学习笔记-AIGC全栈认知与落地(1)
第1章 · 大模型到底是什么
开场:那个让我感到"无知"的评审会
我是一个产品架构师。这个身份意味着,我的日常工作是理解技术、理解业务、在两者之间设计解决方案。在云计算、微服务、容器这些领域,我自认有足够的判断力——即使不用动手写代码,我也能一眼看穿架构图里的猫腻、准确评估系统承载力并识别出核心风险。
直到我第一次坐进一场大模型方案评审会。
那是一个客户的AI中台项目,需要我作为云原生专家,提供底座技术支持和架构评审。评审会上,算法团队在汇报他们的技术方案。他们讲了整整三十分钟,可台下的我却经历了一场奇妙的“智商降维打击”。PPT上的中文词汇我每个都认识,但当它们拼在一起时,却变成了一门我完全听不懂的外语:
“预训练阶段我们使用了2T tokens的数据”——2T到底是什么概念?对我们的业务来说够不够用?
“模型展现出了涌现能力”——涌现是什么意思?是说它突然自己变强了?凭什么突然就变强了?
“我们通过RLHF完成了对齐”——对齐什么?和谁对齐?我们当前的业务方案到底对齐了没有?
会议结束后,我走出会议室,心里极其发虚。作为架构师,我其实根本没有弄清楚这个方案的核心假设是什么、技术风险究竟在哪里。我只是凭借着多年练就的职业素养,在台下保持着专业而得体的微笑。因为方案整体逻辑顺畅、结构完整,我最终没有针对大模型这个部分提出任何异议。
这种感觉很不舒服,甚至让我感到一丝恐慌。作为一个产品架构师,“看不懂核心技术”是一件职业风险极高的事。它意味着你的评估失去了抓手,你只能被别人的结论推着走。
我当时最大的困惑,并不是“AI能不能实现这个功能”——那是去体验一下产品就能直观感知到的。
我真正想搞清楚的是:凭什么?
它的能力到底从哪里来?它的技术天花板究竟在什么地方?它是沿着某种可预测的轨迹一步步进化到今天的,还是突然“蹦”出来的?为什么同一个模型,有人能用它把业务做得风生水起,有人却用得一塌糊涂?
这一章,就是为了回答这些问题的。如果你也曾有过类似的困惑——坐在一群算法工程师中间,觉得自己像个听天书的局外人——那么,这一章就是专门写给你的。
1.1 极简简史:从"人写规则"到"机器自己学"
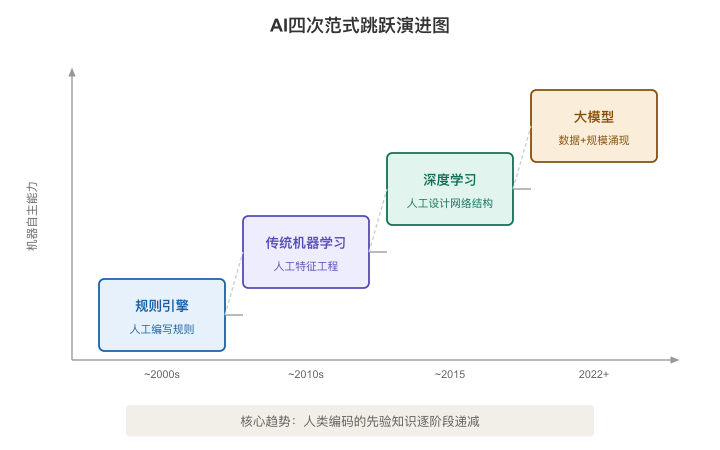
AI不是2022年突然出现的。它经历了四次范式跳跃,每一次跳跃的本质都是同一件事:人类需要手工编写的"先验知识"变少了一层。
理解这四次跳跃,你就能理解大模型为什么是一个质变而不仅仅是量变。
第一阶段:规则引擎(人写全部逻辑)
最早的"AI"——如果它配叫这个名字——就是一堆if-else。
如果客户说了"退款" → 回复"请提供订单号"
如果客户说了"投诉" → 转接人工
如果客户说了其他 → 回复"您好,请问有什么可以帮您?"这种系统极度可控。你知道它在每种情况下会做什么,因为每一种情况都是你手写的。但它的问题也显而易见:世界太复杂了,你写不完所有规则。客户说"我要退货"呢?"能不能把钱退给我"呢?"这个东西不好用"呢?
规则引擎就像一台自动贩卖机:你按哪个按钮它就出什么饮料,但按钮只有那么几个。
第二阶段:传统机器学习(人选特征,算法学规律)
到了2010年代初,人们发现一条新路:不用人写规则了,让算法自己从数据里"学"出规律来。
比如垃圾邮件识别。你不需要手写"如果邮件标题包含'中奖'就标记为垃圾"这种规则。你只需要:
- 收集一万封邮件,标注好"正常"和"垃圾"
- 告诉算法:"去看这些邮件的特征——标题长度、有没有链接、发送时间、用词风格"
- 算法自己找出规律:原来垃圾邮件通常标题长、链接多、深夜发送
这比规则引擎强太多了。但注意——你仍然需要告诉算法"看哪些特征"。这一步叫特征工程,是传统机器学习里最耗人力的部分。
传统ML就像一个有经验的分拣工:你告诉他"看苹果的颜色和硬度来判断好坏",他能学得很好。但他需要你告诉他"看什么"。
第三阶段:深度学习(人给数据,模型自己学特征)
2015年之后,深度学习横空出世。它和传统ML的关键区别是:连特征都不需要人选了。
以图像识别为例。你不需要告诉模型"看眼睛、看鼻子、看轮廓"来判断这是猫还是狗。你只需要给它十万张标注好的图片——"这是猫""这是狗"——它自己会学出需要看哪些特征。
这一步是巨大的跃迁。但深度学习时代有一个核心限制:每个任务需要单独训一个模型。 识别猫狗的模型不能用来翻译英文,翻译英文的模型不能用来做情感分析。你有100个任务,就得训100个模型。
深度学习就像一个学徒:你给他足够的例子他自己能总结规律,但他只学一门手艺——学了做面包不等于学了做蛋糕。
第四阶段:大模型(一个模型,几乎所有语言任务)
然后是2022年。
大模型带来的根本变化不是"更准了"或"更快了"——而是一个模型能做几乎所有用语言表达的任务。翻译、总结、写代码、分析数据、角色扮演、头脑风暴……你不需要为每个任务单独训一个模型了。
这就像从"一事一专家"变成了"一个什么都能聊的通才"。
大模型就像一个读遍图书馆的通才:什么话题都能聊,什么任务都能试。它的水平参差不齐——有些事做得特别好,有些事会出错——但它的广度是前所未有的。
四次跳跃的本质
把这四个阶段放在一起看,你会发现一条清晰的主线:
【图1-1:AI四次范式跳跃演进图】
| 阶段 | 时代 | 人需要做什么 | 机器做什么 | 类比 |
|---|---|---|---|---|
| 规则引擎 | ~2000s | 写全部规则 | 执行规则 | 自动贩卖机 |
| 传统ML | ~2010s | 选特征、标数据 | 学规律 | 有经验的分拣工 |
| 深度学习 | ~2015 | 给数据 | 学特征、学规律 | 学徒(一门手艺) |
| 大模型 | 2022+ | 几乎什么都不用做 | 自己学会大部分语言任务 | 通才(读遍图书馆) |
每一次范式跳跃 = 人类需要编码的先验知识减少一层。
大模型之所以让整个行业震动,是因为它把这个趋势推到了一个临界点:你不再需要"教"它做什么任务——你只需要用自然语言"告诉"它你想要什么。
这就是为什么它被称为一次范式变革,而不仅仅是"又一次模型变大了"。
1.2 大模型的本质:一台超级强大的"下一个词预测机"
好,那大模型到底在做什么?它是怎么"学会"这么多事情的?
答案出奇地简单——简单到你可能不太相信:
大模型的核心任务只有一个:给定前面的所有文字,预测下一个最可能的词是什么。
就这么一件事。没有别的。
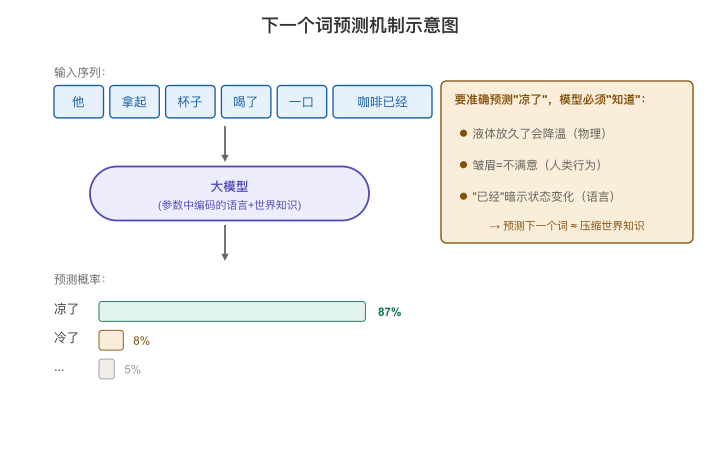
为什么"预测下一个词"能产生智能?
这是最反直觉的部分。一个只会"猜下一个词"的系统,为什么看起来好像理解了语言、逻辑、常识、甚至推理?
答案是:要准确预测下一个词,模型不得不"学会"很多东西。
举个例子。如果我给你一段话:
"地球围绕太阳运转,一圈大约需要___"
你知道下一个词大概率是"365天"或"一年"。但你为什么知道?因为你理解天文学常识。
再来一个:
"他拿起杯子喝了一口,皱了皱眉——咖啡已经___"
你知道下一个词大概率是"凉了"。但你为什么知道?因为你理解物理世界(液体会变凉)和人类行为(皱眉=不满意)。
大模型就是这样"被迫"学会了世界知识的:当训练目标是"预测下一个词",而训练数据是人类写过的几乎所有文本时,模型为了把这件事做好,不得不在参数里"编码"大量关于语言、逻辑、常识、事实的知识。
【图1-2:"下一个词预测"机制示意图】
一个反直觉但极其有用的思考方式:如果一个人能完美地续写任何一本书的下一页——不管是物理教材、法律文书、Python代码还是言情小说——那他的知识储备得有多大?答案是:和大模型差不多大。
参数 = 压缩知识
当我们说一个模型有"7B参数"或"70B参数",可以这样理解:
参数就是模型用来"记住"所学知识的容量。7B参数就像一个7GB的笔记本,70B就像一个70GB的笔记本。笔记本越大,能记住的模式、规律、事实越多。
但注意——参数量和能力之间不是简单的线性关系。一个700亿参数的模型不一定比70亿的好10倍。这就像一个人读了1000本书不一定比读了100本书聪明10倍——关键在于他有没有融会贯通。
产品架构师的关注点:参数量影响的主要是——
【图1-3:参数量与四维指标关系】
| 参数规模 | 知识广度 | 推理深度 | GPU显存需求 | 推理延迟 | 典型场景 |
|---|---|---|---|---|---|
| 1-7B(小) | ★★☆ | ★★☆ | 单卡可跑 | 快 | 分类、提取、简单对话 |
| 13-70B(中) | ★★★ | ★★★ | 多卡/单机 | 中 | 通用对话、代码、分析 |
| 100B+(大) | ★★★★ | ★★★★ | 多机集群 | 慢 | 复杂推理、创作、全能 |
这四者之间存在根本性的trade-off:更大的模型更聪明,但也更贵更慢。后面章节选型时我们会反复用到这个认知。
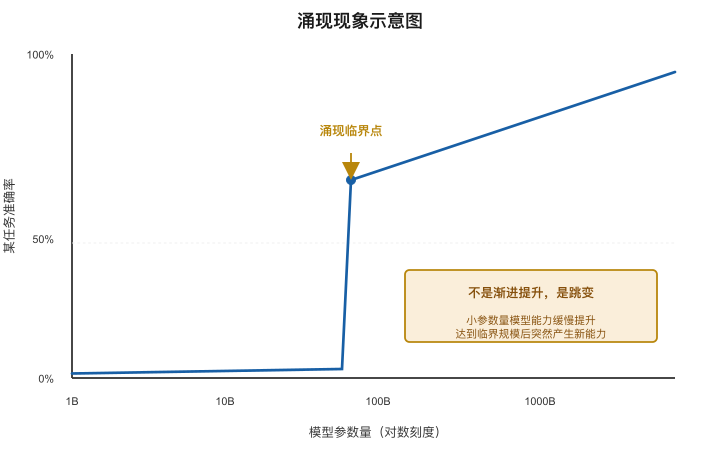
涌现:大模型"突然变聪明"
在大模型的研究中有一个特别有趣的现象叫涌现(Emergence)。
简单说就是:当模型小的时候,某些任务它完全做不了,得分接近零。但当模型大到一定程度,这些能力突然就"冒"出来了——不是渐进提升,而是从"不会"到"会"的跳变。
这就像学英语:你的词汇量从2000增长到3000,体感只是多认识了几个词。但从3000增长到5000的某个时刻,你突然发现——诶,我能读懂整本英文小说了!这不是因为最后那500个词有什么魔力,而是知识积累到一个临界点后产生了质变。
这个现象对产品架构师的含义是:你不能通过在小模型上测试来预判大模型的表现。 有些任务,7B模型做不好不代表70B也做不好——可能恰恰相反。这是一个评估和选型时需要特别注意的陷阱。
【图1-4:涌现现象示意图】
Transformer:为什么"这个架构"特别行
大模型几乎都基于一个叫Transformer的架构。我不打算讲它的数学原理(那是算法工程师的事),但你需要有一个直觉:Transformer为什么比之前的架构好。
之前的主流架构(RNN/LSTM):逐字逐句地阅读,像看书一样从左到右一个字一个字读。问题在于:读到第200个字时,第1个字说了什么已经快忘了。
Transformer的核心创新(Attention机制):允许模型在处理任何一个词时,同时"看"到整段文本的任意位置。就像你阅读时可以随时回翻前面的内容,或者高亮标注"这里和那里有关系"。
一句话总结:Attention让模型能高效处理长距离的关联关系。这就是为什么大模型能理解复杂的上下文、保持话题的连贯性、甚至做多步推理。
产品架构师需要记住的一点:Transformer架构的计算量和上下文长度的平方成正比。这意味着——上下文窗口越长,计算成本增长得越快。这是后面讲推理成本和长对话设计时的基础认知。
1.3 为什么GPT-3.5是行业分水岭
大模型不是GPT-3.5才出现的。GPT-3在2020年就已经展现了惊人的能力——给它几个例子它就能完成新任务,不需要额外训练。学术界已经意识到了大模型的潜力。
但普通人几乎没有感知。为什么?
GPT-3的"能力"和"可用性"之间的鸿沟
GPT-3有一个关键问题:它不"听话"。
你问它一个问题,它可能给你一个答案,也可能继续生成一堆不相关的文本。你要它写一段总结,它可能给你一篇文章。它有能力,但你很难可靠地"指挥"它。
用产品的语言说:能力储备了,但产品化的门槛还没有跨过去。
RLHF:教模型"听话"
GPT-3.5(以及ChatGPT)的关键突破不是模型变大了——实际上参数量变化并不显著。关键的突破是一个叫RLHF(基于人类反馈的强化学习)的训练阶段。
RLHF做的事情,用大白话说就是:
- 让模型对同一个问题生成多个回答
- 让人类标注员评判:哪个回答更好
- 根据这些反馈训练模型,让它学会"什么样的回答让人满意"
这不是技术突破(RLHF的论文早就发了),而是产品化突破。
前后对比:
- RLHF之前:模型像一个博学但不懂交流的学者——你问他天气,他可能给你讲一篇气象学论文
- RLHF之后:模型像一个理解需求的助手——你问他天气,他说"北京今天晴转多云,25度"
ChatGPT:对话作为交互界面
另一个关键变化是产品形态。ChatGPT把大模型包装成了一个对话界面——多轮对话、上下文连贯、交互自然。
这看起来只是一个UI决策,但它的产品含义是深远的:
- 之前:使用AI需要学习API、调参数、写Prompt模板。门槛很高,用户是开发者。
- 之后:使用AI只需要会说话。门槛几乎为零,用户是所有人。
这对产品架构师意味着什么

【图1-5:GPT-3 vs GPT-3.5 对比图】
| 维度 | GPT-3(2020) | GPT-3.5/ChatGPT(2022) |
|---|---|---|
| 核心能力 | 已具备语言生成、推理雏形 | 能力相近,部分提升 |
| 指令遵从 | ❌ 经常答非所问 | ✅ 理解并执行指令 |
| 对话能力 | ❌ 单轮、无记忆 | ✅ 多轮、上下文连贯 |
| 使用门槛 | 需要API + Prompt工程 | 会打字就能用 |
| 用户群体 | 开发者/研究者 | 所有人 |
| 关键突破 | — | RLHF(让模型"听话")+ 对话产品化 |
GPT-3.5/ChatGPT给我最深的一课是:
"能力"和"可用性"是两件完全不同的事。
一个AI系统可能在技术能力上达到了90分,但如果用户不知道怎么可靠地使用它、不信任它的输出、或者无法控制它的行为——那在产品层面它可能只有30分。
反过来也成立:一个能力只有70分的模型,如果交互设计得好、预期管理得当、有合理的兜底——产品体验可能达到85分。
这是一个我在整本书里会反复回来的核心观点:产品架构师的真正战场不是追求最强的AI能力,而是在能力和可用性之间找到最优的平衡点。
1.4 大模型的能力边界:知道它"不能做什么"
作为产品架构师,知道大模型能做什么当然重要。但更重要的是知道它不能做什么——因为这决定了你的产品设计不会掉坑里。
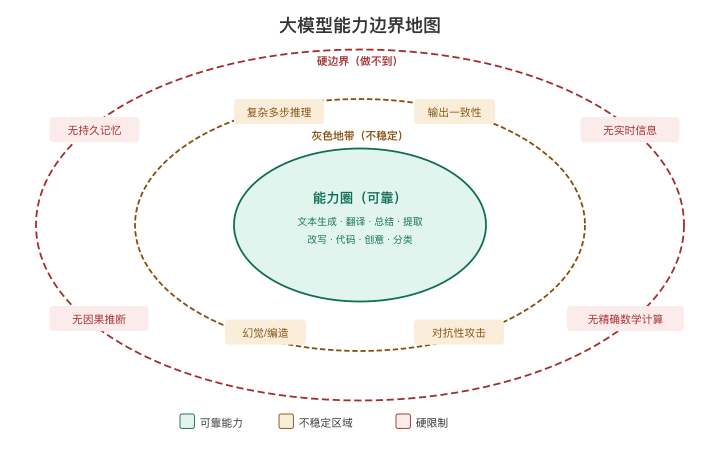
我把大模型的边界分为三类:硬边界、软边界和灰色地带。
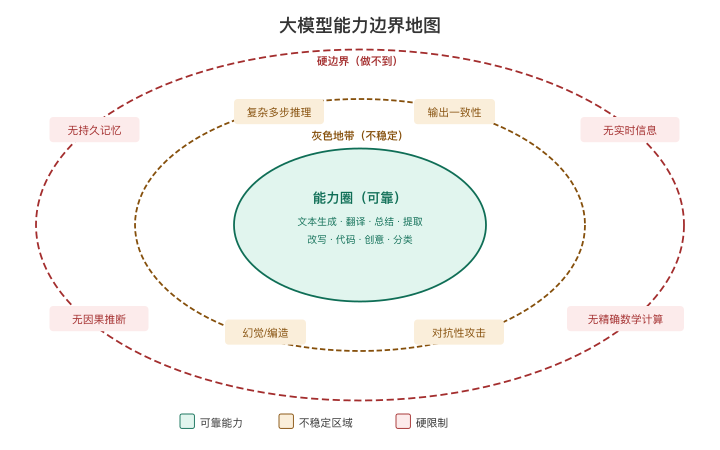
【图1-6:大模型能力边界地图(同心圆)】
硬边界:它真的做不到
1. 没有持久记忆
大模型没有"记住"这个能力。它的"记忆"全部依赖上下文窗口——一旦对话结束或超出窗口长度,一切归零。
上下文窗口是什么?简单说就是模型一次能"看到"的文本长度。GPT-4 Turbo大约是128K tokens(约25万汉字),Claude是200K tokens。听起来很大了,但对于需要长期记忆的场景(比如"记住用户三个月前说过的偏好"),这远远不够。
产品设计含义:任何需要"记住用户历史"的产品功能,不能依赖模型本身——你需要外部存储 + 检索机制。这正是RAG(第7章)和记忆系统存在的原因。
2. 没有实时信息
大模型的知识来自训练数据,有一个截止日期。比如一个2024年1月训练完成的模型,它不知道2024年2月之后发生的任何事。
你问它"今天股市怎么样"——它无法回答,不是因为它不懂金融,而是它根本不知道"今天"是哪天。
产品设计含义:任何涉及实时信息的功能,都需要外挂检索/工具调用能力——让模型能"上网查"。
3. 不具备因果推断
大模型擅长找相关性,但不能做因果推断。它能告诉你"吃冰淇淋的人溺水率更高",但不能正确推断"吃冰淇淋不会导致溺水,两者都和夏天有关"——除非它在训练数据里见过这个具体的解释。
软边界:能做但不可靠
1. 幻觉(Hallucination)
这是产品架构师最需要警惕的问题。大模型会极其自信地编造不存在的事实。
它会编造:
- 不存在的论文(包括作者、期刊、DOI号——全是假的但格式完美)
- 不存在的法律条款
- 不存在的API和函数名
可怕的地方在于:它编造时的语气和它说真话时一模一样。你无法通过"它说话有多确定"来判断它有没有在胡扯。
产品设计含义:任何AI生成的事实性内容,如果直接呈现给最终用户,都必须有验证机制或免责声明。关键场景必须引入人类审核环节。
2. 精确计算
大模型不是计算器。问它 "3847 × 2961 = ?" 它很可能算错。不是它不会算,而是它本质上是在"预测最可能的数字序列",不是在做真正的数学运算。
产品设计含义:涉及精确计算的场景,应该让模型调用工具(计算器、代码执行器)而非直接"想"出答案。这是Agent架构(第8章)中"工具调用"的典型应用。
灰色地带:有时候行、有时候不行
1. 复杂多步推理
大模型能做一定程度的推理,但当推理链条变长(比如需要5-6步逻辑),它经常在中间某一步出错。有时候做得到,有时候做不到——这种不确定性是产品设计的噩梦。
2. 输出一致性
同一个问题,不同时间问,可能得到不同的答案。甚至同一次请求,temperature参数(控制随机性的参数)不同也会导致不同结果。
3. 对抗性攻击
聪明的用户可以通过精心设计的Prompt"哄骗"模型突破安全限制。这类攻击叫Prompt注入/越狱——它是AI安全领域最活跃的攻防战场之一。
产品架构师的边界思维框架
面对这些边界,我总结出一个简单但管用的思考框架:
对于每一个你打算用AI实现的功能,问四个问题:
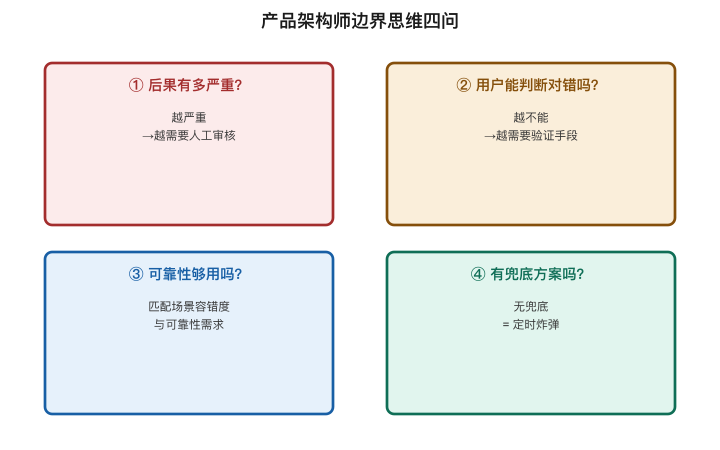 > 【图1-7:产品架构师的边界思维四问】
> 【图1-7:产品架构师的边界思维四问】
| # | 问题 | 判断标准 | 对应设计策略 |
|---|---|---|---|
| 1 | 给错了答案,后果是什么? | 后果越严重 → | 越需要人工审核环节 |
| 2 | 用户能自行判断对错吗? | 越不能判断 → | 越需要提供验证手段 |
| 3 | 可靠性在此场景够用吗? | 95%在闲聊够,在医疗不够 → | 匹配场景容错度 |
| 4 | 失败了有兜底方案吗? | 无兜底 = 定时炸弹 → | 必须设计降级路径 |
这个框架会在第9章"AI工程化"和第10章"产品架构方法论"中展开讲。
本章小结
走到这里,让我们回收一下这一章建立的核心认知:
-
大模型是四次AI范式跳跃的产物——每次跳跃都在减少人类需要手动编码的先验知识,大模型把这个趋势推到了极致。
-
它的核心机制是"预测下一个词"——但当这个任务在海量数据上做到极致时,模型被迫学会了语言、逻辑、常识和推理。
-
GPT-3.5的真正突破不是"更强"而是"更可用"——RLHF让模型听懂人话,ChatGPT让交互门槛降为零。对产品架构师来说,这是"能力≠可用性"的经典案例。
-
大模型有清晰的边界——无持久记忆、无实时信息、会幻觉、不擅长精确计算。知道这些边界,才能设计出不掉坑的产品。
-
产品架构师的核心判断力 = 在"AI能力"和"可靠性"之间找到最优平衡。这是整本书后续11章都在教你做的事。
知道了"大模型是什么",下一步自然要问:当我发出一句话,AI那边到底发生了什么?这3秒钟里经过了几个环节、每个环节在干什么、哪个环节最可能出问题?第2章建立的这张"链路全景图",是你看懂后续所有AI技术讨论的坐标系——没有它,第3-5章的内容很容易变成孤立的知识点。
延伸阅读
- 《Attention Is All You Need》(2017)—— Transformer架构的原始论文。你不需要看懂数学,但了解它的历史意义有价值。
- Jason Wei et al.,《Emergent Abilities of Large Language Models》(2022)—— 涌现能力的经典论文,有大量直观的实验图表。
- Stephen Wolfram,《What Is ChatGPT Doing … and Why Does It Work?》—— 面向非技术人群最好的LLM原理解释之一。