AI集群的网络成本可能占整个集群成本的30-40%。这是很多人低估的一点——以为买够GPU就行了,结果发现网络才是瓶颈。
产品架构师的踩坑提醒:这也是私有化部署最常见的预算翻车点。算GPU成本的时候只算了裸卡价格,没有算网络交换机、光模块、线缆的钱——这几项加起来可以再买一轮GPU。如果你在做私有化的预算,记得把网络成本按GPU总价的30%往上加。
3.2 训练的本质:让模型"读书学习"
好,有了"机器"(GPU),下一个问题是:"这条生产线上到底在做什么?"
训练的核心循环
大模型训练的核心循环极其简单(概念上):
重复几百亿次:
1. 读一段文本
2. 遮住最后一个词,让模型猜
3. 猜对了 → 参数不动
4. 猜错了 → 调整参数,让下次猜得更准就这么一个循环,重复几百亿次。当数据足够多、模型足够大、迭代足够久——模型就"学会"了语言和知识。
三阶段进化:从"书呆子"到"好员工"
但只靠这个循环训出来的模型,像一个读遍图书馆但不懂社交的书呆子。要让它变成一个"好员工",需要三个阶段的"教育":
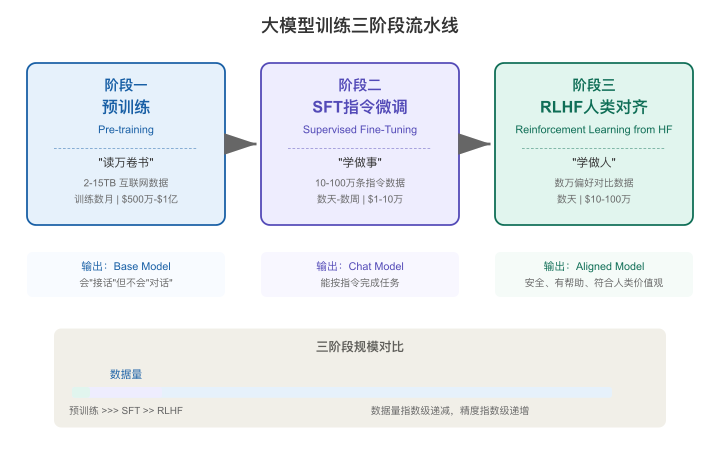
【图3-4:大模型训练三阶段流水线】
阶段一:预训练(Pre-training)——读万卷书
做什么:让模型阅读人类写过的几乎所有公开文本——书籍、网页、论文、代码、新闻、百科……总数据量通常在几TB到几十TB。
目标:获得语言能力和世界知识。模型学会了"文字是怎么组织的""世界是怎么运转的"。
类比:一个学生从幼儿园到博士,把图书馆的书全读了一遍。他什么都知道一点,但你问他问题,他可能不知道该怎么"好好回答"——他只会继续"往下写"。
规模感:
- 数据量:2-15 TB文本
- GPU需求:数百到数千块H100
- 训练时间:几周到几个月
- 成本:$500万-$1亿(取决于模型大小)
阶段二:SFT指令微调(Supervised Fine-Tuning)——学做事
做什么:给模型大量"高质量的问答对"作为标准答案,让它学习"用户问了什么→应该怎么回答"。
目标:从"会写文章但不会对话"变成"能听懂指令并结构化回答"。
类比:书呆子开始实习了。带教老师给他看各种工作范例:"客户问这种问题时,你应该这样回答""需求文档应该这样写"。看了几万个范例后,他知道怎么"像个正常人一样做事"了。
SFT数据示例:
指令:帮我把这段技术文档总结成3条要点
输入:(一段500字的技术文档)
输出:
1. 要点一:...
2. 要点二:...
3. 要点三:...规模感:
- 数据量:10万-100万条高质量指令对
- GPU需求:数十块(基于已预训练好的模型继续训练)
- 训练时间:数天到数周
- 成本:$1万-$10万
阶段三:RLHF人类反馈对齐——学做人
做什么:让模型对同一问题生成多个回答→让人类标注员评判哪个更好→用这些偏好数据训练模型,让它学会"什么样的回答让人满意"。
目标:不只是"能回答",而是"回答得好"——有帮助、安全、诚实、符合人类期望。
类比:从实习生转正了。但好员工不只是完成任务,还要懂"怎么做事让人舒服"——说话语气对不对、分寸把握好不好、该说的说不该说的不说。
为什么这一步如此关键:第1章讲过,GPT-3.5相比GPT-3的核心突破就是RLHF。技术能力差不多,但"产品可用性"天壤之别。
规模感:
- 数据量:数万条人类偏好对比数据
- GPU需求:数十块
- 人工成本:大量人类标注员(这才是真正贵的部分)
- 训练时间:数天
- 总成本:$10万-$100万(人工标注费用占大头)
三阶段总览
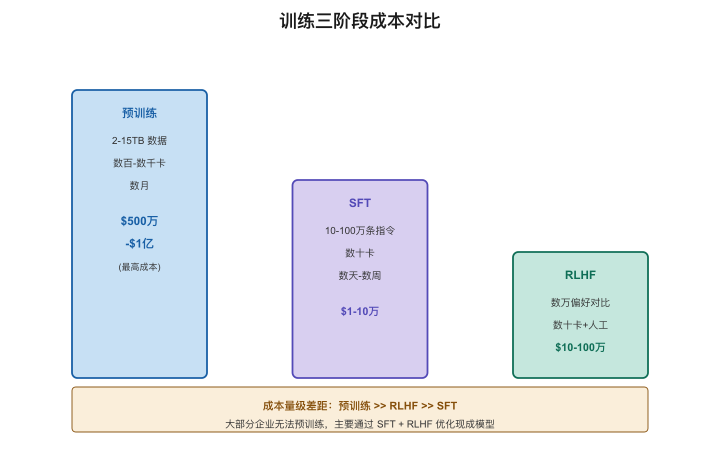
【图3-5:三阶段成本/数据/时间对比】
| 阶段 | 目标 | 数据 | GPU规模 | 时间 | 成本量级 | 类比 |
|---|---|---|---|---|---|---|
| 预训练 | 语言能力+知识 | 2-15TB文本 | 数百-数千卡 | 数月 | $500万-$1亿 | 读完图书馆 |
| SFT | 听话做事 | 10-100万条指令 | 数十卡 | 数天-数周 | $1-10万 | 带教实习 |
| RLHF | 做事让人满意 | 数万偏好对比 | 数十卡 | 数天 | $10-100万 | 学会做人 |
数据:真正的护城河
一个容易被低估的事实:顶级模型之间的差异,架构差异只占20%,数据差异占80%。
- 预训练数据的质量(有没有清洗、去重、去毒性)
- SFT数据的质量(问答对是不是真的好)
- RLHF标注的质量(标注员水平高不高)
这就是为什么OpenAI、Anthropic花大量精力在数据工程上——数据是模型真正的壁垒。
产品架构师的判断:当你评估一个模型时,问"这个模型的训练数据是什么样的"比问"这个模型是什么架构"更有意义。但数据配比和清洗策略通常不公开——这是各家的核心机密。所以当厂商跟你说"我们模型参数最多"时,别被带偏——参数多不代表好,数据好才代表好。判断一个模型真实水平的最可靠方法不是看PR稿,是在自己的场景下用真实数据评测(第5章会详细展开评测方法)。
3.3 分布式训练:一块卡装不下一个大模型怎么办
到这里你已经知道了:一个大模型可能有70B甚至405B参数,需要几百GB到几TB的显存。而一块最好的GPU也只有80-192GB。
怎么办?答案是分布式训练——把训练任务拆开,分给几百甚至几千块GPU协同完成。
三种并行策略
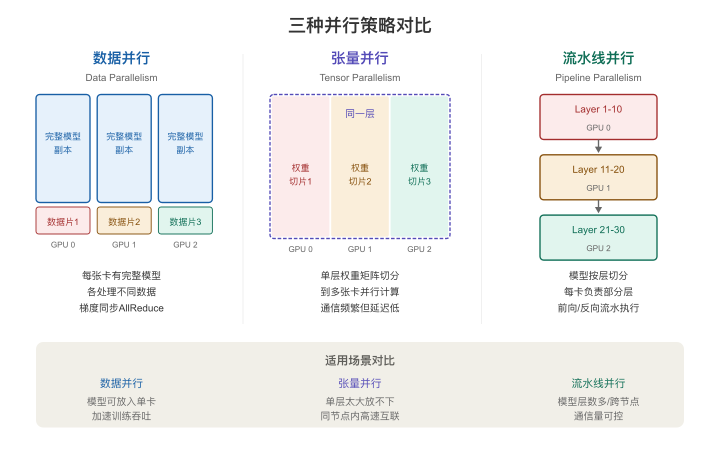
【图3-6:三种并行策略对比示意】
策略一:数据并行(Data Parallelism)
原理:每块GPU持有一份完整的模型副本,但各自看不同的训练数据。大家各自算完后,"对一下答案"同步参数更新。
类比:10个人各自读不同章节的同一本书,然后聚在一起交流笔记,更新各自的理解。
GPU 0: 模型完整副本 + 数据批次A → 计算梯度A
GPU 1: 模型完整副本 + 数据批次B → 计算梯度B
GPU 2: 模型完整副本 + 数据批次C → 计算梯度C
...
→ 所有GPU同步梯度,更新参数 → 进入下一轮优点:实现简单,横向扩展容易
限制:模型必须装进单块卡的显存——大模型不行
策略二:张量并行(Tensor Parallelism)
原理:把模型每一层的矩阵运算切成多份,分给不同GPU各算一块,再把结果拼起来。
类比:一张超大的Excel表格,你把它按列切开,每个人算自己那几列,最后把结果拼回去。
一个矩阵乘法 W×X:
GPU 0: W的左半部分 × X → 部分结果
GPU 1: W的右半部分 × X → 部分结果
→ 合并得到完整结果优点:能处理单块卡装不下的大模型
限制:GPU之间每一步都要通信(需要NVLink级别的高带宽)——通常只在同一台机器内使用
坦诚时刻:我第一次听到"张量并行"时完全懵了。算法同事在评审会上说"我们用的是TP=4",我当时脑子里想的是——TP是什么?4又是什么意思?后来我画了一张图才搞明白:它就是"把一个大矩阵切成4块,4块GPU各自算自己那份,算完再合起来"。名字唬人,原理朴素。
但这个"朴素"是有代价的——切得越细(TP数值越大),GPU之间每一步都要通信、交换计算结果。这就像四个人共同算一道题,每算一步都要把中间结果传给别人——人越多传的数据越多,通信开销就越可能拖慢整体。所以TP通常限制在同一台服务器内(NVLink带宽能支撑),不会跨机器用。产品架构师不需要选TP=几,但要知道:当算法团队说"TP=8"的时候,意味着这8块卡必须在同一台机器上,而且每块卡拿不出自己全部显存给模型——因为它们要频繁通信。
策略三:流水线并行(Pipeline Parallelism)
原理:把模型的不同层放到不同GPU上,数据像流水线一样依次经过每一层。
类比:一条汽车装配流水线——底盘在第一站装,车身在第二站装,内饰在第三站装。每个工人只负责自己那一道工序。
GPU 0: 模型第1-10层
GPU 1: 模型第11-20层
GPU 2: 模型第21-30层
...
数据从GPU 0 → 1 → 2 → ... 依次流过优点:跨机器时通信压力小(只需要传递层间的中间结果)
限制:存在"流水线气泡"——下游GPU在等上游处理时是空闲的
混合并行:实战中三种策略同时用
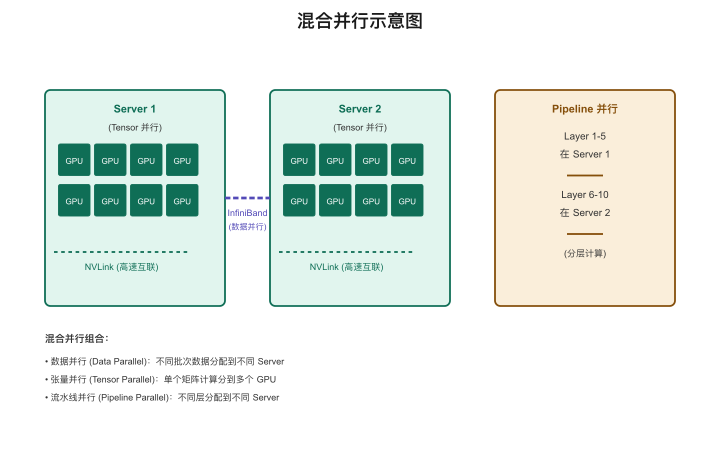
【图3-7:混合并行示意图】
真实的大规模训练中,三种策略是同时使用的:
- 一台8卡服务器内部:张量并行(NVLink带宽够)
- 多台服务器之间:流水线并行(跨机通信量小)
- 整个集群层面:数据并行(每组看不同数据)
例如Llama 3 405B的训练:
- 16384块H100
- 2048台8卡服务器
- 混合三种并行策略
- 训练约2-3个月
通信开销:并行的代价
并行不是免费的。GPU之间需要频繁"对答案"——通信量越大、通信越慢,训练效率越低。
这就是为什么:
- AI集群的网络建设成本占总成本30-40%
- NVLink和InfiniBand是训练集群的"硬通货"
- GPU数量翻倍,训练速度不会翻倍(因为通信开销也在增长)
产品架构师的陷阱提醒:这也是你最容易在立项会上纠正的一个误区——"GPU加一倍,训练时间减一半"。事实是,并行度越高,效率越差(通信开销吃掉越来越多的算力)。从1卡到1000卡的效率可能是90%,从1000卡到10000卡可能只有70%。花2倍的钱,不一定得到2倍的速度。在评估"加卡能提速多少"时,永远要问一句:通信开销占了多少?
3.4 训练平台:总调度室
有了几千块GPU、有了训练算法、有了数据——你需要一个"总调度室"来管理这一切。这就是训练平台的角色。
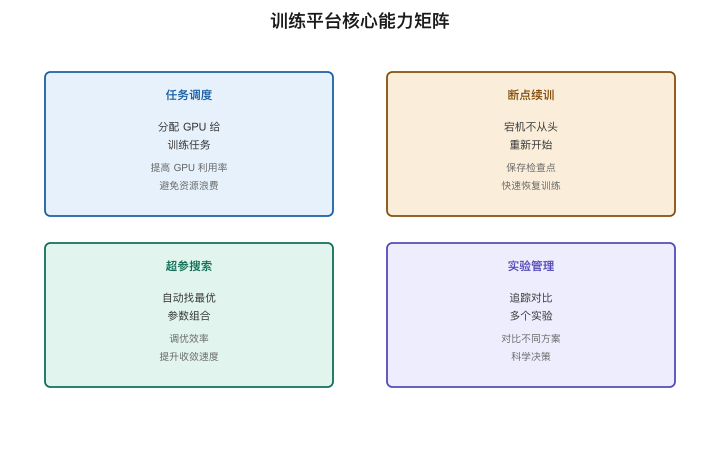
【图3-8:训练平台核心能力矩阵】
| 能力 | 做什么 | 为什么重要 |
|---|---|---|
| 任务调度 | 把训练任务分配到正确的GPU上 | 几千块卡的分配不能靠手动 |
| 断点续训 | 每隔N步保存一次状态(Checkpoint) | 训练几天突然宕机不用从头来 |
| 超参搜索 | 自动尝试不同的学习率、batch size等 | 找到最优参数组合 |
| 实验管理 | 同时跑多个实验,追踪loss曲线、对比效果 | 几十个实验不会搞混 |
| 监控告警 | GPU利用率、温度、loss异常检测 | 及时发现和处理故障 |
| 数据管线 | 数据清洗、tokenization、加载优化 | 让GPU不会"饿着"(等数据) |
真实经验
我和训练平台团队协作时发现,产品架构师和算法工程师关心的问题完全不同:
| 算法工程师关心的 | 产品架构师关心的 |
|---|---|
| 哪种并行策略最优 | 什么时候能训完 |
| loss能不能继续降 | 效果够不够用 |
| 要不要调学习率 | 还要不要加投入 |
| 梯度累积几步 | 上线能不能达标 |
产品架构师和训练团队协作的核心是:把技术语言翻译成业务语言——"loss从0.8降到0.6"意味着什么?"训练100步"需要多久?"加倍GPU"能不能让时间减半?
一个真实的故障场景:大模型训练跑了两周,某天深夜某个GPU节点宕了。如果没有Checkpoint(断点续训),两周的算力成本直接打水漂——几十万人民币没了。有了Checkpoint,恢复上一个保存点,损失的可能只是几小时的算力。这也是为什么训练平台里"断点续训"看似不起眼但实际最救命——它就像你写文档的Ctrl+S,只不过每次保存的不是几MB的Word文件,而是几百GB的模型状态。
3.5 训练的成本感知:产品架构师的"量感"
这是本章最实用的一节。我要帮你建立一个"量感"——不需要精确计算,但当别人提到"训一个模型"时,你能迅速在脑中估算出量级。
成本量级对照表
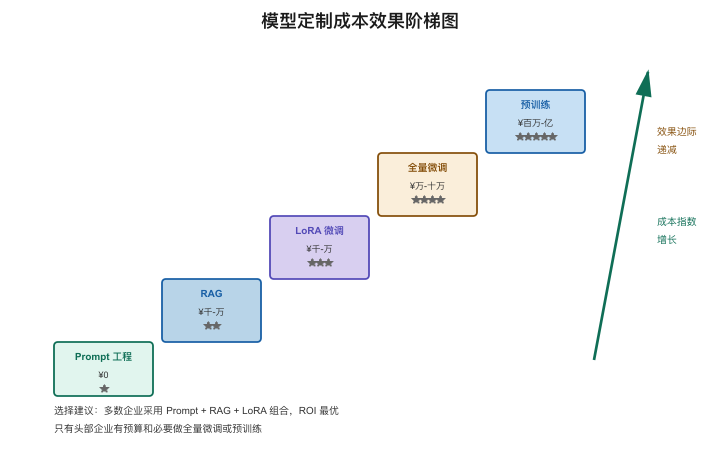
【图3-9:模型定制方式的成本-效果阶梯图】
| 定制方式 | 成本量级 | 时间 | 效果增益 | 适用场景 |
|---|---|---|---|---|
| Prompt Engineering | ¥0(人工时间) | 小时级 | ★★☆☆☆ | 通用场景,能跑就行 |
| RAG(外挂知识库) | ¥数千-数万 | 天级 | ★★★☆☆ | 需要私有知识 |
| LoRA微调 | ¥数千-数万 | 天级 | ★★★★☆ | 需要特定风格/格式 |
| 全量微调 | ¥数万-数十万 | 周级 | ★★★★☆ | 需要深度行业适配 |
| 从头预训练 | ¥数百万-数亿 | 月级 | ★★★★★ | 头部公司抢占底座 |
黄金法则:从左到右尝试,效果够用就停——不要为了用"高端方式"而用。
决策框架:自研 vs 开源 vs API
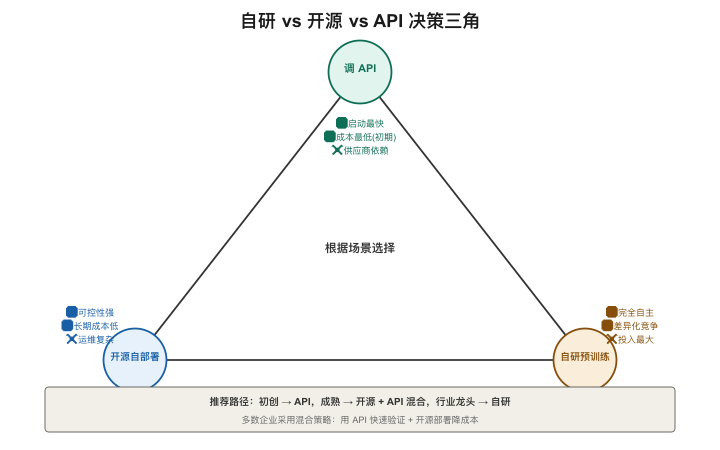
【图3-10:自研vs开源vsAPI三角决策】
| 维度 | 调API | 用开源模型 | 自研训练 |
|---|---|---|---|
| 启动成本 | ¥0 | 买/租GPU | 数百万-数亿 |
| 运行成本 | 按token持续付费 | GPU运维 | GPU+人才+运维 |
| 控制力 | 低(受限于厂商) | 中(可微调/部署) | 高(完全自主) |
| 上线速度 | 天 | 周 | 月-年 |
| 适合谁 | 快速验证/中小团队 | 有GPU资源/需定制 | 头部大厂/核心竞争力 |
产品架构师的判断原则:
- 先问"用现有模型+Prompt/RAG能不能解决?"——90%的场景可以
- 如果不行,再问"LoRA微调够不够?"——大部分行业适配需求LoRA就够了
- 只有确认前两步都不够,才考虑全量微调或自研——这是一个几十万到几亿的决策
- 从头预训练是极少数头部公司才需要做的事——除非你的目标是做通用底座模型
私有化部署的隐性成本
很多公司说"我们要私有化部署"——通常低估了真实成本:
| 显性成本 | 隐性成本 |
|---|---|
| GPU服务器采购 | GPU运维工程师(年薪50-100万/人) |
| 网络设备 | 机房电费(一台8卡服务器月电费数千元) |
| 存储设备 | 散热空调费用 |
| 驱动/框架升级维护 | |
| 故障处理和备份恢复 |
粗略估算:私有化部署一台8卡H100服务器的年总拥有成本约300-500万元(含硬件折旧+运维+人力)。
如果你的AI产品每年调API的费用远低于这个数——那私有化在经济上不划算。
还有一个极易踩的坑:很多团队在做私有化决策时只算了"买GPU的钱",没算"GPU闲置的钱"。私有化部署的GPU不会100%满载——流量有波峰波谷,GPU波谷时也在耗电和折旧。实际利用率通常在40-60%。如果你的业务有明显的高低峰(比如白天用职场AI,晚上几乎没人用),API按量付费的模式天然帮你承担了波谷成本,私有化则要自己吃下全部闲置损失。算私有化TCO的时候,GPU按60%利用率折算是比较诚实的做法。
本章小结
-
GPU是AI的"石油"——显存决定模型能不能跑,算力决定多快,带宽在推理时是瓶颈。每代GPU性能翻倍,但价格也在涨。
-
大模型训练 = 三阶段教育——预训练(读书获得能力)→ SFT(学做事)→ RLHF(学做人满意的事)。成本从数百万到数千万。
-
分布式训练用三种并行策略——数据并行(切数据)、张量并行(切矩阵)、流水线并行(切层)。实际训练中三种同时用。
-
训练平台是总调度室——调度、续训、超参搜索、实验管理、监控。产品架构师要能把"loss下降"翻译成"效果是否达标"。
-
产品架构师的黄金法则:能不训就不训——从Prompt → RAG → LoRA → 全量微调 → 预训练,是一条成本指数增长的阶梯。效果够用就停。
训练解决了"从0到1"的问题——把模型造出来。下一章,我们进入"从1到N"——模型训完之后怎么变成一个能稳定服务千万用户的系统?这中间有延迟、吞吐、成本的"不可能三角",也有过去两年最密集的推理优化技术突破。如果你做AI产品的日常工作里最头疼的是"怎么让AI回答快一点、便宜一点",下一章就是你的弹药库。
延伸阅读
- NVIDIA GPU架构白皮书(Hopper/Blackwell)—— 了解GPU代际差异的官方来源
- Andrej Karpathy,《Let's build GPT from scratch》—— 从零手写一个mini-GPT的教程,直观理解训练过程
- 《Scaling Laws for Neural Language Models》(Kaplan et al., 2020)—— 理解"模型越大效果越好"的数学规律