学习笔记-AIGC全栈认知与落地(2)
第2章 · 对话即接口的全新架构
开场:3秒背后的故事
上午开完一个两小时的技术评审会,你拿到了同事整理的50页会议纪要。你不想全部看完,于是打开AI助手,输入了一句话:
"帮我总结今天上午的技术评审会议重点,分条列出待办事项。"
3秒后,一段结构清晰的摘要出现在你面前。5个重点结论,3条待办,甚至还按优先级排了序。
好,停一下。
这3秒里到底发生了什么?
从你按下回车的那一刻起,你的文字经过了哪些环节、被哪些系统处理、在哪些硬件上运算、经过了什么管道——最终才变成了那段摘要?
上一章我们搞清了大模型"是什么"和"凭什么能"。这一章,我们把它跑起来的完整链路拆开看。看完这一章,你再遇到AI系统的任何问题——"为什么慢""为什么贵""为什么答错了"——都能迅速判断:问题出在哪个环节。
我第一次看到这条链路的完整拆解图时,第一反应是:这也太复杂了。一个简单的问答,背后居然有8个独立环节、每个环节都可能出问题?后来我才发现,理解这8个环节是做AI产品架构最重要的"元能力"——因为它给了你一张归因地图。出了问题,不用靠猜,能精确定位到是哪一层的问题。
2.1 一次对话的完整生命周期
表面上看,一次AI对话就是三步:用户说话→模型想→模型回答。
实际上,中间至少经过8个独立环节。每个环节都有自己的技术方案、性能瓶颈、和产品影响。
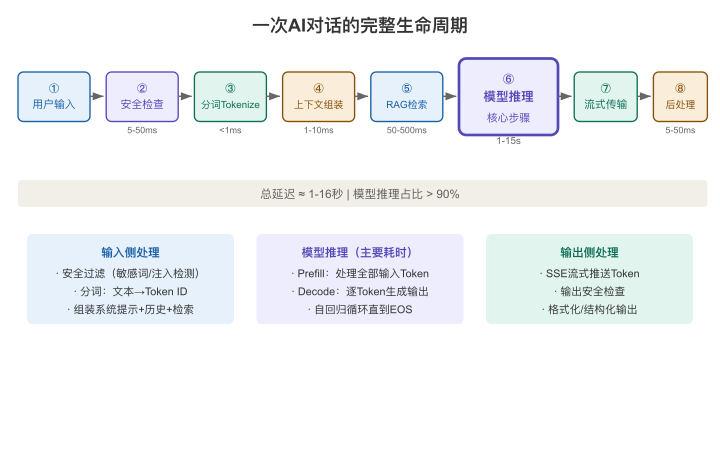
【图2-1:一次AI对话的完整生命周期】
让我们按时间顺序走一遍:
环节1:用户输入
用户打完字,点击发送。这一步看似简单,但在产品层面已经有设计决策了:
- 是等用户打完才发送,还是支持"流式输入"?
- 要不要做客户端的初步校验(比如过滤空白消息、限制长度)?
耗时:~0ms(网络传输忽略不计)
出问题时的表现:用户误触发送了空消息;或者超长输入直接打爆下游的token限制——而客户端没有预先拦截,导致用户等了几秒后才看到报错。
环节2:预处理与安全检查
用户的输入到达服务端后,第一件事不是直接扔给模型——而是安全检查。
这一步做什么:
- 敏感词/违规内容过滤(涉政、涉黄、涉暴等)
- Prompt注入攻击检测(用户是不是试图"越狱")
- 用户身份鉴权和配额检查
耗时:5-50ms
出问题时的表现:拦截了不该拦的正常内容(误杀,用户说"这个方案有风险"被拦);或没拦住越狱攻击(漏过,导致模型输出违规内容)。
环节3:Tokenization(分词)
大模型不认识"文字"。它的世界里只有数字。所以用户输入的文字需要被切割成一个个token(后面2.2节展开讲),然后每个token映射为一个数字ID。
"帮我总结会议重点" → [帮][我][总结][会议][重点] → [8834, 2195, 39482, 17653, 28901]耗时:<1ms
为什么重要:token的数量直接决定了成本(按token收费)和能不能装进上下文窗口。
出问题时的表现:这一步几乎不会出错,但如果用了错误的分词器版本(不同模型用不同tokenizer),token数量估算会出偏差,导致成本核算失准或意外截断。
环节4:上下文组装
模型不是只看你这一句话。它看到的是一个精心组装的"完整文本包":
[System Prompt] ← 系统指令:"你是一个会议总结助手,请结构化输出"
[历史对话] ← 之前说过的话(如果有多轮对话的话)
[检索结果] ← 从知识库找到的相关信息(如果开启了RAG)
[当前用户输入] ← "帮我总结今天上午的技术评审会议重点"这四部分按顺序拼接成一个长文本,作为模型的输入。
产品架构师关注点:这个组装过程的设计直接决定了AI回答的质量。System Prompt写得好不好、历史对话保留多少轮、检索结果相不相关——全在这一步。
耗时:1-10ms(如果有RAG检索,则取决于检索耗时)
出问题时的表现:上下文组装出了bug,比如历史对话拼接顺序颠倒,导致模型"时间错乱"——回答明显不连贯但看不出原因。或者System Prompt意外被截断(超出窗口),模型行为变得不稳定。
环节5:(可选)检索增强(RAG)
如果你的AI系统接入了企业知识库、文档库或搜索引擎,这一步就会被触发:
- 把用户问题转为向量(Embedding)
- 去向量数据库里找最相关的文档片段
- 把找到的内容塞进上下文(环节4中的"检索结果")
耗时:50-500ms(向量检索 + Reranking)
为什么重要:这是解决"模型不知道私有知识"的核心手段。第7章会展开。
出问题时的表现:检索召回了不相关的文档片段,模型拿着"垃圾材料"作答,给出一本正经的错误答案——这比不开RAG还要糟糕。另一种情况是检索耗时突刺,把整条链路的延迟拖到3-5秒,用户体验直接崩塌。
环节6:模型推理(核心环节)
终于到了大模型"动脑"的时刻。
组装好的上下文被送到GPU上,模型开始逐token生成回答。每生成一个token,都要跑一遍完整的前向传播(涉及几十亿甚至几百亿参数的矩阵运算)。
两个阶段:
- 预填充(Prefill):一次性处理所有输入token,构建KV Cache → 决定了"首字延迟"(TTFT, Time To First Token)
- 解码(Decode):逐个生成输出token → 决定了"生成速度"(tokens/second)
耗时:
- 首字(TTFT):200ms-2s(取决于输入长度和模型大小)
- 整体生成:1-15s(取决于输出长度)
这是整条链路中耗时最长、成本最高的环节。 第4章会深入讲推理优化。
出问题时的表现:GPU显存不足导致OOM(Out of Memory),请求直接失败;或者并发请求过多时排队,首字延迟从0.8s突然变成8s——用户以为卡了,刷新页面又发一次,进一步加剧拥堵。
环节7:输出解码与流式传输
模型每生成一个token(数字ID),需要反向映射回文字。现代AI产品几乎都采用流式传输(Streaming)——边生成边发给用户,而不是等全部生成完再一次性返回。
这就是为什么你看到AI的回答是"一个字一个字蹦出来"的——不是设计成这样的酷炫效果,而是它确实就是一个一个token生成的。
产品架构师关注点:流式传输大幅改善了用户感知体验(用户在首字出现时就开始阅读,而不是盯着空白等完整答案)。
出问题时的表现:流式输出中途断连,用户看到内容戛然而止,页面停在半句话中间——这是最常见的推理服务稳定性问题之一。
环节8:后处理与安全过滤
模型输出的内容在到达用户之前,还要再过一道"质检":
- 输出内容安全审核(模型可能生成违规内容)
- 格式化处理(Markdown渲染、代码高亮等)
- 日志记录(用于审计、计费、效果监控)
- 用户反馈收集(点赞/点踩——用于后续优化)
耗时:5-50ms
出问题时的表现:输出安全过滤过于激进,把正常的商业建议或风险描述误判为违规内容整段删除,用户收到空回答;或者日志记录失败导致计费数据丢失——财务对不上账时才被发现。
全链路延迟拆解
| 环节 | 典型耗时 | 占比 |
|---|---|---|
| ①用户输入 | ~0ms | - |
| ②安全检查 | 5-50ms | 1-3% |
| ③Tokenization | <1ms | <1% |
| ④上下文组装 | 1-10ms | <1% |
| ⑤RAG检索 | 50-500ms | 5-20% |
| ⑥模型推理 | 1-15s | 70-90% |
| ⑦流式传输 | 与⑥并行 | - |
| ⑧后处理 | 5-50ms | 1-3% |
核心结论:推理(环节6)吃掉了绝大部分延迟和成本。这就是为什么第4章要花一整章讲推理优化——因为优化其他环节只是锦上添花,优化推理才是乘数效应。
2.2 Tokens:大模型的"原子单位"
在AI的世界里,有一个概念你会听到无数次:Token。
计费按token、窗口按token、速度按token衡量。如果你不理解token,你就无法理解AI系统的任何成本和性能数据。
什么是Token?
Token不是"字",也不是"词"。它是一种介于两者之间的子词单元。
分词器(Tokenizer)会把文本切割成模型词汇表里的最小单位:

【图2-2:Token切分示意图】
英文示例:
英文的token切分很有意思——常见词通常是1个token,生僻词或长词会被拆开:
"cat" → ["cat"] → 1 token
"cats" → ["cats"] → 1 token
"concatenate" → ["conc", "aten", "ate"] → 3 tokens
"ChatGPT" → ["Chat", "G", "PT"] → 3 tokens
"is amazing" → [" is", " amazing"] → 2 tokens我第一次看这个结果时有点懵——"ChatGPT"这个词只有7个字母,居然要3个token?后来才明白:token是从词汇表里查匹配的,词汇表没有"ChatGPT"这个完整词条,就得拆成子词。这也解释了为什么一段英文代码(变量名、函数名都是生僻词组合)会比同等长度的普通英文贵很多——因为代码token化效率低。
中文示例:
"大模型很强大" → ["大", "模型", "很", "强大"] → 4 tokens
"人工智能" → ["人工", "智能"] → 2 tokens直觉:
- 英文常见词通常是1个token,生僻词/代码标识符可能要2-4个
- 中文一个汉字通常是1-2个token(GPT系列的中文效率比英文低约1.5倍)
- 粗略估算:1000个中文字 ≈ 700-1500 tokens
为什么Token这么重要?
因为AI系统的三大核心指标——能力、成本、速度——都以token为计量单位:
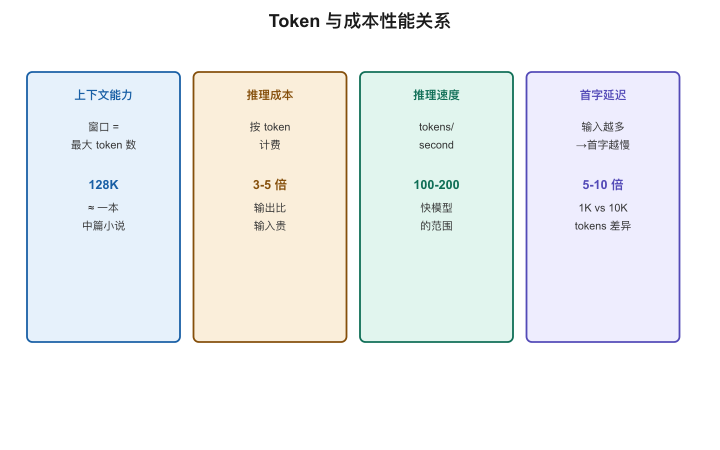
【图2-3:Token与成本/性能关系(信息卡片)】
| 指标 | 与Token的关系 | 直觉 |
|---|---|---|
| 上下文能力 | 窗口大小 = 最大token数 | 128K tokens ≈ 一本中短篇小说 |
| 费用 | 按token计费 | GPT-4o: ~$2.5/百万输入token |
| 推理速度 | tokens/second | 快的模型: 100-200 tok/s |
| 延迟 | 输入token越多→首字越慢 | 1000 tokens vs 10000 tokens: TTFT差5-10倍 |
Token经济学:为什么AI"越聊越贵"
一个产品架构师必须理解的成本结构:
输入token和输出token分别计费——而且输出通常比输入贵3-5倍。为什么?因为输入是批量并行处理的,输出是逐个串行生成的,计算密度不同。
长对话为什么贵:在多轮对话中,每一轮的"输入"都包含所有之前的对话历史。第10轮对话的输入token数量可能是第1轮的10倍。
这意味着:
- 一个聊了50轮的对话,总token消耗不是50轮的简单累加,而是一个等差数列求和——远高于你的直觉
- 产品设计时必须考虑:何时"截断"历史、何时"总结"历史、何时"清空"重新开始
产品架构师的token成本意识:做一个AI功能的需求评审时,有几个问题是我现在一定会问的——"这个场景平均输入多少token?输出多少token?一天调用量多少?"——三个数字乘起来,你就能估出月成本的数量级。很多项目在这一步就能发现商业模式有问题,比继续推进后再发现要好得多。
2.3 上下文窗口与Attention:为什么"记忆力"有限
上下文窗口:模型的"工作桌面"
上下文窗口是大模型最关键的"物理限制"之一。
类比:把上下文窗口想象成你的工作桌面。所有和当前任务相关的资料——会议纪要、参考文档、之前的对话——都要摊在这张桌子上。桌面只有这么大,放不下的东西你就看不到。
各模型窗口大小对比:
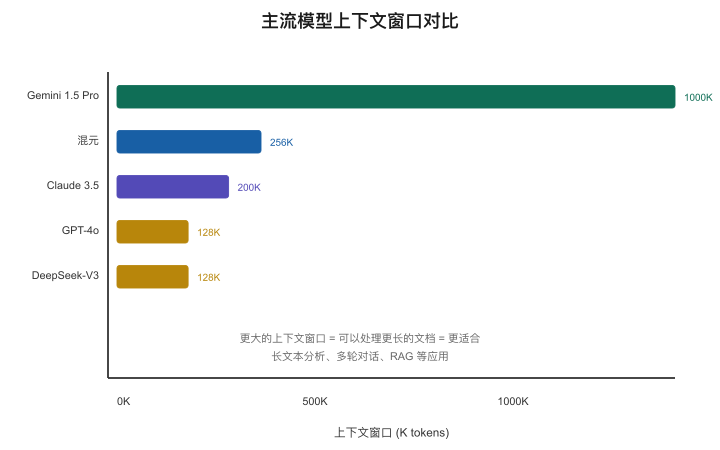
【图2-4:主流模型上下文窗口对比】
| 模型 | 上下文窗口 | 约等于 |
|---|---|---|
| GPT-4o | 128K tokens | ~15万汉字 / 一本中篇小说 |
| Claude 3.5 Sonnet | 200K tokens | ~25万汉字 |
| Gemini 1.5 Pro | 1M tokens | ~120万汉字 / 3-4本书 |
| DeepSeek-V3 | 128K tokens | ~15万汉字 |
| 混元 | 256K tokens | ~30万汉字 |
Attention:阅读时的"高亮标注"
上一章提到过Attention机制。在这里我们从产品影响的角度再理解一次:
Attention决定了模型在生成每一个词时,"回看"上下文的哪些位置。它就像你阅读时的高亮笔——不是每个字都同等重要,模型会自动"标注"和当前生成最相关的上文内容。
但这有一个代价:计算量和上下文长度的平方成正比。
这意味着:
- 上下文从10K增长到100K(10倍),计算量增加约100倍
- 这就是为什么"长文本对话"比"短文本对话"贵得多,也慢得多
一个反直觉的坑:很多人看到"Gemini支持1M context"就很兴奋,觉得可以把整本产品文档都塞进去问模型。但塞进100万token不代表模型都能"看到"——实验数据表明,超长上下文的"中间部分"往往被模型忽略,这叫做"Lost in the Middle"问题。桌面越大,不代表你能同时盯住桌面上的每一样东西。
对产品架构的影响
| 设计决策 | 影响 | 策略 |
|---|---|---|
| 保留多少轮历史对话 | 轮数越多→质量越高→但成本越大 | 设上限 + 智能总结 |
| 检索多少条参考文档 | 条数越多→信息越全→但干扰也越多 | 动态调整 + Reranking |
| System Prompt多长 | 越详细→行为越可控→但挤占用户内容空间 | 精简核心指令 |
| 输出长度限制 | 输出越长→成本越高→且后半段质量下降 | 设max_tokens + 分段生成 |
产品架构师的核心判断:上下文窗口是一种有限资源。它不是"越大越好用"这么简单——越大意味着越贵、越慢。你的工作是把这有限的"桌面空间"分配给最有价值的信息。这件事本质上是一道资源分配题,和你分配项目排期、分配研发资源没有本质区别。
2.4 技术栈分层全景图:从GPU到APP的六层
好了,到了本章最重要的部分。
前面讲了一次对话的"时间维度"(从发出到返回经历了什么)。现在我们换一个视角——空间维度:支撑这次对话的整个技术体系,从底到顶分为几层?

【图2-5:L1-L6技术栈分层全景图】
为什么需要分层思维
类比:你住的房子也是分层的。
- 地基(L1)→ 你不需要每天关心,但它坏了整栋楼都塌了
- 结构(L2-L3)→ 承重墙、水电管道,平时看不见但决定了功能上限
- 装修(L4-L5)→ 你直接接触的部分,影响日常体验
- 家具和住户(L6)→ 最终的使用者
AI技术栈也是这样。让我们从底到顶走一遍:
L1 · 算力基础设施——地基
这一层回答的问题:模型跑在什么硬件上?
| 组成 | 作用 |
|---|---|
| GPU集群 | 提供并行计算能力(训练和推理的核心硬件) |
| 高速网络(NVLink/InfiniBand) | GPU之间、机器之间高速通信 |
| 存储系统 | 存放训练数据和模型文件 |
| 资源调度 | 把GPU分配给不同的任务/用户 |
产品架构师需要知道的:你不需要采购GPU,但需要知道"我的场景需要多少算力"和"算力紧张时会怎样影响服务质量"。这一层是你在做"私有化部署 vs 云API"这道决策题时的成本底盘。
→ 第3章展开
L2 · 模型训练平台——建造过程
这一层回答的问题:模型是怎么被训练出来的?
| 组成 | 作用 |
|---|---|
| 数据处理管线 | 清洗、去重、脱敏训练数据 |
| 分布式训练框架 | 让成百上千块GPU协同训练一个模型 |
| 训练管线 | 预训练→SFT→RLHF的全流程 |
| 实验管理 | 追踪和对比不同训练实验的效果 |
产品架构师需要知道的:你不需要自己训模型(大部分情况下),但需要理解"微调"和"预训练"的区别,以及什么场景需要训、什么场景用现成的就够了。当算法团队说"我们需要再训一轮"时,你要能判断这是合理需求还是过度投入。
→ 第3章展开
L3 · 模型推理服务——工厂生产线
这一层回答的问题:训好的模型怎么变成一个能7×24小时服务的系统?
| 组成 | 作用 |
|---|---|
| 推理引擎 | 优化模型运行速度(vLLM/TensorRT-LLM) |
| 服务框架 | 提供API接口、处理并发请求 |
| 弹性扩缩容 | 流量高峰自动加机器,低谷自动减 |
| 模型管理 | 多模型加载、版本切换、灰度发布 |
产品架构师需要知道的:推理是AI系统中成本最高的环节。模型选大还是选小、用什么量化策略、怎么做批处理——这些技术选择直接影响产品的成本和响应速度。
→ 第4章展开
L4 · 模型服务与治理——物流与质检
这一层回答的问题:怎么管理和治理模型服务,让它安全、可控、可追溯?
| 组成 | 作用 |
|---|---|
| AI网关 | 统一API入口、鉴权、计费、限流、路由 |
| 内容安全 | 输入输出过滤、敏感信息脱敏 |
| 可观测性 | 日志、监控、告警、效果追踪 |
| 多模型路由 | 不同场景路由到不同模型(成本/效果平衡) |
产品架构师需要知道的:这是你直接参与设计的层。AI网关就像传统架构中的API Gateway——它是控制面,决定了谁能用、怎么用、花多少钱。这一层设计得好,后续所有模型替换、成本优化、灰度发布都有抓手;设计得差,每次改动都要大动手术。
→ 第4章、第9章展开
L5 · 应用开发框架——产品设计与组装
这一层回答的问题:在模型能力之上,怎么组装出真正能解决业务问题的应用?
| 组成 | 作用 |
|---|---|
| RAG框架 | 让模型能检索和利用外部知识 |
| Agent框架 | 让模型能调用工具、自主规划和执行 |
| Prompt管理 | System Prompt的版本管理和AB测试 |
| 编排工具 | 把多个AI能力串联成工作流(Dify/Coze) |
产品架构师需要知道的:这是你的核心战场。RAG还是微调?Agent还是Workflow?单模型还是多模型协作?——这些架构决策都发生在L5,也是你和算法工程师讨论最多的地方。
→ 第6-8章展开
L6 · 终端AI产品——面向用户
这一层回答的问题:最终用户看到的是什么?
智能客服、AI搜索、代码助手、文档处理、会议纪要、创作工具……所有面向最终用户的AI功能,都属于这一层。
产品架构师需要知道的:这一层的设计不只是技术问题——它是产品设计问题:用户预期管理、AI能力的展示与约束、失败时的兜底体验、用户反馈的闭环。很多AI产品口碑差不是因为模型能力不行,而是L6的产品设计没想清楚。
→ 第10-11章展开
层与层之间的依赖关系
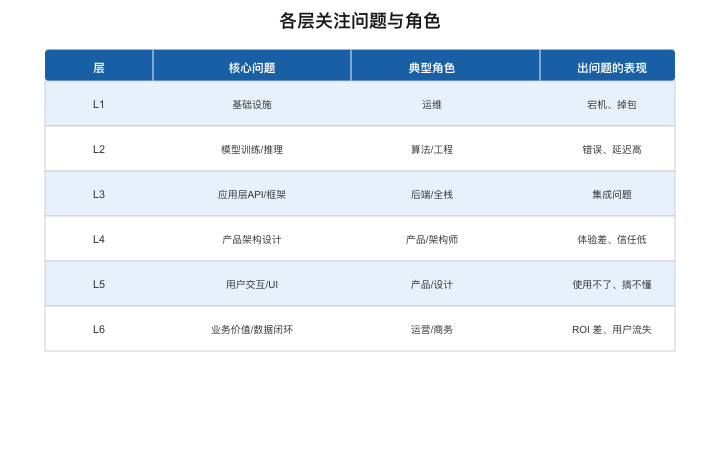
【图2-6:各层关注问题与对应角色】
| 层 | 核心问题 | 典型角色 | 出问题的表现 |
|---|---|---|---|
| L1 算力 | "跑得动吗?" | Infra工程师 | GPU不够→排队/OOM |
| L2 训练 | "学得好吗?" | 算法工程师 | 模型效果差/幻觉多 |
| L3 推理 | "服务得动吗?" | 推理优化工程师 | 延迟高/成本爆 |
| L4 治理 | "管得住吗?" | 平台产品经理 | 安全漏洞/成本失控 |
| L5 应用 | "用得好吗?" | AI应用开发者 | 检索不准/Agent失控 |
| L6 产品 | "用户满意吗?" | 产品架构师/PM | 体验差/信任度低 |
关键认知:上层依赖下层,但不需要了解下层的所有细节。 就像你开车不需要懂发动机原理,但需要知道"油不够了会趴窝"。
2.5 产品架构师的全景视角
看完6层,一个自然的问题是:我作为产品架构师,应该精通哪些层?了解哪些层?
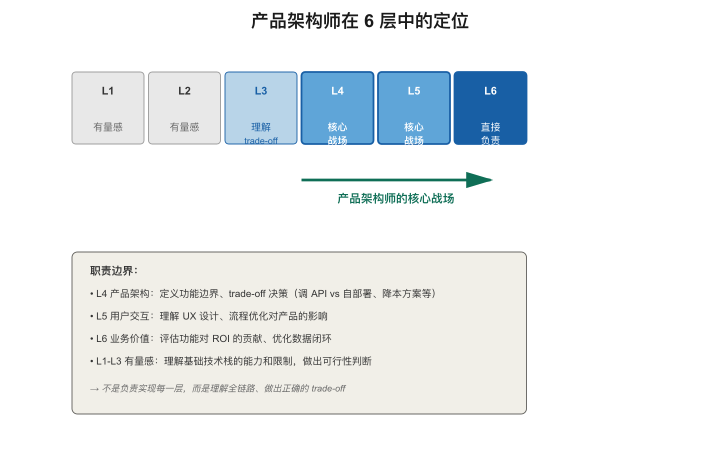
【图2-7:产品架构师在6层中的定位】
| L1算力 | L2训练 | L3推理 | L4治理 | L5应用 | L6产品 | |
|---|---|---|---|---|---|---|
| 精通程度 | 有量感 | 有量感 | 理解trade-off | 直接参与 | 核心战场 | 直接负责 |
| 典型决策 | 是否私有化 | 是否需微调 | 选多大模型 | 网关策略 | RAG/Agent架构 | 产品体验 |
一个问题如何跨层传导
来看一个真实场景:用户反馈"AI回答太慢了"。
作为产品架构师,你需要精确归因:
- 是L3的问题?(推理引擎没优化、模型太大、GPU不够)
- 是L5的问题?(RAG检索太慢、Agent工具调用等待)
- 是L4的问题?(API网关限流了、路由到了慢节点)
- 还是L6的产品设计问题?(没有流式输出、loading态设计差)
同样,"AI回答不准确"也需要跨层分析:
- L2:模型本身训练数据质量差
- L5:RAG检索没有命中正确的文档
- L4:Prompt模板设计有问题
- L6:用户的问题表述太模糊
这就是"分层地图"的核心价值——让你在面对复杂问题时,不会"一锅端",而是精确定位到具体的层和环节。 在一次AI产品的故障复盘里,你能说出"问题出在L5的RAG检索阶段,召回精度不够",比说"AI的效果有问题"的价值高一个数量级——因为前者指向一个具体可修复的问题,后者只是在描述症状。
本章小结
-
一次AI对话经过8个环节——从安全检查到Tokenization到推理到后处理。其中模型推理吃掉了70-90%的延迟和成本。每个环节都有独特的故障模式,理解它们才能精确归因。
-
Token是AI世界的"原子单位"——窗口按token算、费用按token收、速度按token量。1000汉字≈700-1500 tokens;中文的token效率比英文低约1.5倍。
-
上下文窗口是有限资源——不是越大越好,而是需要智能分配。计算量和长度的平方成正比;超长上下文还存在"Lost in the Middle"的注意力衰减问题。
-
6层技术栈(L1-L6)是理解AI系统的核心框架——从算力到训练到推理到治理到应用到产品,每层有独立的技术挑战和负责角色。
-
产品架构师的工作在L4-L6,但需要对L1-L3有"量感"——知道"能不能做""贵不贵""快不快",才能做出正确的架构决策。
下一章,我们把目光对准这张地图的底层——L1和L2:一个大模型是怎么"造"出来的?从GPU集群到训练平台,再到预训练、SFT、RLHF这条完整的生产线,逐一拆开看。这是产品架构师最容易被算法团队"忽悠"的地方,也是最值得建立量感的地方。
延伸阅读
- OpenAI Tokenizer 可视化工具(https://platform.openai.com/tokenizer)—— 动手输入你的真实Prompt,看看实际会切成多少token
- Nelson F. Liu et al.,《Lost in the Middle: How Language Models Use Long Contexts》(2023)—— 理解超长上下文"注意力衰减"问题的原始论文
- 腾讯云AI网关产品文档 —— 理解L4层"模型服务治理"的实际产品形态